Simplify Delta Lake Complexity with mack.

Anyone who’s been roaming around the forest of Data Engineering has probably run into many of the newish tools that have been growing rapidly around the concepts of Data Warehouses, Data Lakes, and Lake Houses … the merging of the old relational database functionality with TB and PB level cloud-based file storage systems. Tools like Delta Lake, lakeFS, Hudi, and the like.
Sure, these tools have been around for some time, but the uptake and adoption of them all have been rapidly growing. I use Delta Lake on a daily basis, taking advantage of the many wonderful features it provides to simplify and reduce complexity in data pipelines. But, I’ve been sitting around for a long time waiting for the plethora of “add-on” tooling to come out, stuff that will make my life easier. I recently saw one of the first tools like that for Delta Lake, namely mack.
Mack appears to have the ability to “do the hard work for you,” a concept that appears to be growing in popularity, but which I have a fraught relationship with. Double-edged sword? Let’s find out.
Thoughts on complexity, and its reduction.
Before jumping into the Python package mack, and how it can help with Delta Lake workloads, I want to take a moment to give a word of caution, the dude on the corner holding a sign saying the end is near. Ok, maybe not that dramatic, but you know. I have spent much of my career and energy, and I credit some of my success, to the idea of complexity reduction.
When all the other Data Engineering lemmings are running around trying to prove how smart they are, a gift to us all, I’ve taken the other tract. I see it as the pinnacle of what anyone writing software should do, reduce complexity. But, it’s a hard one to solve right? Some complexity can only be hidden and shuffled around, some complexity is needed. But, at the end of the day, you and I should strive to make our code and designs simple and straightforward to use, reason about, and debug.
So, just keep in mind these few points.
- If you use some tool to hide complexity, realize it’s dangerous if you don’t know what’s happening and something goes wrong. Because it will.
- Complexity reduction in the right spot, at the right time, is amazing for productivity.
- Don’t be afraid to look at something complex and say … “something is wrong here.”
Delta Lake and the mundane tasks.
Since we are going to be talking about mack today, and how it can save us time, and reduce the complexity of our code, let’s talk about the mundane Data Engineering tasks we all work on every day.
It doesn’t matter what systems we are working on, Data Engineers are utterly familiar with a few of the following tasks, tasks they do with much regularity.
- SCD (Slowly Changing Dimension) logic and management.
- Dealing with duplicate data.
- Copying data around.
- Identify uniqueness (primary key stuff)
Doesn’t matter if you’re a fancy Delta Lake user or Postgres, pretty sure you’re doing this stuff on and off most of your data career. That’s what the new mack library is trying to do. Obfuscate and do that boring work for you.
Introducing mack, trying it out.
We are going to jump straight to it. Let’s talk mack.
“mack provides a variety of helper methods that make it easy for you to perform common Delta Lake operations.”
Well, that’s straight and to the point, nothing left but to try it out. First things first, let’s make a Dockerfile that has Spark, Delta Lake, and mack installed.
Installing mack is as easy as pip install mack … almost. One thing of note I found. If you don’t have the Python package delta-spark already installed, mack will pip install correctly, but upon import will puke.
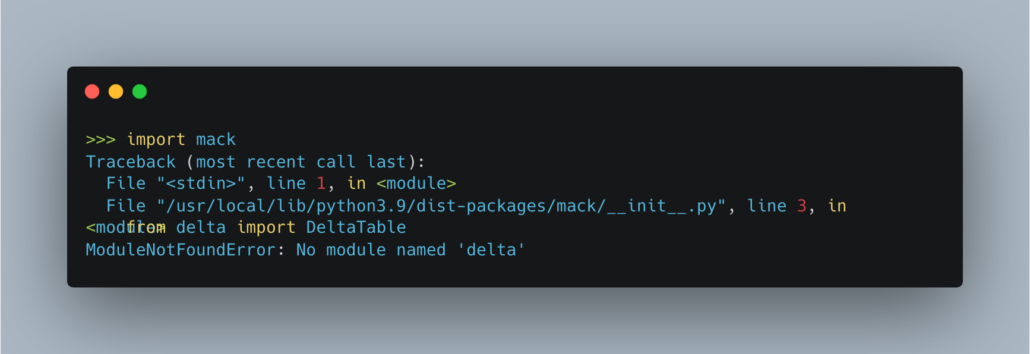
A simple pip install delta-spark will solve this problem, although I find it strange that the mack package wouldn’t complain about the installation that it needs, and depends upon that package, as it obviously would. Also, a side note, mack requires Python 3.9 or above, so all you Python 3.8 folks are gonna have to get with it.
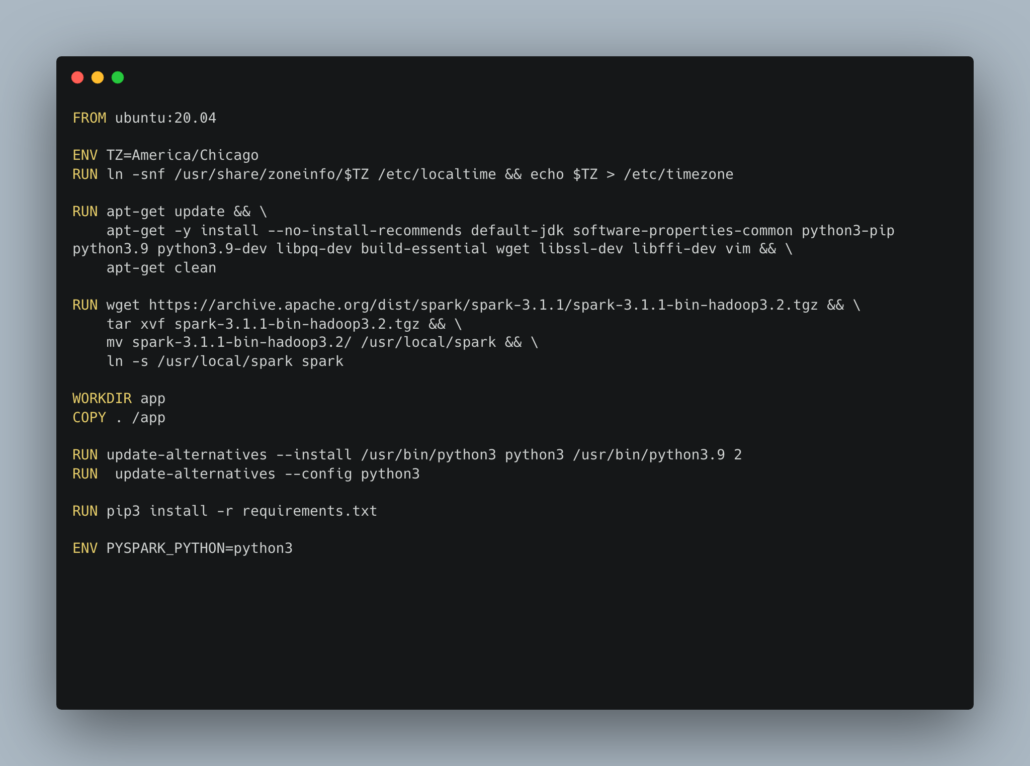
Either way, since I’m such a kind soul, I’ve put together a Dockerfile that has Spark, mack, delta , and everything you need. All code and files can be found on GitHub.
Here is the Dockerfile.
We will use the Backblaze Hard Drive failure data set. Let’s create a Delta Lake table with some of the data. First things first, here is the basic outline of our Spark script, without any mack stuff yet. Just read some data and get some into a Delta table so we can start playing with mack.
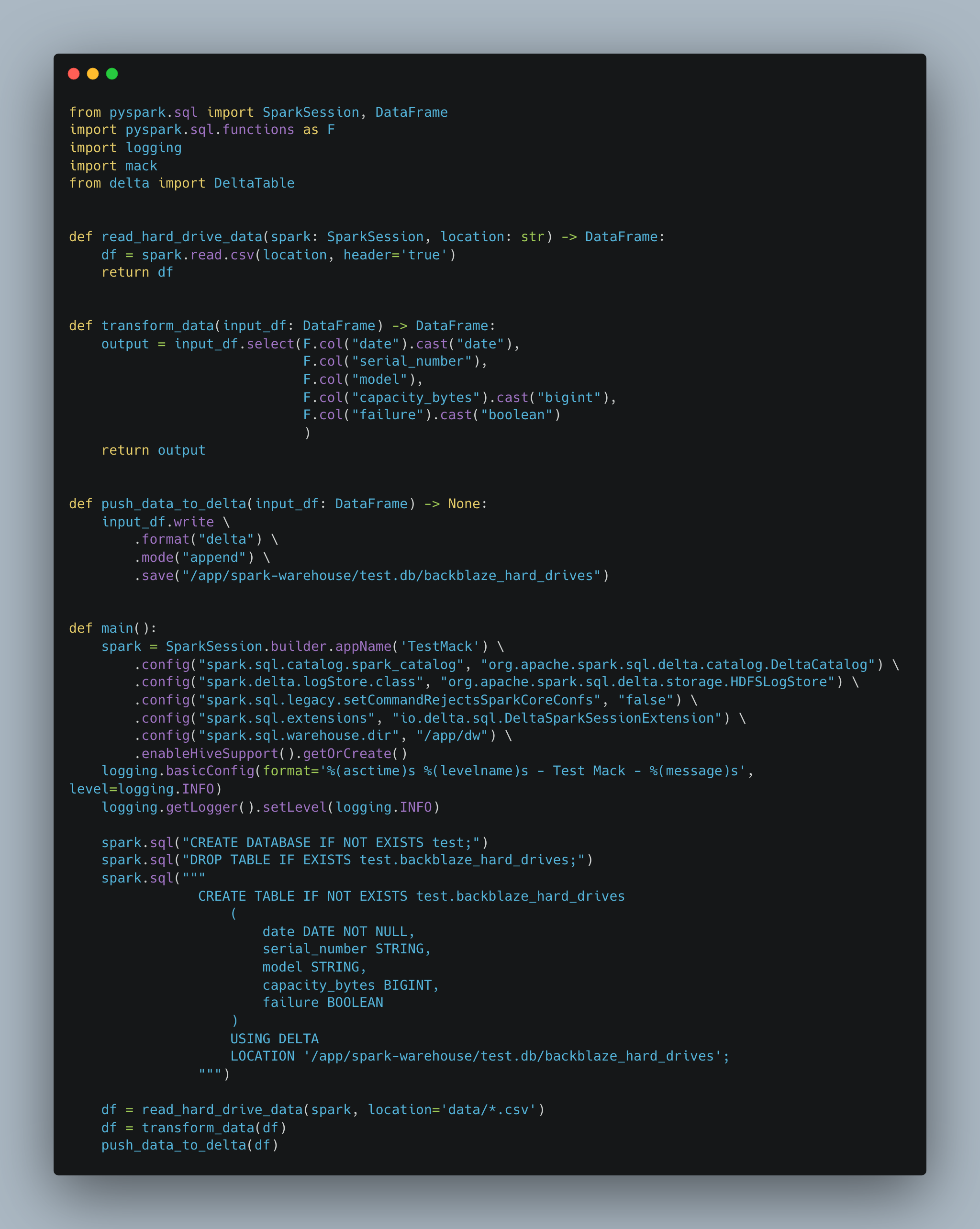
So the above code isn’t fancy, just some basic read data, transform it, and write it. The idea is to get something basic so we can actually try out mack, which we should probably just get to already.
mack!
Ok, so we can finally start trying out this mack with Delta Lake, maybe it will make our life easier, we shall see. At this point, I just want to see it in action, and see if it’s worth using or not. Should we do stuff ourselves or offload it away, to give the illusion of complexity reduction?
kill_duplicate
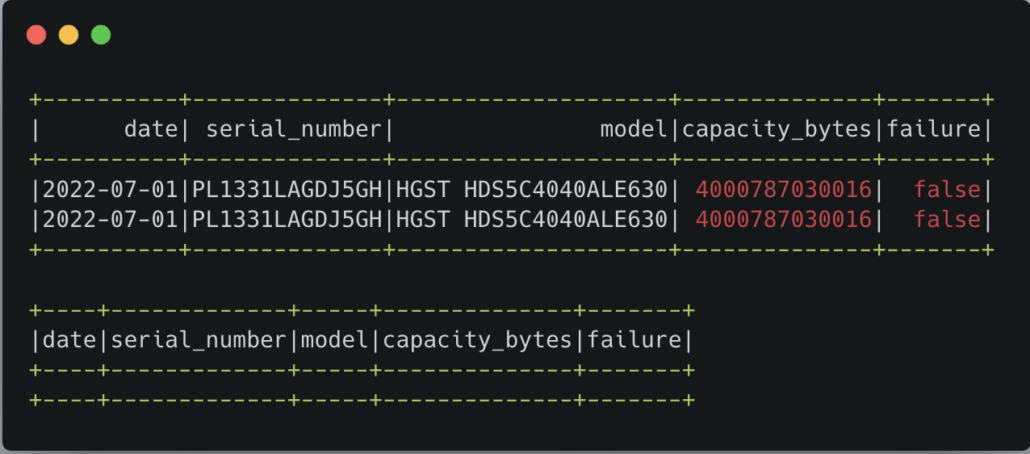
First, we can start by trying kill_duplicatefunction.
“completely removes all duplicate rows from a Delta table.”
I suppose this can be kind of helpful. Personally, I believe all transformations and data models should be built in such a way as to remove duplicates during the process and avoid their persistence. But, we all know duplicates happen. I suppose this function could be a great way to programmatically remove duplicates in many Delta Tables.
Let’s introduce a duplicate into our Delta Table, then remove it.
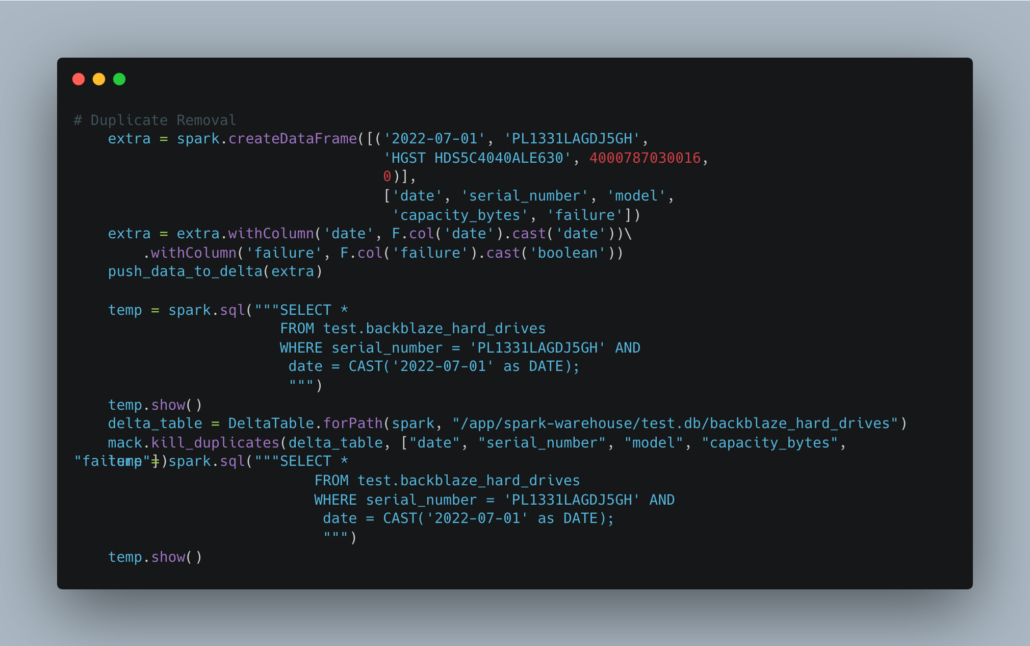
By the Beard of Gandalf, it worked!
drop_duplicates_pkey
I was going to try testing this method, but its premise seemed a little strange to me.
“The
drop_duplicates_pkeyfunction removes all but one duplicate row from a Delta table”
It basically assumes that you have primary_key in a Delta Table, but that the primary_key apparently isn’t unique and there are duplicates made up of other columns on the record. I guess from my perspective with a good data model, such a thing shouldn’t happen, or rarely happen, and if it did, everything should be emptied and recalculated and filled.
I’m going to not try this method because it seems of little use unless you’re living in the Mad Max world of Data Lakes where anything goes and this is actually a thing … a primary_key that … isn’t.
copy_table
This is an interesting function.
“The
copy_tablefunction copies an existing Delta table. When you copy a table, it gets recreated at a specified target. This target could be a path or a table in a metastore.”
I honestly don’t find myself copying Delta Tables very much, mostly because the ones I use are massive, and copying tables around would be expensive in both compute and storage. I mean you could simply read an entire table in a dataframe and then just write it back to a location as another Delta table. Not sure it makes sense to use a helper function.
validate_append
Now here is a helpful function I think. If you’re working on a large team with lots of data, and ever-changing data, there is a real chance of buggering up Delta Tables with schema changes and the like. I think built-in validation of any kind on Data Teams is an absolute game changer.
Make it second nature to check on things in-process. Most folk think it adds unnecessary overhead, but just wait till everything is buggered … then you will wish you would have taken proactive steps to solve the issues before. Let’s try this one.
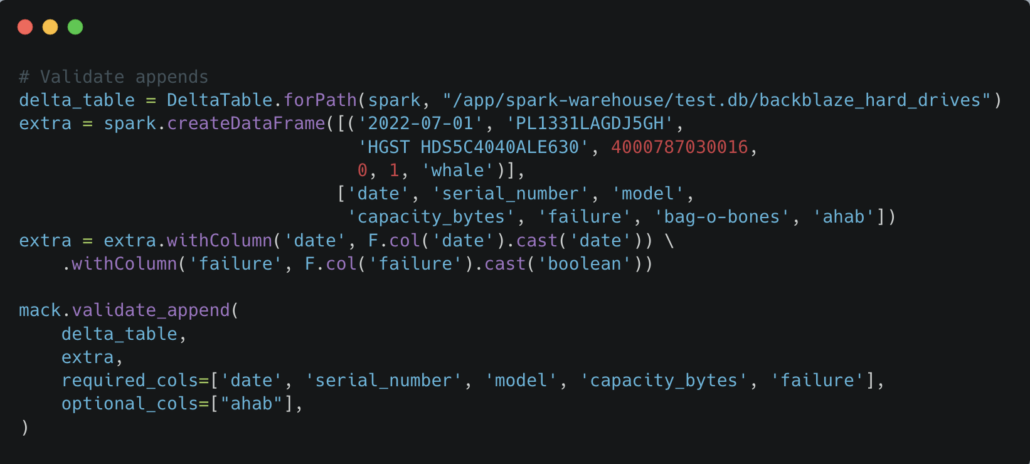
You can see I added two extra columns ahab and bag-o-bones, and told the validate_append that only ahab is optionally allowed. So It should blow up when I run.
Notes on other functionality.
It actually looks like mack has a bunch of other great functions around composite, aka primary_key creation. They look to be super useful.
- with_md5_cols
- is_composite_key_candidate
- humanize_bytes
- type_2_scd_upsert
I think composite keys and primary keys are under-used concepts in Big Data, and Delta lake warehouses. I’m really looking forward to watching this package in the future. I hope it gets adoption and contributors that help expand what it can do, there is real value in making certain mundane Delta Lake tasks easier.
You can find all this code on GitHub.
It’s fun to see my favorite tools, Spark and Delta Lake start to get popular and have smart people creating awesome packages and helpers to assist others in the adoption and usage of those tools. Community is what makes tools grow and thrive, and mack is a great addition for Delta Lake users.
Thanks for the post. I had the mack lib on my list and your post forced me to give it a try. Just one remark on your duplicate function testing. From what I can see, the following use cases are covered
– kill_duplicates: rermove all duplicates; so none of the entries remain -> not sure why I would need that
– drop_duplicates_pkey: rermove all duplicates but one; so one entriy remains -> this is what I understand as duplicate removal
Note that in no case primary keys are duplicated as you assumed. Actually, I wish the kill_duplicates function would leave one entry as well (for example by chance or the first entry) as I don’t see a use case to remove all duplicates.