Python and Apache Parquet. Yes Please.

Update: Check out my new Parquet post.
Recently while delving and burying myself alive in AWS Glue and PySpark, I ran across a new to me file format. Apache Parquet.
It promised to be the unicorn of data formats. I’ve not been disappointed yet.
Data compression, easy to work with, advanced query features. If your looking for an awesome columnar file storage solution that supports HDFS style partitions, have at it.
Here is a quick intro. You will need two tools from your Python tool belt. Pandas and PyArrow.
pip install pyarrow pip install pandas
Go to this free government website and grab yourself a .CSV file. I pulled down the Chicago crimes file from 2001 to present.
Then simply read the CSV file into a pandas dataframe.
dataframe = pandas.read_csv('crimes.csv')
Then use the pandas function .to_parquet() to write the dataframe out to a parquet file.
dataframe.to_parquet('crimes.snappy.parquet' ,engine='auto', compression='snappy')

The first thing to notice is the compression on the .csv vs the parquet. The parquet is only 30% of the size. That seems about right in my experince, and I’ve seen upwards of about 80% file compression when converting JSON files over to parquet with Glue.
One thing I like about parquet files besides the compression savings, is the ease of reading and manipulating only the data I need.
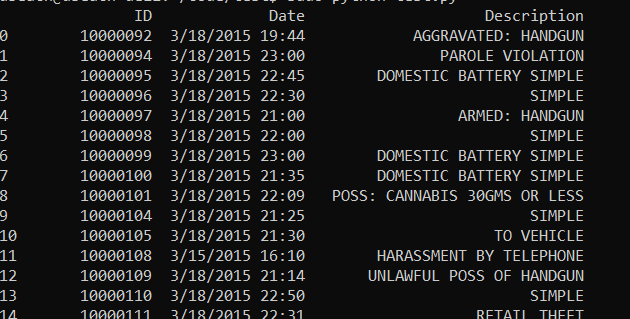
import pyarrow.parquet as pq data = pq.read_pandas('crimes.snappy.parquet', columns=['ID', 'Date', 'Description']).to_pandas() print data
Parquet and pyarrow also support writing partitioned datasets, a feature which is a must when dealing with big data. With pyarrow it’s as simple as…
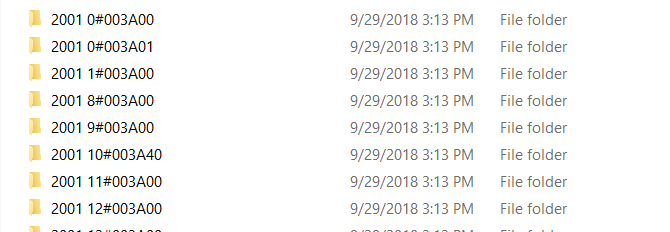
data = pq.read_table('crimes.snappy.parquet', columns=['ID', 'Date', 'Description']) pq.write_to_dataset(data, root_path='dataset', partition_cols=['Date'])
And shortly thereafter, your files are there partitioned as requested.

Super simple but powerful as you can see. And that barely scratches the surface of pyarrow and Apache parquet files.