Using Rust to write a Data Pipeline. Thoughts. Musings.

Rust has been on my mind a lot lately, probably because of Data Engineering boredom, watching Spark clusters chug along like some medieval farm worker endlessly trudging through the muck and mire of life. Maybe Rust has breathed some life back into my stagnant soul, reminding me there is a big world out there, full of new and beautiful things to explore, just waiting for me.
I’ve written some Rust a little here and there, but I’ve been meditating on what it would look like to write an entire pipeline in Rust, one that would normally be written in Python. Would it be worthwhile? The cognitive overburden of solving problems in Rust is not anything to ignore. Rust is great for building tools like DataFusion, Polars, or delta-rs that can be the backbone of other data systems … but for everyday Data Engineering pipeline use? I have my doubts.
An average data pipeline with an above-average language. Rust.
I want to see what it’s like to write an entire data pipeline with Rust, the whole thing. I want to try and incorporate a few things and just get a feel for what the whole process is like. I still don’t think the future will ever be Data Engineers writing data pipelines in Rust, it isn’t going to happen. You will never rip Python from the cold dead hands of most Data Teams.
“I do think that in the future we will see more data processing tools that Data Engineers built using Rust, with the majority of people using the Python bindings that will undoubtedly be used in lieu of native Rust code.”
– me
Here are some of the things I want to do when working on this small data pipeline project.
- Set up a project with Dockerfile with all requirements.
- Download some compressed data files from over the wire.
- Uncompress/extract files.
- Process/transform data.
- Write data to Postgres.
Time to blow this popsicle stand.
Rust … for a data pipeline.
All the following terrible Rust code is available on GitHub.
First, things first, most folks might want a Dockerfile that has Rust. Fortunately, Rust has an official Docker image you can probably use as a base, adding in anything else you need. Little bugger has Python installed as well, how nice of them.
docker pull rustWhat’s the big idea? I want to do something with Rust that is a little awkward, kinda like a normal data pipeline crap that gets thrown our way, nothing ever comes easy. In this case, we will use the Backblaze Hard Drive data set. Here are the steps I envision.
- Download zip files over the wire.
- Unpack the zip files to get the CSVs.
- Gather local files from the file system.
- Read data.
- Write data into Postgres.
I know it’s all over the place, but that’s the idea, touch a little bit of everything. Downloading files, unpacking them, reading them, working on a file system, and writing data to a Postgres database. I mean if that doesn’t give us a good idea of what it’s like to write a data pipeline in Rust, nothing will. Let’s get to it, and I will make my typically cynical observations along the way.
Let’s be honest, I’ve barely written any Rust at all, just a few times. I’m taking a class, but I’m pretty much pre-beginner phase, so this exercise should provide me with some good learning and struggle.
Rust … what I’m going to learn … or poke at.
I listed the above steps that we will look to take for our baby Rust data pipeline. But underneath each one of those steps is Rust code that I’ve never written before. I’m still a Rust newbie, actively learning, so, therefore, I mostly don’t know what I’m doing. Either way, here are some topics I hope to hit in Rust.
Doing so many things gives me a general feeling about Rust, how easy or not easy it is to do certain tasks, and helps me understand when I would use Rust to do something, if it’s worth it, vs using some simple Python.
- Make simple HTTP calls to download content.
- Mess with ZIP files, extracting them.
- Mess with the file system, writing to files, messing with directories, etc.
- Interacting with data via Rust crates.
- Write data to Postgres.
These are all practical Rust steps that I would have to do at some point if using Rust on a daily basis for Data Engineering tasks. I’m trying to find out … is it even feasible to do so? Is Rust made for more low-level programming, good for building the backbone of systems, and terrible at everyday tasks? I want to find out.
Starting out with HTTP and file downloads.
So, it turns out Rust has a great crate for working with HTTP called reqwest. It turned out to be straightforward to use and should be familiar to anyone used to working with packages like requests in Python.
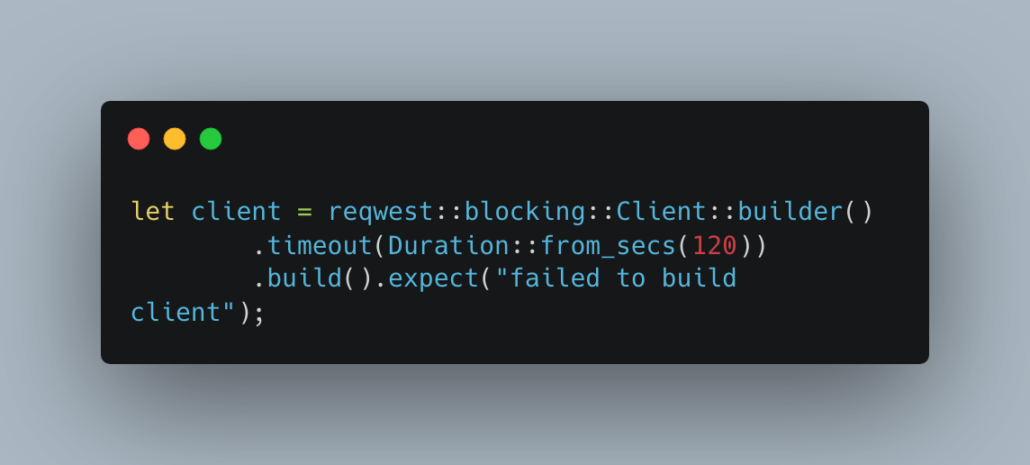
I mean that doesn’t look bad right? Here is the function I wrote to download my files. Basically iterating through a few “quarters” and downloading those specific zip files. I’m very surprised at how easy it is to work with HTTP in Rust, from my research the have some nice parallel async options as well ( you can see I’m using the easier blocking Client below).
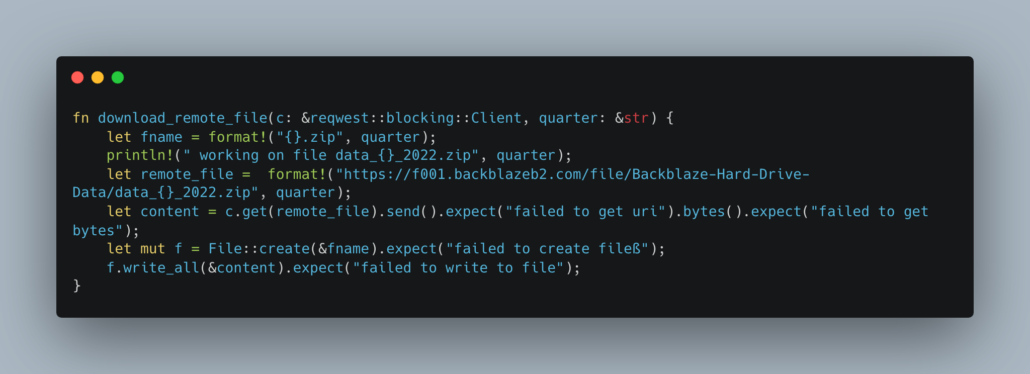
File Systems …
You know, the next part is what I was dreading the most, and I wasn’t wrong. Working with files, directories, and the like, for some reason can be a little finicky, especially when you’re new to something like Rust. It turned out to be the ugliest piece of Rust I’ve ever written, which isn’t saying much.
This little blighter works through 3 different ZIP files, unpacking the CSV’s into different directories based on what quarter is being worked on.
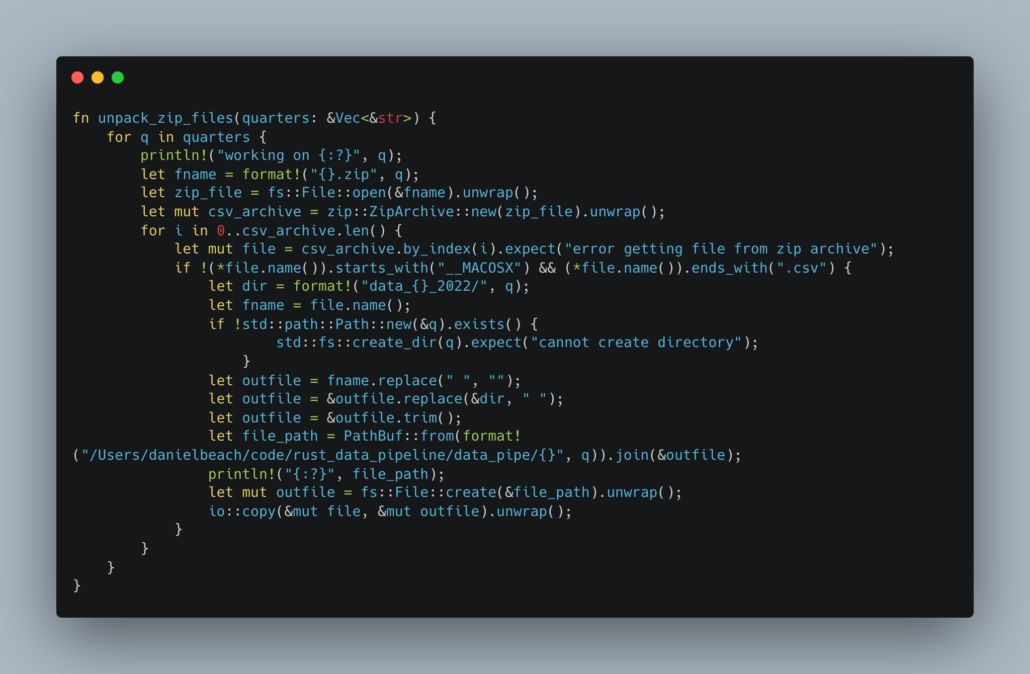
Funny thing is, I didn’t find the Zip file stuff or working with files particularly hard. Things like create_dir, file.name(), PathBuf::from(), io::copy() seem very easy to work with and understand once you find the right features you are looking for.
It was actually combining that File System work with Strings and doing funny stuff with strings in this world of Rust where Ownership is the thing that keeps tripping me up. Someday when I’ve been writing Rust for more than a few months I will return and fix that beast.
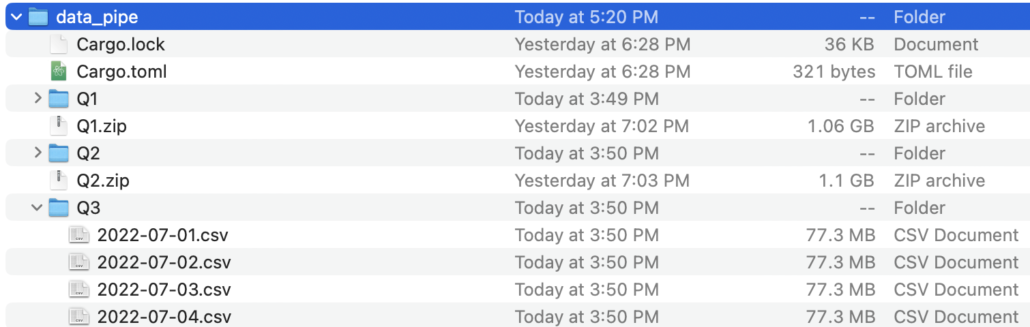
By some miracle of these wonderful cold winter days, the code seemed to be working so far, below you can see the zip files, the quarter directories, and the files unpacked beneath.
Ok, so we have the data, now what?
So now that we have all these CSV files, it’s time to read and try to insert those records into Postgres using the popular crate. I’m not going to try to do this in the most performant way, I’m just curious to touch things in Rust that I haven’t yet.
There are two ways to pull this sort of CSV to Postgres off, I’ve used both in the past with different languages and it kinda depends on the data etc. One way is to iterate the rows and batch them in, row by row or otherwise, the second is to use the COPY functions that Postgres provides, which are usually a litter faster. But I’m new to Rust so I will just iterate and insert each record into Postgres one by one. Good learning.
If you use Docker to pull down Postgres , run the following command to get a default local Postgres database running.
docker run --name postgres -p 5432:5432 -e POSTGRES_PASSWORD=postgres -d postgres
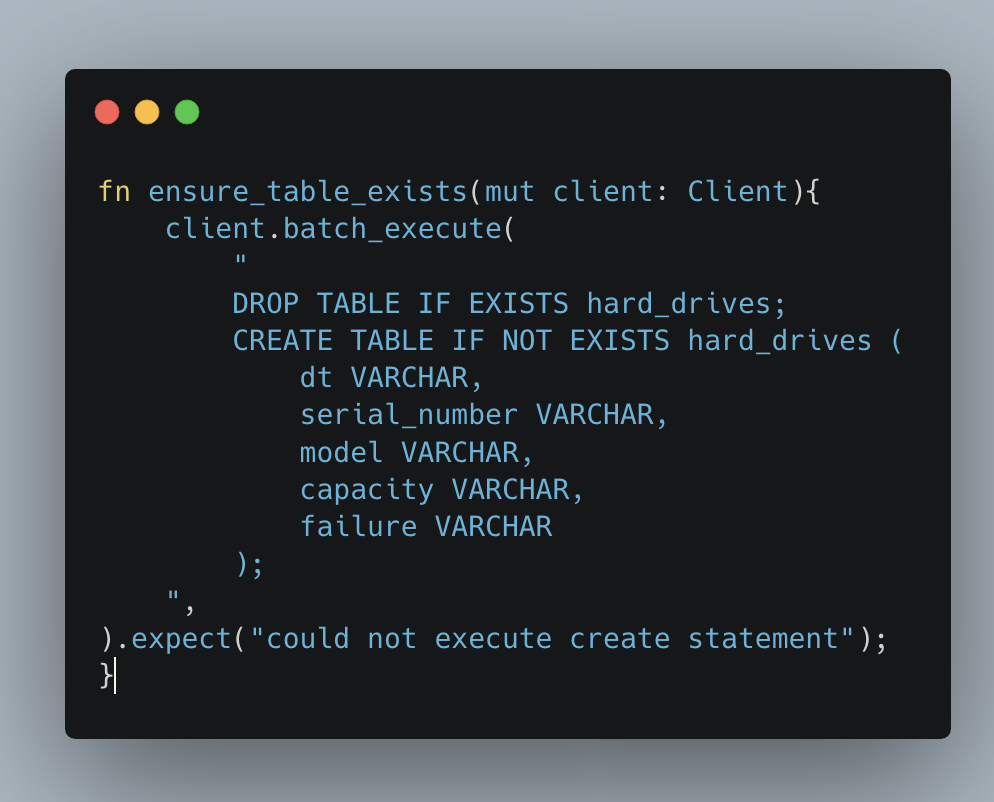
First I will ensure a Postgres table exists for my data.
Then we will find all the local CSV files and read them.
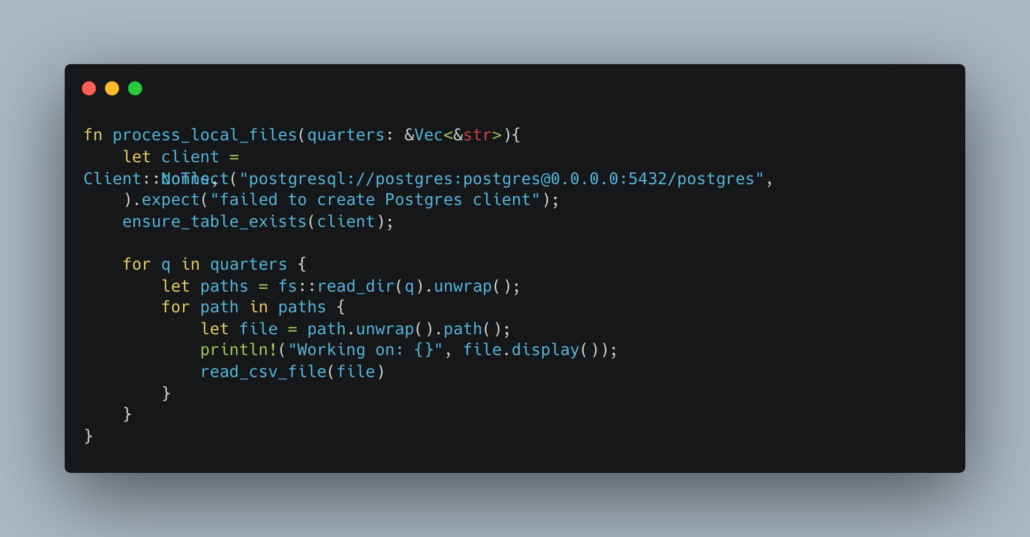
Above, we create a Postgres client to connect to our local Docker Postgres, and then loop through the quarters, picking up all the files in that directory. This again was way easier than I expected with Rust, it’s straight forward and not a bunch of crappy code to connect to a database. It isn’t any more work than doing it with Python really.
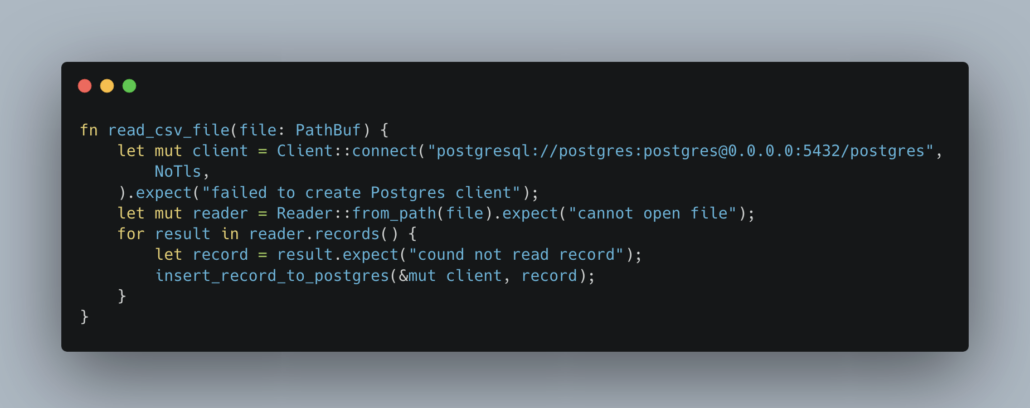
Next, we will read each CSV file and get each record that needs to be inserted into Postgres.
Here is the function to insert into the Postgres Table.
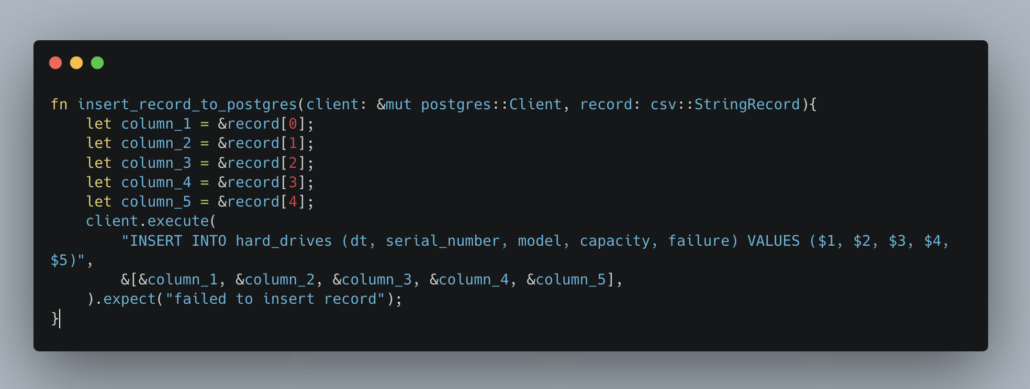
Not too bad eh, better than I expected. Remember, all this code is available on GitHub.
General thoughts on Rust for Data Engineering.
You know, it went better than I expected. Especially for someone like me who has only written about 3 Rust scripts in my entire life. I do have to say, it was not the result I was expecting. I fully intended to find out Rust would be a horrible choice to do normal Data Engineering tasks like HTTP, File Systems, Database calls, etc.
I found the opposite. There was nothing overall complex about any of the code, not tons of boilerplate crud that I expected to encounter with talking with Postgres or getting a file over the wire.
I’m I convinced to throw Python to the trash heap for the mundane Data Engineering tasks and switch to Rust? No. Python’s development and iteration lifecycle is way too easy, you can’t just walk away from that. Is Rust easy to use, easier than most people think, and capable of replacing other code for everyday tasks? Yes.
I’m glad I tried this fun little project out with Rust. I learned I need to learn more about Rust, and that as more people discover what I just did … that it’s fairly easy to use pickup and use … it’s adoption is going to increase in the Data Engineering community.
I really enjoyed this article. Keep on pursuing those little intrusive thoughts!
Hi! You might find interesting this apache project: Datafusion – https://arrow.apache.org/datafusion/
You can basically load up files like CSV, Parquet, Avro and NDJSON and query them using SQL.