You Only Need 2 Data Validations, That’s It.

I mean, I’m sort of being facetious and sort of not. I mean there is some truth that rings out in those words. I’m sure someone selling Data Observability tools, or writing Great Expectations all-day will not like the idea of relying on only 2 data validations. But honestly, these two are probably more than 80% of Data Teams are using today for validation, which is none. What 2 are you? Glad you asked.
Start Simple My Friend.
I personally think tools like Great Expectations are horribly underused, they just don’t get enough love. Data Teams are probably exhausted by the end of every Sprint, they have Technical Debt backlogs as deep as the great blue sea. Can you really blame anyone for just writing their Data Pipelines, doing some unit tests, and moving on with life?
I mean really, it’s hard enough to find folks unit testing their data transformations.
Do What You Can.
Understandably, once your data hits its final resting place, that’s typically when problems start to arise. A duplicate here, a bad datapoint there, some Data Analyst will dig in and start finding the buggy bugs hiding underneath the covers.

The Only 2 Data Validations You Need To Do.
Yup, there are two data quality issues that have been with us since the dawn of time. By all means, do some Great Expectations or something else, but there are some simple and straightforward data quality checks you can implement in all your data pipelines and transformations that will solve %80 of the issues that arise.
- Volume Monitoring / Counts
- Duplicate Records
Since good ole’ Kimball designed that first Data Warehouse when I was but a small child, to the largest terabyte level Data Lake … these two simple and obvious problems have plagued the Data Engineering world. And they mostly go unaddressed.
Volume Monitoring / Counts

Probably one of the easiest data quality checks you can do on any data warehouse / lake / whatever, is volume monitoring … aka counting your data. Volume monitoring catches all sorts of nature problems that arise in data systems.
- Duplicates
- Bad Joins
- Data Source problems / interruptions
If data sources and transformations require multiple joins, there is always a high likely hood a misunderstanding or bug will cause serious multiplication of records. Sometimes a change to an upstream table used in the join at a later date can cause this problem to appear out of nowhere. Or maybe the upstream data source stops getting updates or new records/files. Volume monitoring catches these very common problems.
The best part about volume monitoring?
There is no easier problem to solve than volume monitoring. This is the type of SQL you learned first. SUM and GROUP BY, that’s pretty much all it takes. Let’s see an example using the free open source Divvy Bike trips data set. Let’s say you have a Data Lake that receives CSV data dumps that are records of individual bike trips, like below. Your data pipelines pump these CSV files into a Delta Lake table(s).
Maybe your DDL would look something like this.
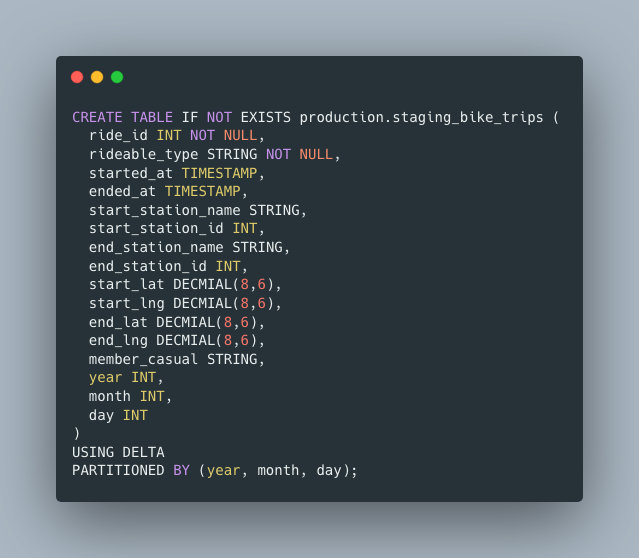
How would we do volume monitoring on such a table? It’s probably the first query you learned to write. What is it they say … elementary my dear Watson.
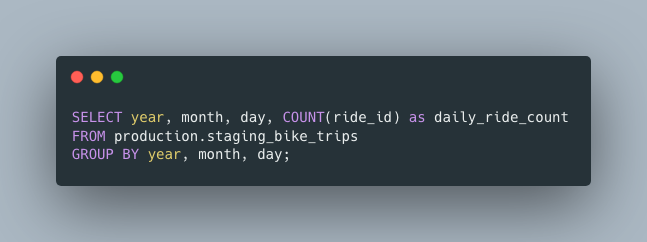
I mean all you have to do is run that query once a day, put it in a chart/dashboard … do it for all your critical data sources. Then you can fire that expensive Data Observability vendor, not really, but maybe. I mean wouldn’t it be wise to do something so simple? Most data teams don’t even take this simple step. Aren’t such simple things powerful? Below is a simple graph sourced from the above query. It’s always the simple things in life that are good for us … and our data.
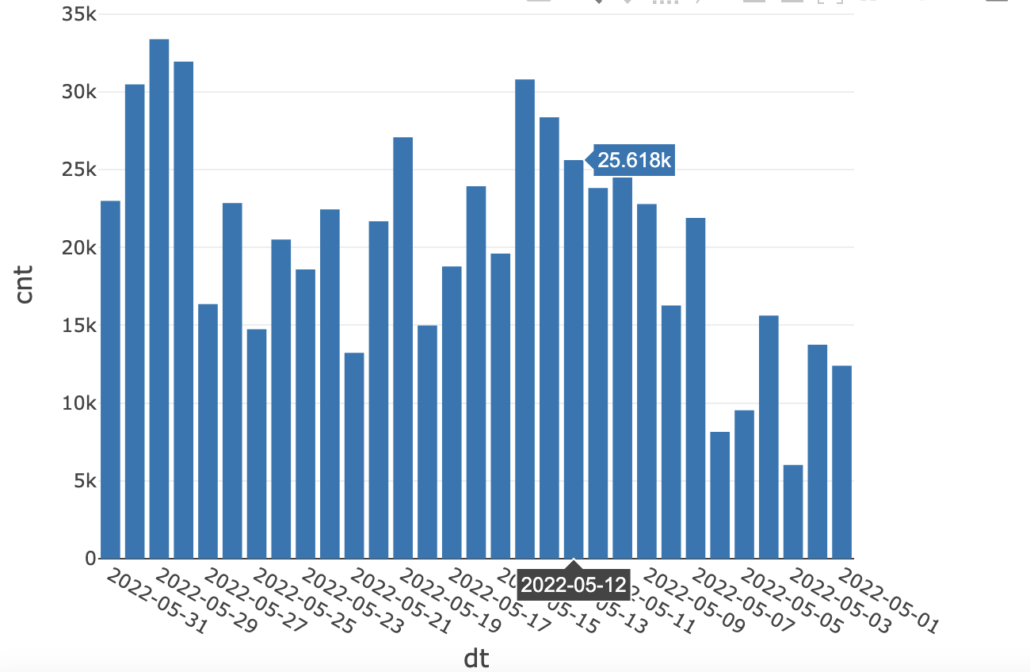
Duplicate Records

Now, some folk might argue that Volume Monitoring would catch duplicate records, and yes, that is true sometimes, but bear with me my friend. Volume monitoring is meant to catch the big issues, the wild and crazy swings in data that come from far distant files being turned on or shut off, things not getting processed … the big whammies.
Duplicate records on the other hand are sneaky and extremely common.
There is a little more nuance in catching them, but catching them requires something important, something that all data folks should do as the very first part of any new data project.
“Thou shalt always identify what makes a record unique.”
– Data Gods
Back in the olden days of SQL Server and Data Warehouses in Postgres this was called a primary_key. There are two types of approaches to generating primary keys for a data set.
- A combination of columns from the data set (composite).
- A unique id is generated by the system.
Honestly, though, the first thing a Data Engineer should do when looking at a new data set is … what makes this row different (or unique) from that row? A simple question but with profound impacts if not done correctly.
What if you have tables with millions and billions of rows? A few duplicate records here or there start to add up, and folks downstream using the data sets generating business analytics for decision-making won’t be very happy with you when those mistakes and duplicates start to show their ugly head. Fortunately, it’s easy to solve this problem.
Solving the duplicate record problem.
Good news for you again, this is an easy problem to keep an eye on and deal with. This is probably the second query you learned. It involves one of those Window Functions everyone is always talking about. Let’s use our trips data set we looked at before, and let’s assume our ride_id is our primary_key, and we want to find any problems or duplicates that might show up. We can easily have a query running daily looking for dups.
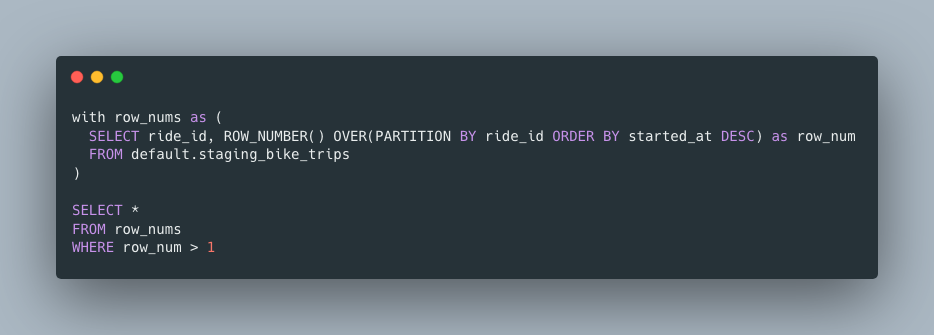
Or maybe.
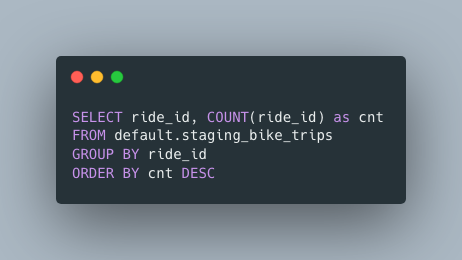
Either way, it’s not rocket science, that’s for sure. Duplicate records are probably one of the most common problems to be found in all sorts of data sets. Having either monitoring or queries embedded in transformations to remove them is a simple step to take, even if you don’t think you suffer from this illness of duplicates.
Musings
I’m still amazed in today’s data world that the most basic Data Quality issues are ignored or sidelined as “not that important.” People just seem to trust the data they work with and on, without question. Really it should be the opposite. Data folks should never trust new data, ever, no matter what anyone says. Things might be “correct’ now, but that might not always be the case in the future.
Data Quality tools like Great Expectations are well worth the investment in time and resources to implement, and most top-tier data teams use such tools. But %80 of small data teams might not have the bandwidth or willpower to take on such big tools or projects. But, I can assume that those same people can write simple SQL statements and make little graphs. Something is better than nothing, and in this case, you get so much from so little code and complexity!
Volume monitoring and duplicates detection are easy, obvious, and will happen to you. Get ahead of the curve.