What makes MLOps so hard? Thoughts for Data Engineers.

It seems like today the problems and challenges of Data Engineering are being solved at a lightning pace. New technologies are coming out all the time that seem to make life a little easier (or harder) while solving age old problems. I feel like Machine Learning Ops (MLOps) is not one of those things. It’s still a hard nut to crack. There have been a smattering of new tools like MLFlow and SeldonCore, as well as the Google Cloud AI Platform and things like AWS Sage Maker, but apparently there is still something missing. Nothing has really gained widespread adoption … and I have some theories why.
What is MLOps all about?
Maybe we should start with what is MLOps. What would I say if I had to sum it up based on my experiences as a data engineer?
“… taking the high level idea and algorithm/model of a scientist and making it a reality … a repeatable, reliable, testable, scalable, approachable … reality.”
– data engineer with a eye twitch
- reality – it’s amazing how many obstacles get in the way of putting a machine learning model into production.
- repeatable – like any code, if you can’t repeat or reproduce a result, you’re sunk.
- reliable – MLOps is complicated, just what you need, a model in production that breaks all the time.
- testable – go ahead … do it … make that change and cross your fingers.
- scalable – if your using Pandas … hahahaha!!
- approachable – if no one can understand or run a ML Pipeline, what good is it?
Based on my experience MLOps for a data engineer is like any other data pipeline they are building, on steroids. There are just a lot more requirements and nuances for MLOps. So that begs the question, what makes MLOps so hard?
What makes MLOps so hard?
It is an interesting questions, and makes you wonder why there isn’t that one tool, like the Spark of big data, why hasn’t that come out for MLOps? Sure, there are popular tools, but there is really no standard in the wild. There must be something different about MLOps. Most people probably think that the DevOp’sy part of MLOps is hard … Docker, automation, etc. Speaking from experience this is not the hard part, all the normal DevOps stuff is usually the straight forward part.
It’s all the not so run of the mill things about Machine Learning that usually try to throw wrenches in your plan. By themselves they don’t seem that hard, but putting them all into one basket is probably the challenge.
Let’s talk MLOps challenges …
scalability and size
Everything we will talk about below happens at the multi terra-byte level, hundreds of terra-bytes is very common. Problems become amplified at scale, there is just less room for error. Just knowing what data you have and its nature is harder when you have terra-bytes of data that is growing. Any data engineer who has worked with Data Scientist knows how much they love data, as much as they can get their grimy hands on.
This is also where architecture and system design come into play. Large codebases that are processing hundreds of TB’s of data are usually complex. Being able to easily and quickly start pipelines and get output within a reasonable timeframe is important. Running random bash scripts on random server’s doesn’t really cut it anymore. Kuberenetes and Spark are the name of the game, with Airflow as your frontend.
model and meta-data management
One of the seemingly easy parts of MLOps turns about to be tracking models, their versions, runs, the metrics, the data used to run those tests … and so on. Making a model approachable and usable means the knowledge surrounding a ML model can’t reside with a single person. Also, people shouldn’t have to spend a day reading code and digging around for files to understand basic information about running a model and what to expect.
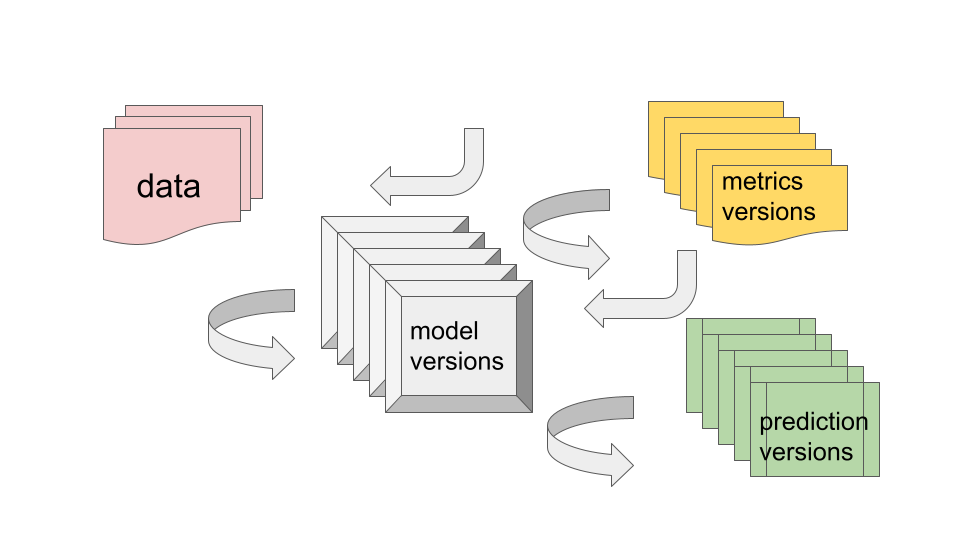
The interdependencies and traceability between model versions, the data used to make predictions and the metrics are basic to the whole MLOps lifecycle. It’s one thing to have a large ML pipeline running in production, it’s another to be able to understand what is happening and why. You will only ever understand “what happened” if you can get your hands around the above problem. ML metadata management is the name of the game.
data science and data engineering integration.
Maybe your team if full of machine learning engineers who are capable of doing everything, but this is usually not the case. One of the greatest challenges of MLOps can be the interaction and smooth, development/transition between data science and data engineering.

Too often the main pipeline code is left to the engineers, the model training and prediction is left to the scientist, and then you end up with something that does not work very well.
Good MLOps depends on a scientist(s) and data engineer(s) working closely together. Unless you have a ML Engineer, the code produced by a scientist should be reviewed and massaged by an engineering to ensure testability, scalability and the like.
approachability
Probably one the biggest hurdles I see in MLOps projects is the general approachability of the codebase and model. This is usually because of the general complexity of data, feature engineering, the model, and output. It can be an overwhelming task for even a seasoned engineer to be dropped into a undocumented, messy, ML pipeline that has no DevOps built into it.
The complexity and dependencies of MLOps requires that a pipeline that is above all approachable.
- DAGs and visualization (Airflow, Dagster, MLflow, Kubeflow)
- functional and testable.
- broken into logical components ( data ingestion, feature generation, model training, prediction, output, metrics)
- scalable and runnable.
- documented
Just because a ML model is “complex” doesn’t mean the MLOps surrounding it has to be black box as well.
reality
MLOps is hard because once you try to put a system in place around a ML model, the reality starts to set in. The whole point of MLOps is to make some ML model lifecycle productionized and hardened, ready for the real world without someone constantly babysitting.
Putting these guardrails around the system always bring the rocks up out of the water.
- tests will always show you over complex and error prone code.
- DAGs will show you the critical dependencies and complexities, some of which may be out of your control.
- surfacing data/model/feature/metric versions and runs will force rigid structure and meta data management onto your pipeline.
- clicking the same run button and getting the same output from the same input requires an incredible attention to detail and automation of every single piece of code.
Musings on MLOps
I think MLOps is hard because in the world of Data Science and Big Data Engineering there is a lot of fast past development. The knowledge to make the perfect ML Pipeline is with two different groups, the DS and DE, and they have to work in unison to make it work. The data engineering world has long lagged behind the software engineering world in terms of good coding practices…. tests, docs, devops.
It’s obvious that the MLOps and data engineering universe requires certain skills and knowledge that are not generally found in the software engineering world. But, it’s also clear that the more software engineering principals and practices that are pulled over into this data engineering and ML world the more likely it is that MLOps and ML pipeline will succeed in the real production world.
MLOps is hard because if you skip all the “boring” software engineering practices it will come back to haunt you in the end.
Thank you for the article. Very helpful.