Please Sir, May I Have Some More Parquet?

I’ve been wanting to follow up on a post I did recently that was a quick intro to Apache Parquet, specifically when, where , and why to use it, maybe test some of its features, and what makes it a great alternative for flatfiles and csv files.
Quick recap, parquet is an open source columnar file storage format made popular by Hadoop. It offers great compression, nested columns, and its structure makes for fast and efficient query/data retrieval, reducing IO etc. I like to think of it as a cross between JSON and a CSV file, plus some, I know somebody will hate me for saying that but whatever.
So what makes Parquet better? Columnar storage for one. What does that mean? Instead of thinking about data stored like a CSV file in rows… think about all the values of say sales numbers you need to SUM, stored together in a row group, typically in row based storage you would have to scan all the rows to pull out the column you need. In columnar storage those values are stored together and be quickly and easily accessed together.
Also, another advantage of Parquet is only reading the columns you need, unlike data in a CSV file you don’t have to read the whole thing into memory and drop what you don’t want. Let’s take a look at what we can do with Python (pyarrow) and Parquet.
We will read in a csv file I had laying around for my last machine learning attempt, convert it to a pyarrow Table, then get ready to write the csv data to a Parquet file.
import pyarrow.parquet as pq
import pyarrow.csv as pqc
table = pqc.read_csv('loanfeatures.csv')
print(table.shape)
print(table.schema)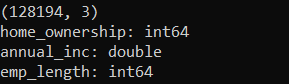
pq.write_table(table, 'test.parquet')
readback = pq.read_table('test.parquet')
pandasDF = readback.to_pandas()
print(pandasDF.head())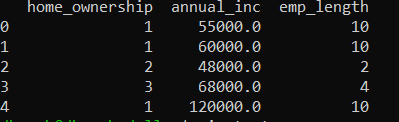
Of course the read_table() and write_table() are very extensible, which is one reason that Parquet is not your average file format. Say we are just looking for the annual_inc column. It’s as simple as changing this line. This is a powerful feature if your storing large amounts of data in Parquet files and looking for/needing something in particular.
readback = pq.read_table('test.parquet', columns=['annual_inc'])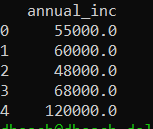
Part of what makes this all possible is the meta data stored with a Parquet file.
file = pq.ParquetFile('test.parquet')
print(file.metadata)
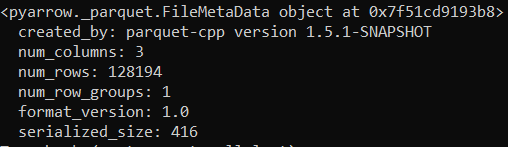
If you’ve been around Parquet or columnar storage for awhile you’ve probably come across “row groups.” A row group is basically something that makes your Parquet file split-able. So what does this mean? It means be careful when playing with row groups, it affects your I/O and and column data movements and operations you perform. Using to many row groups on a file basically gets rid of all the benefits of the columnar storage. You could write row groups like this, but it’s advisable to research based on your needs the correct number of row groups first.
table = pqc.read_csv('loanfeatures.csv')
write = pq.ParquetWriter('test.parquet', table.schema)
for i in range(2):
write.write_table(table)
file = pq.ParquetFile('test.parquet')
print(file.num_row_groups)Another great part of pyarrow / parquet is the partitioning of the files themselves and how easy it can be. Basically what I’m doing here is saying I want parquet files split up by home ownership type. Other obvious examples would be year, month , day etc.
table = pqc.read_csv('loanfeatures.csv')
pq.write_to_dataset(table, root_path='test-folder', partition_cols=['home_ownership'])
Reading back a folder that contains parquet files is just as easy. Point your code at the base folder of whatever partition you want to read, or all of them in my case.
table = pq.read_table('test-folder')
print(table)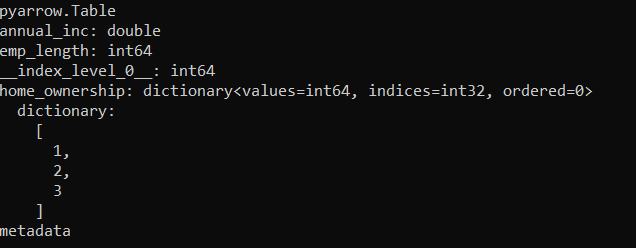
Hopefully you learned a little something about Parquet files and how awesome they are, think of them before you store something in flatfile or csv next time!
Thanks for your post!
It would be interesting to explain also the selective reading from the partitioned dataset…
dataset = pq.ParquetDataset(‘test-folder/’, filters=[(‘home_ownership’, ‘=’, ‘2’),])
Thanks! That would be very interesting indeed. That seems like it would open up possibilities to use parquet as part of Data Lake / Data Warehouse environment where you directly query the files for reporting/analytics.