Polars – Laziness and SQL Context.

Photo by Priscilla Du Preez on Unsplash
Polars is one of those tools that you just want … no … NEED a reason to use it. It’s gotten so bad, I’ve started to use it in my Rust code on the side, Polars that is. I mean you have a problem if you could use Polars Python, and you find yourself using Polars Rust. Glutton for punishment I guess.
I also recently took personal offense when someone at a birthday party told me that everyone uses Pandas, and no one uses Polars in the real world. Dang. That hurt.
The reality is that I know it takes a long while for even the best technologies to be adopted. Things don’t just change overnight. But there are two hidden gems of Polars that will hasten the day when Polars replaced Pandas for good. Let’s talk about them.
Two Reasons to Use Polars.
Sure Polars is faster than Pandas, yeah, it’s based on Rust with makes it hip and cool. But, there are two other reasons Data Engineers should sit up and take notice of Polars. These are reasons why Polars is lightyears ahead of Pandas and is taking the Data Engineering world by storm.
- Lazy
- SQL Context
These are two of the unsung heroes of Polars, heroes that go on working through the night while everyone parades around singing the praises of how fast Polars is, or how much better the syntax is than Pandas. Sure, those things are nice, but where the rubber meets the road, that’s where it counts, and the Lazy and SQL Context features are what take Polars to the next level.
There are certain things that make Data Engineering more efficient, enjoyable, and easy. Both these features, Lazy and SQL Context are top tier on the shelve of things you could put into that column. Think about it.
“Why are PySpark and Spark so popular? Because of its lazy computing nature, and the availability of SQL.”
Let’s dive into each of these features, Laziness and SQL Content of Polars.
Lazy Polars.

What a lazy son of a gun. Nothing wrong with that.
Laziness is what allows Polars to read larger than memory files. But not only that, but it also allows for query optimization, similar to how Spark works, or at least generally the same idea. It allows things to be “planned” or “optimized” prior to actually running something … find the best path before setting off on your journey.
- larger than memory files.
- allows for query optimizations.
- predicate pushdown
- projection pushdown
- expression simplification
- joins
- cardinality
- etc.
- schema errors prior to runs.
All these things add up to a great tool that runs fast. You can use scan , which is how Polars implements it’s laziness, on parquet, csv, and json files.
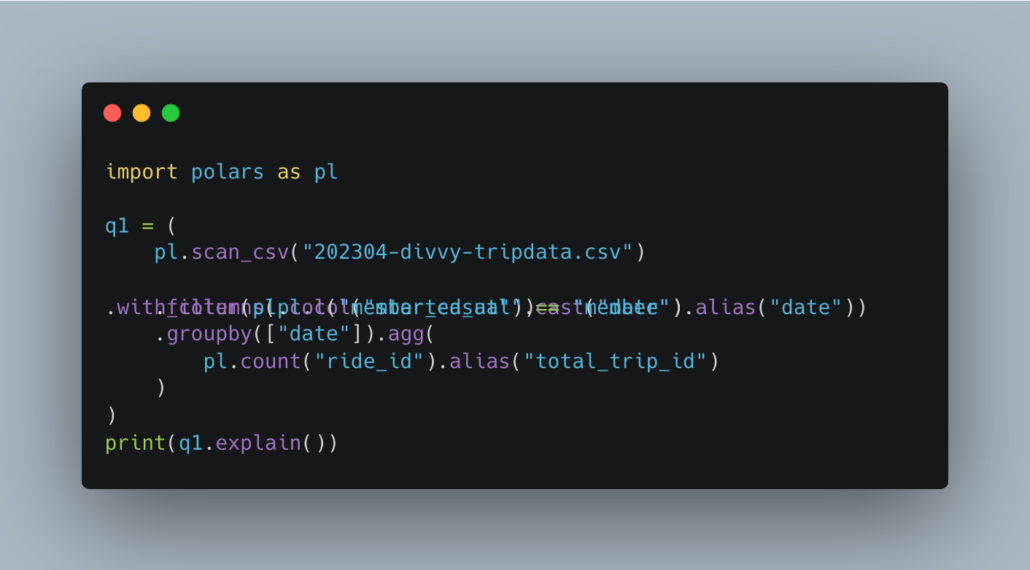
And we can explain the plan.
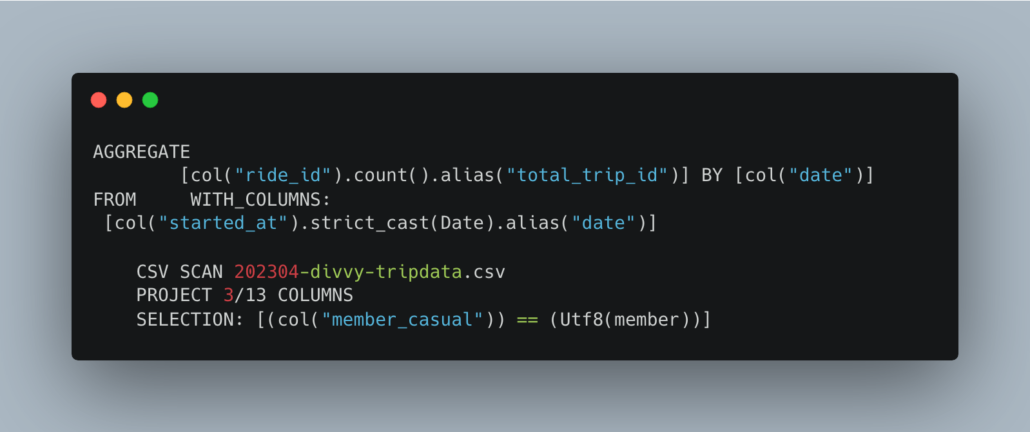
I know this is a simple example, and might not seem like a big deal on the surface, but I assure you it is. If you are doing complex transforms and queries, this is typically only a feature (lazy and execution plans) that is available via Spark for the most part.
The fact that you get these features with Polars after a simple
pipinstall, it’s truly a game changer for the future of Data Engineering. The fact that Polars can be lazy about the execution of a plan, optimize the plan, and provide the query plan prior to execution, so it can be debugged and improved … means it’s a next-level tool for those Data Engineers looking to be next-level Data Engineers.
I don’t care what your parents said to you, laziness is good in Data Engineering. This lazy feature also gave birth to yet another game changer, one people will probably even appreciate more.
SQL Context for Polars

Photo by Caspar Camille Rubin on Unsplash
And now we come to the crux of the matter. I know how much you love SQL, even when you shouldn’t. Only a fool would spurn SQL, even though I myself have decried its overuse. The truth is that SQLis, and always will be, the bread and butter of most Data Engineering pipelines.
I myself prefer to use DataFrame API’s, and only use SQL when doing aggregations, etc. But, nonetheless, SQL is the defacto language of Data Engineers, Analysts, Data Science, Analytics, and all the rest.
It lowers the bar and is easy to learn.
“When Polars added their SQL Context, they took the tool to a whole different level and opened up Polars to a whole new range of users.”
Again, Polars start to smack of Spark, and we all know how popular that is. Polars is quickly closing the gap. Between the larger-than-memory file processing and the SQL Context, there is little left besides the distributed nature of Spark, which is unneeded for a large portion of folks, that divides Polars from Spark.
Here is Polars SQL.
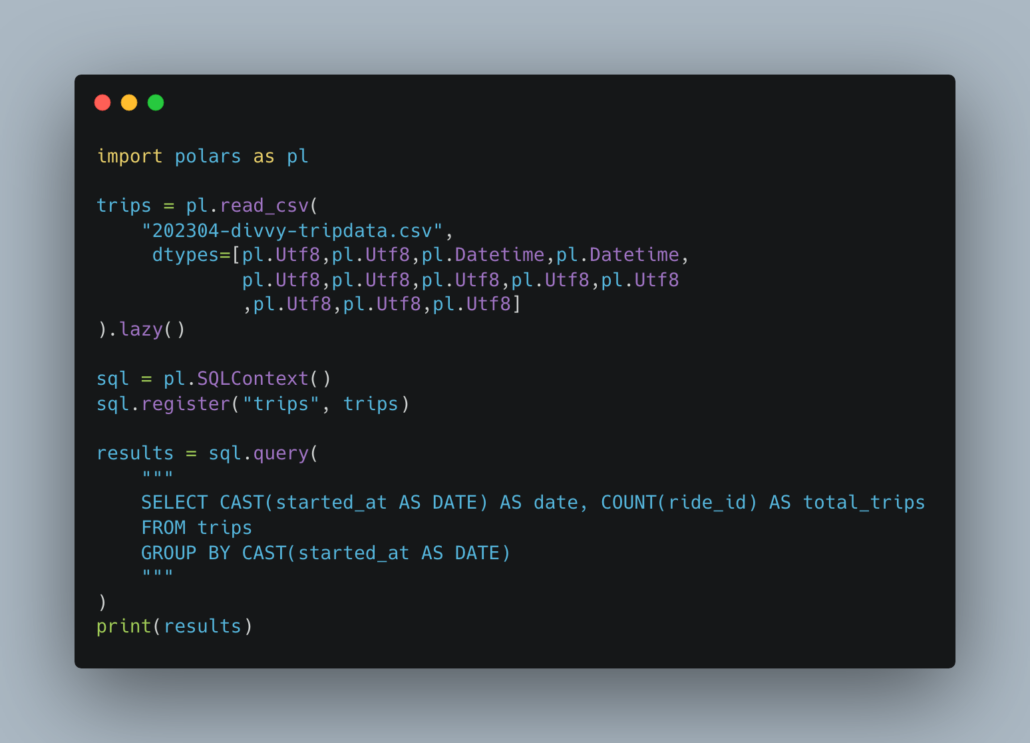
I mean it’s so exciting it’s boring.
I’m honestly surprised more people haven’t been talking about this. Maybe it’s the rise of DuckDB, I dunno. Maybe it needs to be marketed better, who knows?
The fact we now have a local tool we can use for all non-Big-Data size data pipelines that can run on single nodes on greater than memory files … well, it’s simply a huge boon for the Data Engineering community, that should be recognized and used more.
Why?
- Many Spark jobs running on clusters should be switched to Polars
- and save lots of money
- It’s arguable as easy, or easier, to write Polars than Spark.
- SQL Context makes it so ANYONE can write pipelines with Polars.
- Laziness means it’s incredibly fast and useful, and debuggable.
Strangeness.
It seems like when everyone talks about Polars these days … they just see it as a faster version of Pandas. Well, yes, it is that for sure. But that sort of simplifies things to a point that misses so many other wonderful parts of Polars. Laziness and SQL are two of those things that seemed to have passed under the radar of most people.
I do hope to see Polars continue to rise and find a home in the Data Engineering community, nice in just nice little blog posts and snippets like this, but in actual production use cases. I believe Polars speaks for itself and is worthy of our worship.