
The Role of DevOps and CI/CD in Data Engineering
In the vast world of data, it’s not just about gathering and analyzing information anymore; it’s also about ensuring that data pipelines, processes, and platforms run seamlessly and efficiently. Nothing screams “why are flying by night,” than coming into a Data Team only to find no tests, no docs, no deployments, no Docker, no nothing. Just a mess and tangle of code and outdated processes, with no real way to understand how to get code from dev to production … without taking down the system.
This is where the principles of DevOps and Continuous Integration/Continuous Deployment (CI/CD) come into play, especially in the realm of data engineering. Let’s dive into the importance of these practices and how they’ve become indispensable in modern data engineering workflows.
DevOps in Data Engineering
DevOps, a combination of ‘Development’ and ‘Operations’, emphasizes collaboration between software developers and operations with the goal of automating and optimizing system deployment and infrastructure changes, as well as the best practices around software development in general. This of course can vary widely depending on the type and size of business you are working in. I’ve worked in larger corporate environments, as well as many small startups. It’s been all over the board.
Honestly, you can get as fancy as you want, and I’m sure DataOps and DevOps folks have strong opinions, but what it really boils down to in Data Engineering is …
- Managing infrastructure and Architecture (tools you are using, and their interaction)
- Making deployment of code to different environments easy and seamless.
- Making the Development experience easy and low friction.
- Tests
- Linters/Formatters
- Other domain-specific functions.
- Reducing manual intervention required outside of actually writing code.
This is one of those weird topics where every place does it a little differently. No one can agree on what exactly makes up CI/CD and DevOps. But, I think maybe if we just look at some super simple ideas, maybe you can find one or two that might be useful for you to apply yourselves.
![]()
Some simple examples.
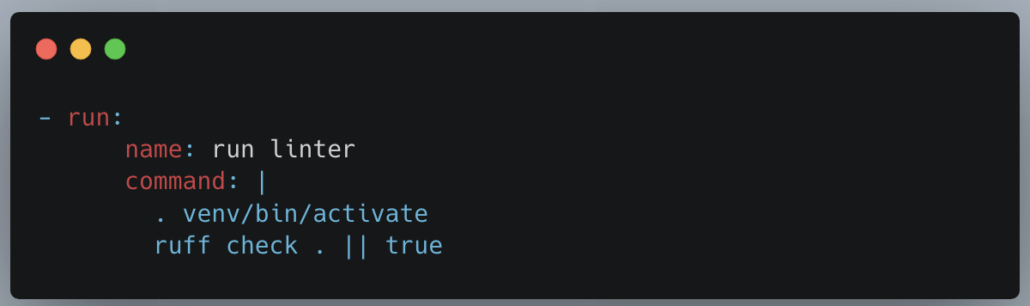
One of the most basic things you do in a DevOp context, without a lot of work or complexity, is simply keeping your code formatted and linted. Keeping things uniform in a codebase can be a big and very simple win. It gives Data Teams a taste of what it’s like to start a DevOps journey.
By auto-formatting with a tool like black, and linting with a tool like ruff, you can take a step forward toward best practices. Most teams are using some sort of git tool, so setting up some .githooks or using tools like CircleCI can automate this process of running formatters and linters as part of the build and deploy process.
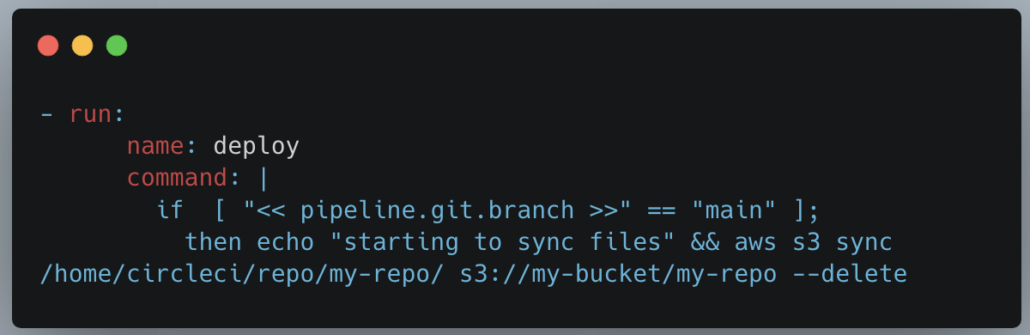
What else? Well, I guess it would not be uncommon to have files and packages hosted on s3 that might need to be deployed when code goes into main or something of that nature.
I mean it’s really about trying to automate everything, make mistakes harder to happen, and reduce any manual steps taken by developers.
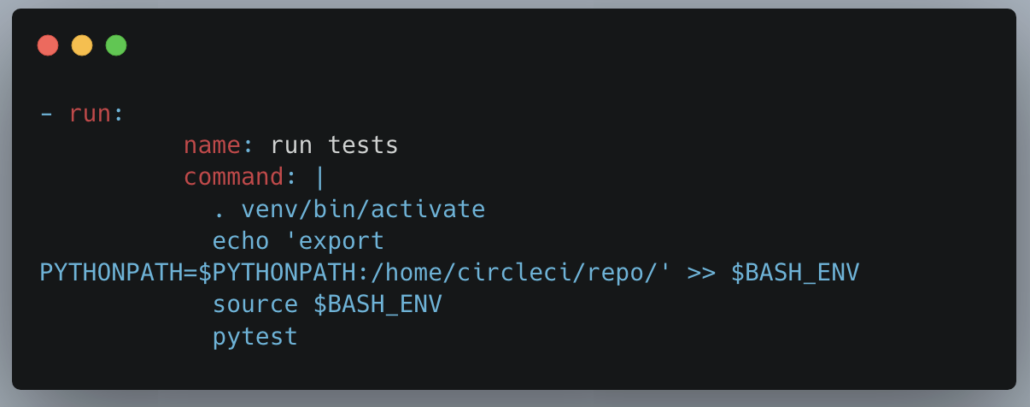
Tests are another big part of CI/CD and DevOps, It’s always wise to run tests automatically because … we forget, we get in a hurry, etc. Make it automatic.
Bash is always a helpful tool as well. It can automate things like packaging and deploying lambdas, zip up libraries, push local code out to Development environments for easier testing.
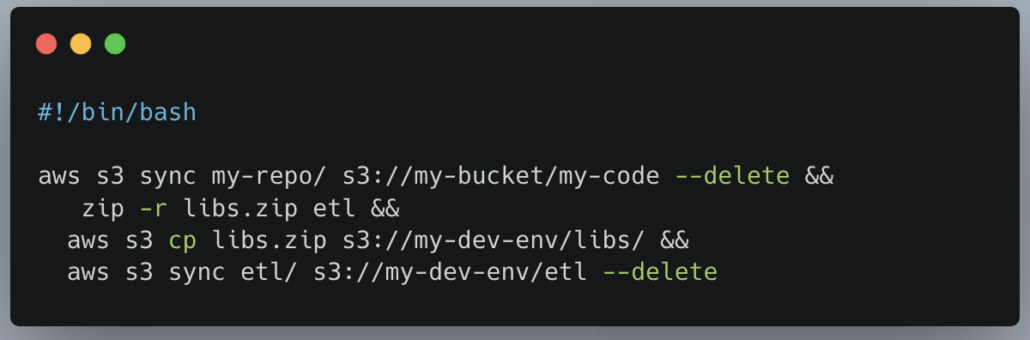
Making it easy to deploy things to Development so Engineers can test easier is a great and easy win.
I would say some of the above things are just ways for Data Engineers to start dipping their toes in the water of automation and better development practices. They don’t take any real effort and can be implemented without much complaint or problems with just a little below grease.
Of course, there are ways to drink the Kool-Aid and go down the rabbit hole of things like IaC until you have to hire a team of Platform Engineers just to manage and keep up with all the “time-saving” beautiful infrastructure you’ve built around everything. Insert my eye-roll here.
But, to each their own.
Infrastructure as Code (IaC):
Data engineers often utilize cloud resources like Amazon AWS, Google Cloud, or Microsoft Azure. By treating infrastructure setup as code, data engineers can recreate consistent and reproducible environments, which is essential for reliable data processing.
Using tools like CloudFormation and others allows for the automation of mundane tasks, but it’s the author’s opinion that this can easily get out of hand and so complex it turns into multiple full-time jobs, at which point how things are being done should be re-evaluated.
Monitoring and Logging:
An essential aspect of DevOps is proactive monitoring. By continuously monitoring data pipelines and infrastructure, engineers can promptly identify and address performance bottlenecks or failures, ensuring data’s reliability and availability.
The problem of Alerting, Monitoring, and Logging in a way that is actually usable and easy to use is actually a lot harder problem than most people think. Often times it’s an afterthought of many Data Teams and Data Engineer’s pipelines, and is such a wide-ranging need, that it can fall into the bucket of DevOps, mostly because there is no better place to put it.
It is true that good logging and monitoring and make teams way more efficient and finding and solving bugs and problems in Production, and before they happen as well, and should not be overlooked.
Wrapping Up
The world of data engineering is complex and ever-evolving. With the integration of DevOps and CI/CD practices, data engineers can ensure they’re delivering optimal, reliable, and efficient data platforms and pipelines. This not only boosts the performance of data-driven tasks but also facilitates a culture of collaboration, automation, and continuous improvement. As the demand for real-time data insights grows, the synergy of data engineering with DevOps and CI/CD will only become more vital.
