Solving the Memory Hungry Pandas Concat Problem.

One of the greatest tools in Python is Pandas. It can read about any file format, gives you a nice data frame to play with, and provides many wonderful SQL like features for playing with data. The only problem is that Pandas is a terrible memory hog. Especially when it comes to concatenating groups of data/data frames together (stacking/combing data). Just google “pandas concat memory issues” and you will see what I mean. Basically what it comes down to is that Pandas becomes quickly useless for anyone wanting to work on “big data” unless you want to spend $$$ on some machines in the cloud with tons-o-ram.
Below is an affiliate link, I receive compensation if you buy 🙂
Learning Pandas? Read this book.
Are the pd.concat() issues really that bad? Yes.
Let’s download a few small Divy trips open source csv files. I got 4 files for myself, totaling 783 MB.
Here is simple bit of Python that will read in the files, and concat them (stack them on-top of each other). This is a very common data engineering type task. Except you most likely will have hundreds/thousands of files, not 4.
from datetime import datetime
import pandas as pd
import glob
from memory_profiler import profile
def pandas_csvs_to_dataframes(files: iter) -> iter:
for file in files:
df = pd.read_csv(file, skiprows=[0])
yield df
@profile
def concat_dataframes(dfs: iter) -> object:
df_list = [df for df in dfs]
t1 = datetime.now()
main_df = pd.concat(df_list, axis=0, sort=False)
t2 = datetime.now()
total = t2-t1
print(f'took {total} to pandas concat')
return main_df
if __name__ == '__main__':
t1 = datetime.now()
files = glob.glob('*.csv')
dfs = pandas_csvs_to_dataframes(files)
main_df = concat_dataframes(dfs)
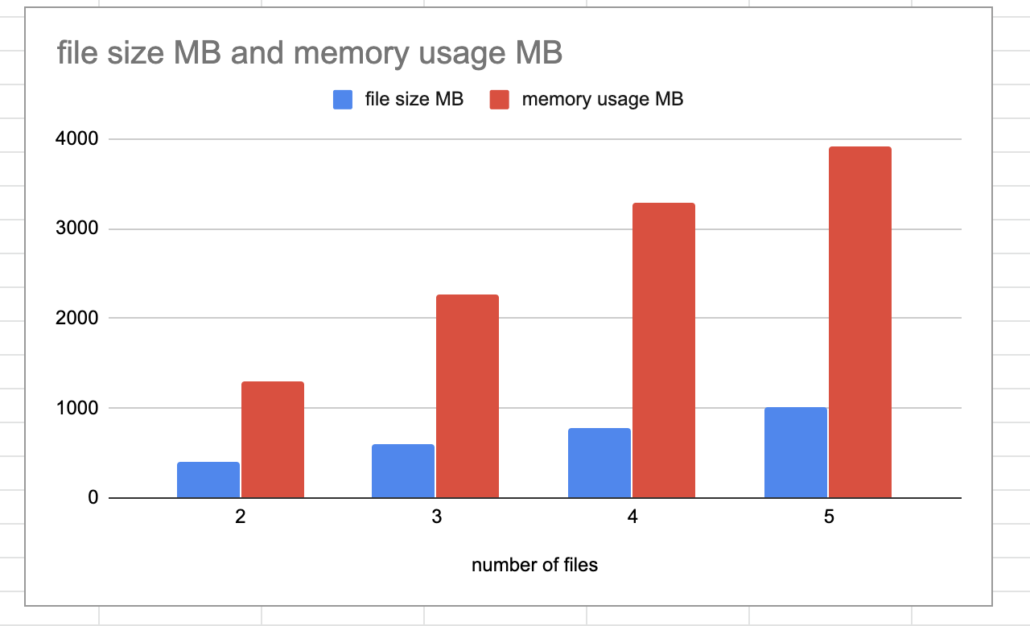
print(main_df.head())What about memory issues? Over 3 GB of memory was used for 731 MB of data. Wow, now you can see why everyone complains about trying to concat even medium sized datasets… it just isn’t feasible. I also decided to profile the memory on the pd.concat() while adding files, it’s troubling as it appears the more files I add the memory usage increasing at a higher rate. No bueno.
How to solve the pd.concat() memory issues
Is there an answer that doesn’t require blowing up memory? Don’t use pd.concat(). Find another way to combine your data. If you still want to use Pandas but can’t get past the concat memory issues there is an answer….write to disk. Parquets are a good option because the are compact and have first class support via Pandas.
Let’s try a solution where we try to stream our csv files in, and use pyarrow to stream them back into a single parquet file, so we can easily grab that parquet file back into a pandas data frame using pd.read_parquet().
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import glob
from memory_profiler import profile
from datetime import datetime
@profile()
def csv_to_parquet(files: iter) -> None:
chunksize = 1000000 # this is the number of lines
t1 = datetime.now()
pqwriter = None
for file in files:
for i, df in enumerate(pd.read_csv(file, chunksize=chunksize)):
table = pa.Table.from_pandas(df)
# for the first chunk of records
if i == 0:
# create a parquet write object giving it an output file
pqwriter = pq.ParquetWriter('combined.parquet', table.schema)
pqwriter.write_table(table)
if pqwriter:
pqwriter.close()
t2 = datetime.now()
total = t2 - t1
print(f'took {total} to pandas concat')
if __name__ == '__main__':
files = glob.glob('*.csv')
csv_to_parquet(files)
main_df = pd.read_parquet('combined.parquet')
print(main_df.head())It also appears we get 502MB max during this code run. This is around 17% of the memory usage of pd.concat().
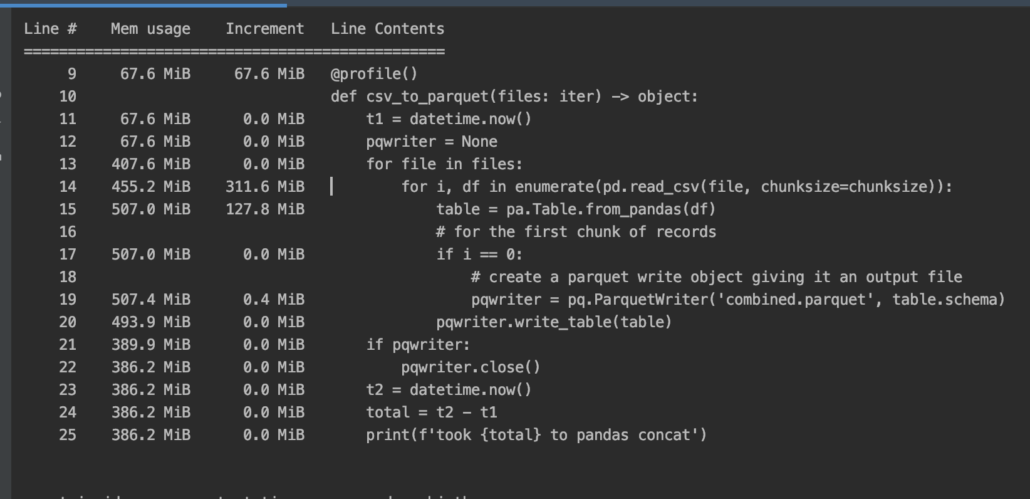
The unfortunate part is that the pyarrow parquet concat appears to take almost twice the time of pd.concat(), no surprise there… memory is always faster than disk. But, when dealing with large datasets sometimes you need to be able to keep memory usage down to a reasonable consumption rate. There are probably tweaks we could make to the pyarrow code to squeeze some more time out of it, possible multiprocessing/multithreading and messing with the chunksize we are reading with.
Conclusion
It is possible to beat the memory hungry pd.concat(), you just have to be creative. This is probably one of many ways to keep memory usage down, but the nice thing about this solution is that it doesn’t deviate too much from the Pandas concat, and wouldn’t require a whole different solution set or code re-write. It’s just a little addition to help Pandas along!