Python vs Scala – Concurrency.

One of the reoccurring complaints you always see being parroted by the smarter-then-anyone-else-on-the-internet Reddit lurkers is the slowness of Python. I mean I understand the complaint …. but I don’t understand the complaint. Python is what is is, and usually is the best at what it is, hence its ubiquitous nature. I’ve been dabbling with Scala for awhile, much to my chagrin, and have been wondering about its approach to concurrency for awhile now. I’ve used MultiProcessing and MultiThreading in Python to super charge a lot of tasks over the years, I want to see how easy or complex this would be in Scala, although I don’t think easy and Scala belong in the same sentence.
Python concurrency with ProcessPools and ThreadPools.
I’ve got about 13 CSV files I downloaded from the Divvy Bike Trips free data set. I really want to keep this simple since I’ve got to try to do this in Scala, and that’s always scary.
What I want to do is simple. I want to process each csv file as if I was doing some actual ETL or pipeline work. Both with Python and Scala, using just single core/thread and then applying concurrency to the problem, to observe performance and simplicity. I won’t use Python async because it’s a scourge that needs to be removed from the land.
- Python – processing one-by-one.
- Scala – processing one-by-one.
- Python – multithreading (which still means only one thread running at a time, thanks GIL)
- Python – multiprocessing
- Scala – Futures (multithreading)
For arguments sake I’m going to open each file and iterate the lines, looking for only those rows that contains a bike ride from a member. Obviously this isn’t what we would do in real life, but it gives us something to do for our test.
Let’s just get right down to it. First we will just process the files normally with Python, one at a time.
import csv
from glob import glob
from datetime import datetime
def main():
files = gather_files()
for file in files:
rows = read_file(file)
for row in rows:
filter_row(row)
def gather_files(loc: str = 'trips/*.csv') -> iter:
files = glob(loc)
for file in files:
yield file
def read_file(file_location: str) -> iter:
with open(file_location, 'r') as f:
data = csv.reader(f)
next(data)
for row in data:
yield row
def filter_row(row: object) -> None:
if row[12] == 'member':
print('member ride found')
if __name__ == '__main__':
t1 = datetime.now()
main()
t2 = datetime.now()
x = t2-t1
print(f'It took {x} to process files')The code is pretty self explanatory, what we are interested in is the time It took 0:00:11.780710 to process files. Another reason to like Python, the code is easy to read and simple.
MultiThreading with Python
Next we will modify the code to have to run in a ThreadPool.
import csv
from glob import glob
from datetime import datetime
from concurrent.futures import ThreadPoolExecutor
def main():
files = gather_files()
with ThreadPoolExecutor(max_workers=6) as Thready:
Thready.map(work_file, files)
for file in files:
rows = read_file(file)
for row in rows:
filter_row(row)
def work_file(file_loc: str) -> None:
rows = read_file(file_loc)
for row in rows:
filter_row(row)
def gather_files(loc: str = 'trips/*.csv') -> iter:
files = glob(loc)
for file in files:
yield file
def read_file(file_location: str) -> iter:
with open(file_location, 'r') as f:
data = csv.reader(f)
next(data)
for row in data:
yield row
def filter_row(row: object) -> None:
if row[12] == 'member':
print('member ride found')
if __name__ == '__main__':
t1 = datetime.now()
main()
t2 = datetime.now()
x = t2-t1
print(f'It took {x} to process files')With the addition of a single method work_file we are able to run the files through a MultiThreading pool.
It took 0:00:19.453903 to process files It was actually much slower. This will be of no surprise to the astute reader like you. Our code is mostly CPU bound, reading files and processing rows. So adding the overhead of actually switching between Threads is adding overhead and not solving any problem because we aren’t really “waiting” on a Database or API, some external system to respond.
ProcessPool’s should do the trick uh?
ProcessPools with Python
This will be very similar, pretty exactly the same as the last bit of code, just swapping out ThreadPool for good ole’ ProcessPool.
import csv
from glob import glob
from datetime import datetime
from concurrent.futures import ProcessPoolExecutor
def main():
files = gather_files()
with ProcessPoolExecutor(max_workers=3) as Thready:
Thready.map(work_file, files)
for file in files:
rows = read_file(file)
for row in rows:
filter_row(row)
def work_file(file_loc: str) -> None:
rows = read_file(file_loc)
for row in rows:
filter_row(row)
def gather_files(loc: str = 'trips/*.csv') -> iter:
files = glob(loc)
for file in files:
yield file
def read_file(file_location: str) -> iter:
with open(file_location, 'r') as f:
data = csv.reader(f)
next(data)
for row in data:
yield row
def filter_row(row: object) -> None:
if row[12] == 'member':
print('member ride found')
if __name__ == '__main__':
t1 = datetime.now()
main()
t2 = datetime.now()
x = t2-t1
print(f'It took {x} to process files')Using 3 seperate Process’s running at the same time really brought the time down, as it should.
It took 0:00:05.577559 to process files
Summary before diving in Scala.
Let’s take a quick look at what we’ve done so far before I try to learn how to do this in Scala.
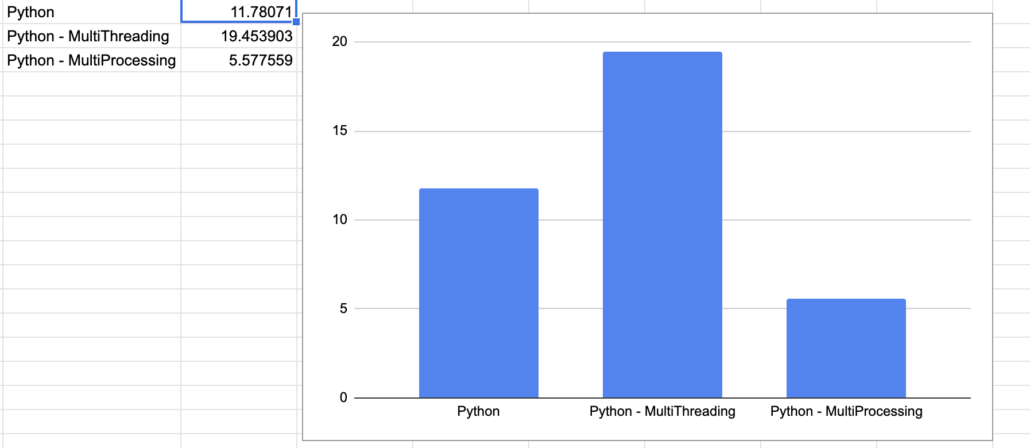
Now let’s work on adding two more bars to the graph. One for just running Scala normally, and one with a single attempt with Futures in Scala.
Scala
Word of warning, take my Scala with a grain of salt. It’s worth what this blog costs you.
import scala.io.Source
import java.io.File
object etl extends App {
def gather(): List[java.io.File] = {
val d = new File("trips")
val files = d.listFiles.filter(_.isFile).toList.filter(_.getName.endsWith(".csv"))
files
}
val t1 = System.nanoTime
val files = gather()
for (file <- files) {
val f = io.Source.fromFile(file)
for (line <- f.getLines) {
val cols = line.split(",").map(_.trim)
// do whatever you want with the columns here
if (cols(12) =="member") { println("member ride found")}
}
f.close
}
val duration = (System.nanoTime - t1) / 1e9d
println(duration)
}
The normal Scala I wrote to process the files one by one it’s too bad, even for someone like me. Easy to understand. Surprisingly slow, i though Scala was supposed to be blazing fast. Probably my fault.
11.1591165
Just ever so slightly faster then the one-by-one Python.
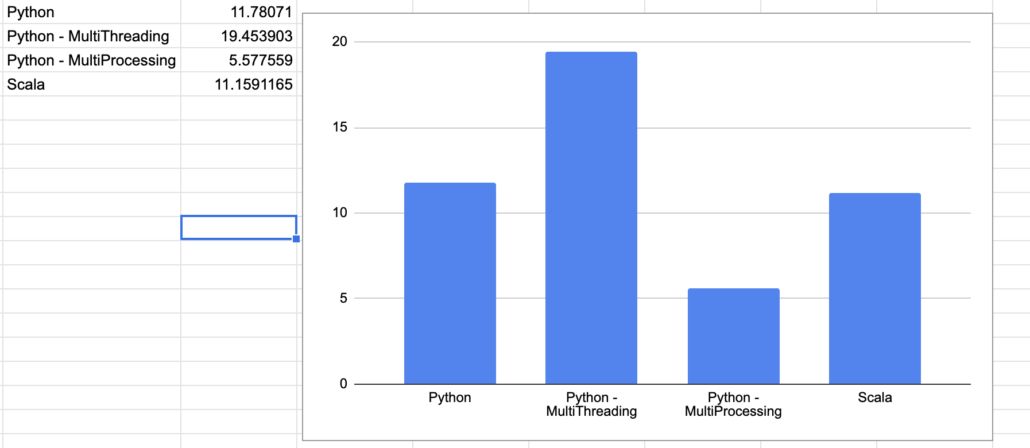
Scala – Futures.
Here goes my muddled attempt at concurrency in Scala … who knows what will happen, probably nothing good.
I’m picking Scala Futures because from what I’ve read it looks like the easiest one for me to pick up.
From what I can tell a Scala Future is basically an easy way of saying you can do this in the background. The concept seems very similar to Python `async`, at least at a high level. Except in this case a Scala Future can execute on a separate Thread.
After much muddling around, here is my first attempt at some concurrent Scala … although I have no idea if it actually is.
import scala.io.Source
import java.io.File
import scala.concurrent.Future
import scala.util.{Failure, Success}
object etl extends App {
val t1 = System.nanoTime
implicit val ec: scala.concurrent.ExecutionContext = scala.concurrent.ExecutionContext.global
val files: Future[List[java.io.File]] = Future {
val d = new File("trips")
val files = d.listFiles.filter(_.isFile).toList.filter(_.getName.endsWith(".csv"))
files
}
def transform(file: java.io.File): Unit = {
val f = io.Source.fromFile(file)
for (line <- f.getLines) {
val cols = line.split(",").map(_.trim)
if (cols(12) == "member") {
println("member ride found")
}
}
f.close
}
files.onComplete{
case Success(files) => {
for (f <- files) transform(f)
}
case Failure(exception) => println("Failed with: " + exception.getMessage)
}
val duration = (System.nanoTime - t1) / 1e9d
println(duration)
Thread.sleep(25000)
}
A few comments and confusions I ran into trying to write concurrent Scala with Futures.
First, I needed an execution context to be available, even though after setting it up, it doesn’t get reference by my code at all. This wasn’t really obvious from the documentation I read.
implicit val ec: scala.concurrent.ExecutionContext = scala.concurrent.ExecutionContext.globalImplementing a Future in Scala turned out to be pretty easy. All I had to do is wrap a something in Future {} and that seems to be all that is needed.
After that acting on the results of that Future appears to be a simple as using a callback , such as maybe looping the results, or conveniently calling .onComplete{} upon that future.
For the life of me I couldn’t really figure out how to time the Scala code. Putting a timer at the start and finish didn’t work.
Something else that caught me off guard was that fact since a Future will run in a totally separate thread…. I actually had to call Thread.sleep(25000) to keep the program from shutting down.
Overall Scala Futures feel like a cross between Python’s multiprocessing and async modules. Who know’s if my code is remotely correct, but that’s how you learn.
I also read a little more about AKKA in Scala, which I’ve poked at a few times. Processing multiple files concurrently with Scala correctly should probably be done this way. After reading a few examples of such a thing, and deciding I have only one life to live, I figured that would have to be the topic for a different day, not feeling like a glutton for punishment today.