Real Talk about Running Databricks + Delta Lake at Scale.

Photo by Michael Carruth on Unsplash
Anyone who’s been working in Data Land for any time at all, knows that the reality of life very rarely matches the glut of shiny snake oil we get sold on a daily basis. That’s just part of life. Every new tool, every single thingy-ma-bob we think is going to solve all our problems and send us happily into the state of nirvana inside our eternal data pipelines, is a lesson in disappointment.
I get it, there are a lot of nice tools out there. I use some of them every day. But, a healthy dose of reality is good for us all. Don’t lie to yourself. There is no such thing as the perfect tool. There are good tools, bad tools, and tools in between. The Truth is that all tools get pushed to their limits at some point.
We work on small teams, we don’t have all the time in the world, and we have to deliver our data at some point, perfect or not. We cut corners, hopefully, the right ones. That’s part of being wise and putting years of data experience to work. Today I’m going to talk about my experience of running Databricks + Delta Lake at scale. What happens when you use Databricks to ingest and deal with 10’s of millions of records a day, billions+ records a month?
The Problem with Data Teams.
So. Here’s the thing. Not all of us work at Google, Apple, Facebook, or Netflix. The vast majority of Data Engineers and practitioners work at smallish companies and since we/they are working on Data Teams, we are by default overworked and pushed to our limits daily. We need to provide …
- Solutions in a reasonable timetable.
- Don’t have our own Architect, Platform, or DevOps teams to rely on.
- Have to be very cost conscious.
- People constraints (small teams).
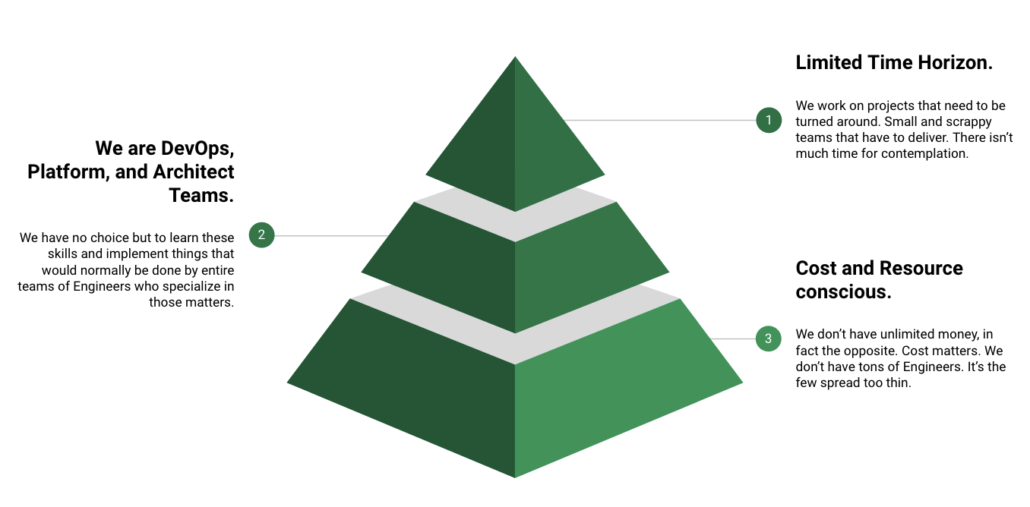
Doesn’t sound like that big a deal? Whatever. It is. Most of us don’t work at places that simply write checks to let us spend whatever we need a compute to do the job. Most of us don’t work on teams that are oversized or even have staffing levels where they should, we are one of a few Data Engineers with the world on our shoulders.
We don’t simply turn to some Platform or DevOps team when we need some AWS work on CI/CD work done. We do it ourselves because that’s the only option. Well, now that we are done complaining.
Databricks + Delta Lake at Scale. Real Talk.
I had to preface the following section with the one that came above. Why? Because some people don’t live in the fast pace real world the rest of us do. They will complain “Well, you should have thought about this or that.” “You should have pivoted, why didn’t you know that?” “You should have done more research.”
Well, yes, and yes, in a perfect world, we would all love to do such things.
“The truth is we make the best and most informed decisions we can at the time with the knowledge and resources we have available to us at the time.”
So now without further fanfare and trumpets, I’m simply going to list, in retro-spec, lessons learned from processing billions of records with Databricks + Delta Lake at scale. Stuff that has to run perfectly every day. Not just analytics for downstream consumption, but core business processing integral to the bottom line.
Lessons Learned with Databricks + Delta Lake at Scale.
Here we go. I will let this. Comment on some of them. Then slowly disappear into the background.
- Pay attention to the architecture of your Workspace(s) upfront.
- Understand what kind of permissions and controls you want and how to implement them.
- Understand how you want to use database schemas.
- Powerful tool, take advantage of them.
- Think through your Dev vs Prod environment.
- How will you implement this, schemas, workspaces, etc?
- Understand that Notebooks are $$$$$ (All-Purpose clusters) vs Jobs are cheap.
- You can blow money real easy like if you’re not thinking.
- Figure out how you want to orchestrate your Pipelines. (don’t just default Workflows).
- Understand Premium Account vs Not, and the features you will gain or lose.
- Seriously, better dig into this. You might get what you think you’re getting otherwise.
- Understand how you will deploy your libraries onto your Spark Databricks clusters.
- Figure out your CI/CD and deployments.
- Be realistic about how to solve the `delta.exceptions.ConcurrentAppendException:` problem.
- Be careful with your Data Model. If you design a
facttable that gets hit a lot. She’s coming for ya.
- Be careful with your Data Model. If you design a
- Understand how to solve
Instance Type Not Availablewhen running lots of Jobs.- If you runs lots of Jobs, you will run out of instance types, so be ready to get creative. Yes I know about
AUTO.
- If you runs lots of Jobs, you will run out of instance types, so be ready to get creative. Yes I know about
- Don’t use the latest DBR version unless you’re feeling lucky.
- Unless you like your queries magically grinding to a halt on upgrade.
- Be ready to be treated second class if you don’t use Unity Catalog, Premium Account, or Workflows.
- They ain’t dumb and know how to give the good stuff to the $$$ accounts and features they want you to use.
- Ignore OPTIMIZE and VACUUM at your own peril.
- Ignore Partition Pruning at your own peril.
- Learn basic Spark tuning if you don’t want to spend a lot of money.
- Ensure you have Data Quality plan of attack before you start.
I could probably go on but I should probably stop before I get myself in trouble.
Ending on a positive note.
I don’t always want to be Gandalf Stormcrow, although I do find much joy in that, strangely enough. Honestly, Databricks + Delta Lake is a game-changer. In all my years of Data Engineering, I’ve never seen a pairing of tools quite like these twos.
The ease with which one can crunch billions of records is astounding. The ability of Delta Lake to abstract complex data transformations and updates (like MERGE) is a beautiful thing to behold. Databricks made Spark easy, they did what EMR failed to do. Bring approachable Spark on Big Data to the masses without walking through the seven rings of hell.
But, my words of warning stay true. Don’t ignore the details. Sometimes when things are too easy it makes us jump the gun, and rush in head first without thinking, just because it’s easy. This will come back to bite you in the Databricks + Delta Lake world. Read the documentation, understand the features, know all the best practices, and work out your architecture to the detail before implementation.
Why are you so sad with Workflows? Could you elaborate? Thanks.
Wow! I just had a retro on a huge project utilizing Delta Lake + Databricks. Spot on!