
Using DuckDB to read JSON files in S3
I’ve been playing around more and more lately with DuckDB. It’s a popular SQL-based tool that is lightweight and easy to use, probably one of the easiest tools to install and use. I mean, who doesn’t know how to pip install something and write SQL? Probably the very first thing you learn when cutting your teeth on programming when you’re wet behind the ears.
I was thinking about some “normal” things I’ve found myself doing over the years—boring, run-of-the-mill tasks that I could try out with DuckDB. At several different points in my life, I’ve had to process large datasets consisting of JSON files stored in the cloud, S3, of course.
Using DuckDB to process JSON files in S3.
I was curious if this SQL-based tool, DuckDB, could handle JSON files. I have to admit that DuckDB has some of the best and most wide-ranging integrations of any data tool I’ve seen for a long time; it can do everything.
DuckDB did not disappoint.

It has a wonderful method called read_json of course.
I found some open-source data in JSON format and wrote a query to test it myself. The code is clean and boring, we are able to run SQL on a JSON file in S3 with DuckDB with just a few lines of code!
You can see the full code in GitHub here.
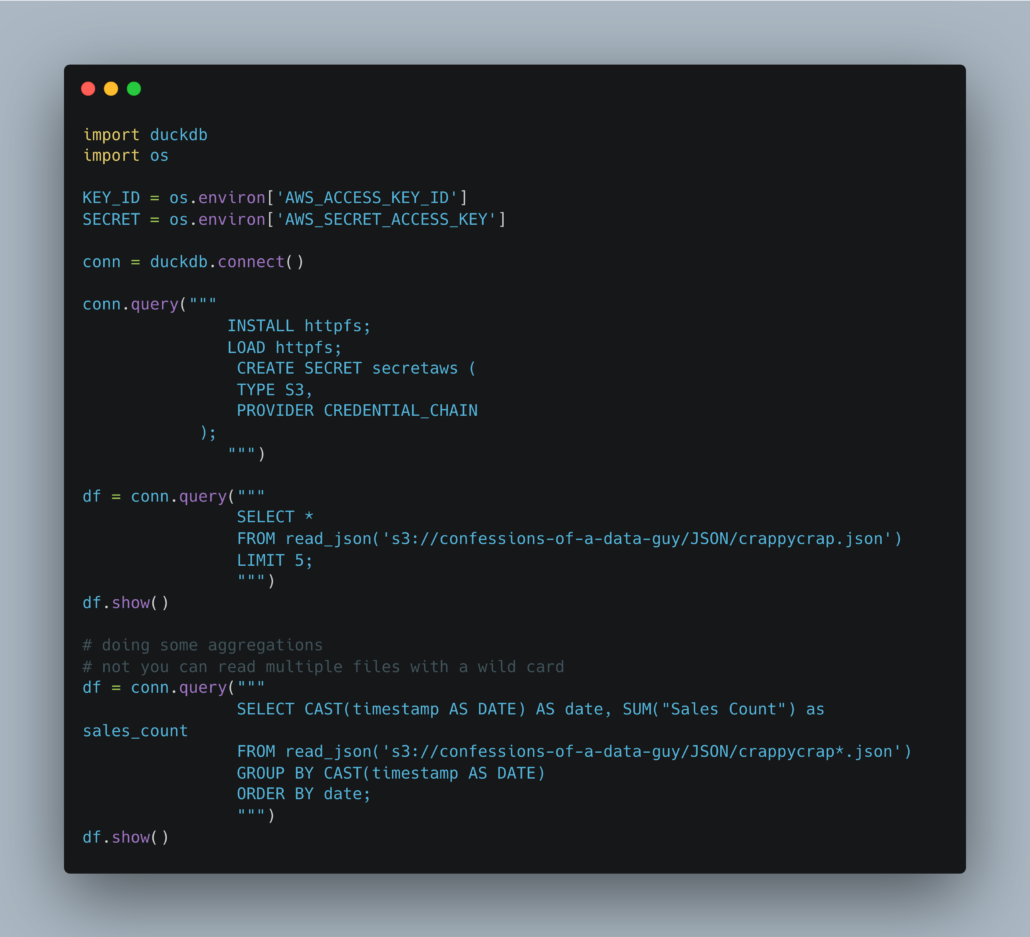
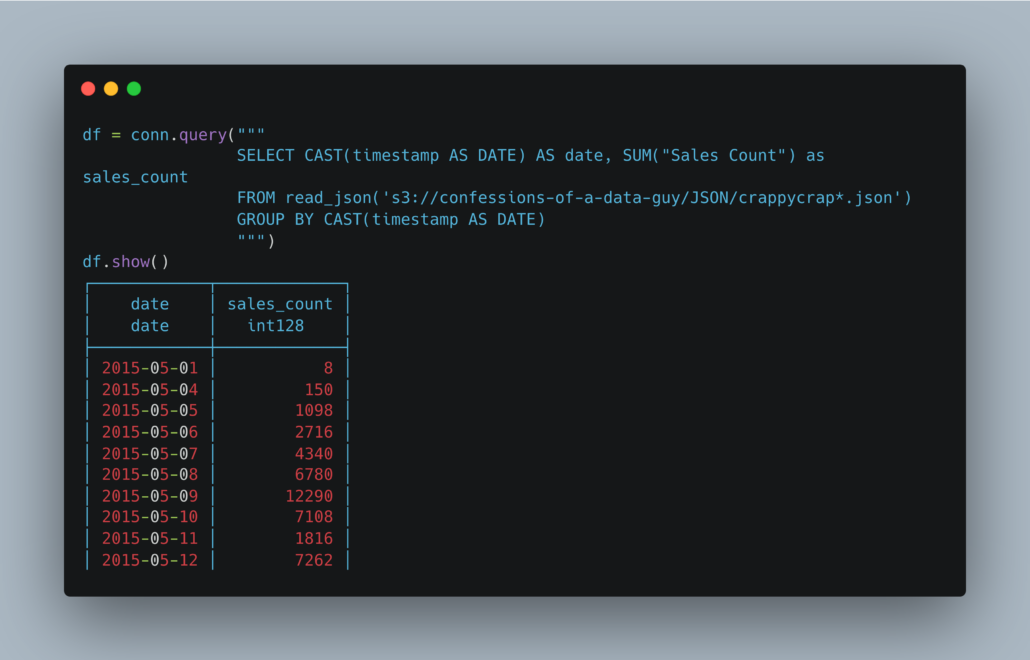
What an incredible little tool DuckDB is.
Most people, including myself in the past, would have written some giant pipeline to read and transform that JSON data into another format and stored it off somewhere else for downstream processing. It’s simply amazing the way new tools like DuckDB are making our lives easier and easier, abstracting away so many problems from the “good ole’ days.”
We should learn to appreciate the small things in life and code, the fact that you can point DuckDB at a remote set of JSON files and write SQL directly on them. Dang!
