
PyArrow vs Polars (vs DuckDB) for Data Pipelines.
![]()
I’ve had something rattling around in the old noggin for a while; it’s just another strange idea that I can’t quite shake out. We all keep hearing about Arrow this and Arrow that … seems every new tool built today for Data Engineering seems to be at least partly based on Arrow’s in-memory format.
So, today we are going to do an experiment.
What if instead of writing a Data Pipeline in Polars, or another tool … that uses Arrow under the hood … what if we actually write a data pipeline with Arrow?
What’s up with Apache Arrow?
(all code available on GitHub)
So, I’m not going to go in-depth about Apache Arrow , I’ve previously written on that subject, so go check that out for more info.

More or less, this is what Apache Arrow is and does,
- In-Memory Columnar Format: Arrow is primarily known for its in-memory columnar format, which is optimized for analytical workloads and enables efficient data access and processing. This format allows for high performance, especially in use cases involving large datasets.
- Interoperability: One of Arrow’s main goals is to facilitate interoperability between different data processing systems. It provides a common data representation that can be shared across various systems without the need for data serialization and deserialization, thus reducing the overhead of data exchange.
- Language Support: Arrow provides libraries for various programming languages, including C++, Java, Python, and R. This multi-language support makes it easier to use Arrow in diverse data processing environments.
The reason we can write data pipelines as with Arrow is because of the provided Python package, pyarrow. This package gives us access to a lot of “Arrow” functionality.
Today let’s explore that on the surface level, and write a simple pipeline with it, and compare it to the code to do the same thing with Polars, including performance.
Apache Arrow and data.
Now, it’s clear to most of us that Apache Arrow is the GOAT of the Data Space, considering all the tools that rely on it. But, it’s also pretty obvious that few of us actually interact directly with Apache Arrow on a regular basis doing regular Data Engineering work.
I mean I’ve used it here and there when scanning in directories of certain files on s3, but typically what happens is that at some point you convert that Apache Arrow dataset to something else, like Polars etc. That begs the question of if Apache Arrow is so awesome, why aren’t people using it directly for normal data work?
I guess we will find the answer to that question as we write a data pipeline, but I generally believe that Apache Arrow was built to be a tool that other tools use, and not really something for everyday consumption. Case and point, there is not a concept of a DataFrame per se… in pyarrow you won’t find a class called DataFrame for example.
But, we have to start somewhere.
Apache Arrow provides something called a Table. This is an abstraction of an Arrow Array, and we can call many built-in methods on Tables.
To make this more concrete we might as well start writing our pyarrow data pipelines. Let’s do something basic, something we can do in Polars as well, and look at the code side-by-side, as well as see the general performance. Is it worth it to use pyarrow as a data pipeline tool? Let’s find out.
Writing a pyarrow data pipeline.
First, we need a pipeline to write, something that does something, but is obvious and easy so we can reproduce it in Polars.
- read a bunch of CSV files sitting in s3.
- filter that resulting dataset.
- run an aggregation on the dataset.
- write results to Paruqet in s3.
This all seems reasonable, reasonable to expect a tool to accomplish this task.
Here it goes.
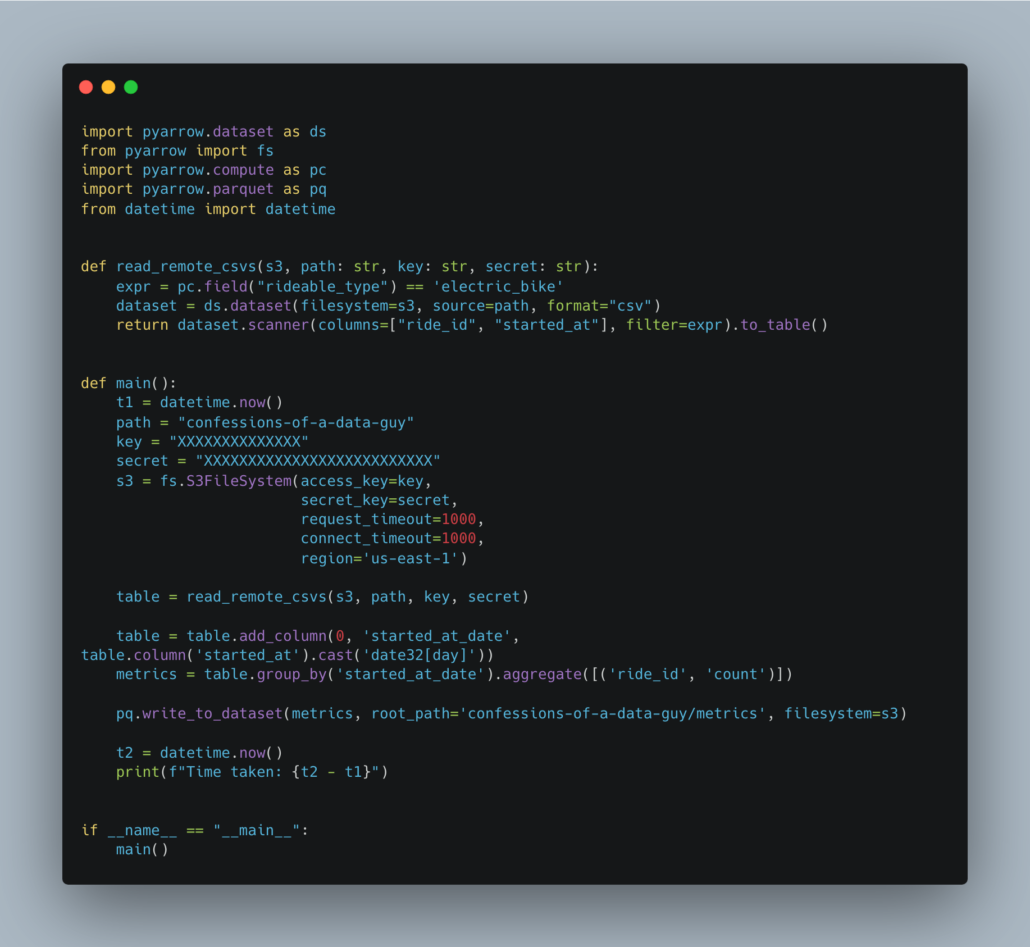
Time taken: 0:00:53.904340
It doesn’t look to bad, but I did notice some subtle things. It’s obvious to me why no one uses pyarrow for making data pipelines … the syntax is all wonky. It’s simply strange. It’s subtle but weird, especially for those used to using Dataframe tools like Spark or Polars etc.
Adding columns requires you to indicate the index, aggregating functions are kinda strange with columns and aggregation required, and having to setup the FileSystem for s3 instead of making it invisible is weird too. S3 is so common, why be weird about it?
I mean it isn’t horrible, but it’s strange enough to be a turn-off.
The next question is, what is the performance like, say compared to Polars?? And what does the code like?
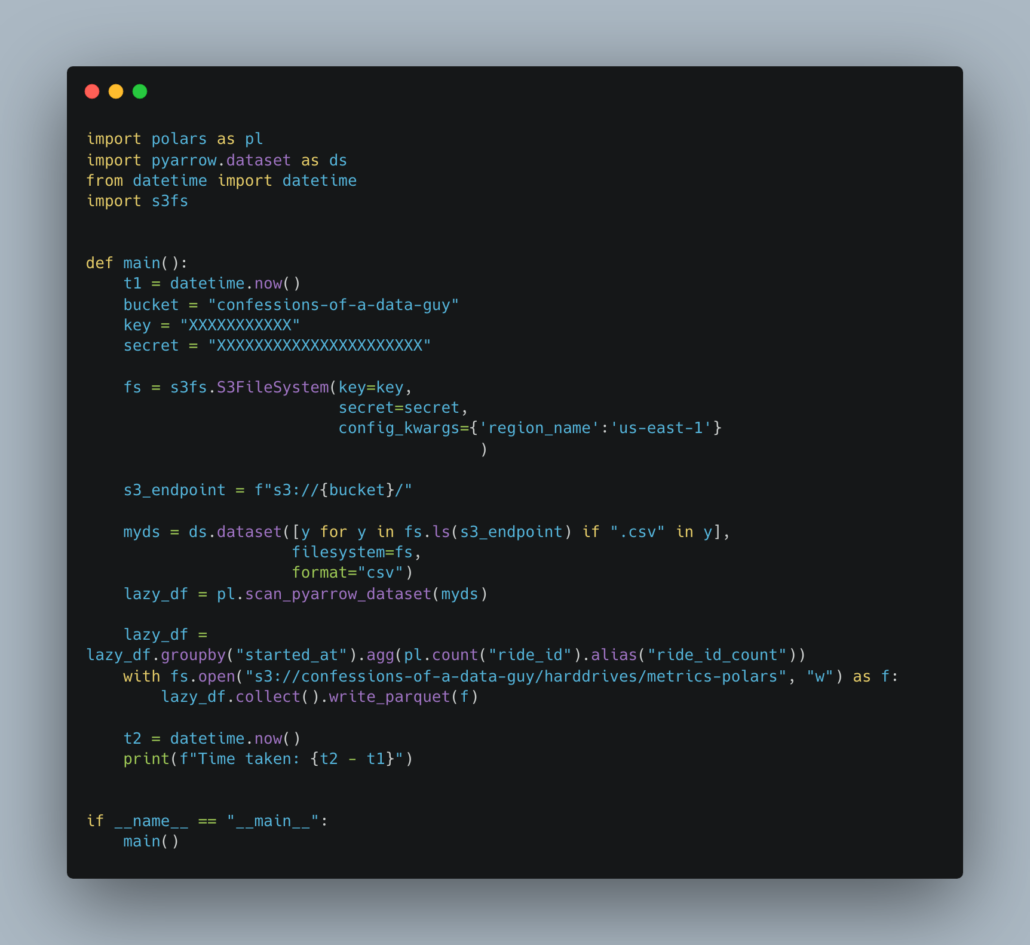
Surprisingly the Polars code isn’t much better. Apparently, at the time of writing, Polars has no out-of-the-box support for reading directories of CSV files from s3. So annoying.
Funnily enough, we have to use pyarrow to get the job done!
The only nice thing about the Polars code is that the actual syntax is nicer and more what a person who works with Dataframes would be used to. Much better than pyarrow for the aggregations and filters etc.
But even more surprising, or not, is that Polars finishes the job faster than pyarrow.
Time taken: 0:00:47.062761
Interesting indeed, I did not see that coming, if I was placing a bet, I would have bet on raw pyarrow to be faster, but apparently Polars is all it’s cracked up to be.
Maybe we should try DuckDB just to be funny.
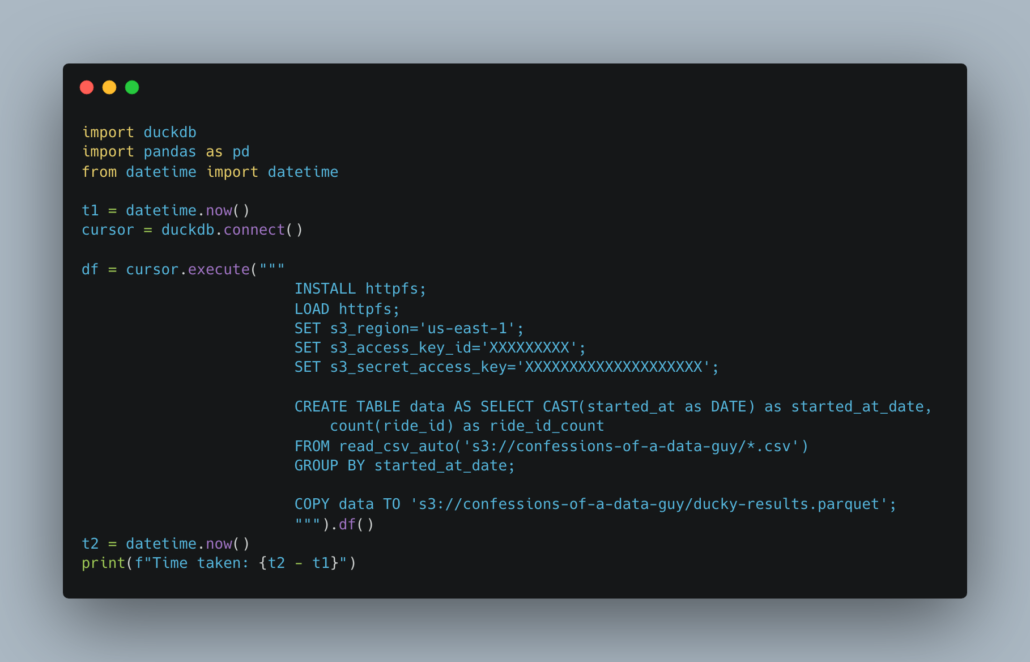
The code for DuckDB is nice and clean, much better than pyarrow or polars in my opinion, all in one statement. Less code is always good.
But DuckDB is the slowest.
Time taken: 0:01:10.751141
