Introduction to Designing Data Load Patterns.

When I think back many moons ago, to when I started in Data Engineering world … even though it went by many different names back in the olden days … I didn’t know what I didn’t know. All those years ago Kimball’s Data Warehouse Toolkit was probably the only resource really available at the time that touched on the general concepts that most “Data Engineers” at the time were working on. The field has come a long way since those days and changed for the better, it’s less often you see classic Data Warehouses running on legacy SQL Servers, with stored procedures with hundreds and thousands of lines of SQL code.
That had me thinking about designing data load patterns in the Modern Data Stack. I want to talk about general data loading patterns, how to design your data pipelines, at a high level, and the basic principles and practices that apply to 99% of all the transformations and data loads done by most Data Engineers.
Data Load Patterns – Why?

This isn’t going to be an exhaustive list by any means, but it should get us all going in the right direction, maybe we will learn something new, or be reminded of something we’ve been lax about. But why are they important, and who cares? Well, mostly because we are human, and we human programmers are happy to just sit down and write code without thinking. It’s what we are good at, just letting the code flow.
To be better at our craft, we learn to slow down, ask questions, and most importantly think before we just write.
Data Load Patterns are just another way of saying “we should do these things, or take this approach” when writing any new data pipeline or processing codebase/project/whatever. We want to be able to have a set of basic principles that broadly apply to the work we do, and act as guardrails, keeping us in the happy center and encouraging us to keep best practices in play.
Data Load Patterns – What.
Let’s go ahead and just list out our general-purpose Data Load Patterns.
- Understand source schema and data types.
- Understanding target schema and data types.
- What makes a record unique?
- Deduplicate records.
- Decide ELT/ETL approach.
- Understand the data filtering (
WHERE). - Basic data quality (
NULLs, etc). - Dataset enrichment (
JOINetc.). - Understand
MERGEof the data into Production and idempotency.
Data Load Patterns – How.
Understand source and destination schema and data types.
When working on a new Data Load, one of the first patterns we should look towards is understanding what both the source and sink data schema and types are. Data types and schemas are probably most notorious for being left ignored, and then coming back later to cause major problems and bugs.
It’s usually a mistake to start working on a data project before you fully understand the data you’re dealing with. The best thing to do is try to force data types and constraints upon the data, and the source and destination … either proving or disproving yourself.
- Understand each
columnand its’ correspondingdata type. - Understand what constraints relate to each column (
NULL vs NOT NULLor maybeVALUE IN LIST).
Example
Let’s use the Divvy free bike trip dataset as our example.
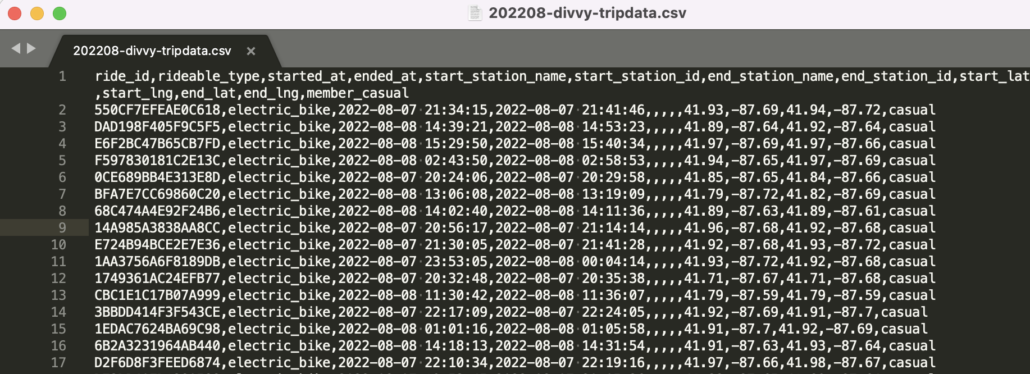
As previously discussed we should first try to whip out the schema and data types, including constraints based on what we see on the surface. It usually just makes sense to use some general DDL statements to do this, as it makes sense to the eye.
CREATE TABLE raw_trips (
ride_id STRING NOT NULL,
rideable_type STRING NOT NULL,
started_at TIMESTAMP NOT NULL,
ended_at TIMESTAMP NOT NULL,
start_station_name STRING,
start_station_id INT,
end_station_name STRING,
end_station_id INT,
start_lat FLOAT NOT NULL,
start_lng FLOAT NOT NULL,
end_lat FLOAT NOT NULL,
end_lng FLOAT NOT NULL,
member_casual STRING NOT NULL
);
ALTER TABLE raw_trips ADD CONSTRAINT rideabletype CHECK (rideable_type IN ('electric_bike', 'classic_bike'));
ALTER TABLE raw_trips ADD CONSTRAINT membercasual CHECK (member_casual IN ('casual', 'member'));
ALTER TABLE raw_trips ADD CONSTRAINT trips_pk PRIMARY KEY(ride_id);
Isn’t it amazing what we can learn about our data, before jumping into a project? It gives us a starting point to understand what we are dealing with. It’s an important step in the data load process, getting a basic understanding of the incoming data set.
In our example case, we found that our ride_id is the primary key, we have a mix of columns that can have NULLs and some that are NOT NULL. We have a mix of INTs and STRINGs, with a few TIMESTAMPs. Also, we could see a few columns could benefit from some CONSTRAINTs , where the values are always in a set.
We would of course go through the same exercise with the target destination data, depending on the file format, and the types of data enrichment that might happen, for example maybe we would add postal_codes or country or other such things.
What makes a record unique? Deduplicate records.

After you’ve understood the source(s) and sink(s) you are working with and have a general idea of the schema, data types look like, the next and most important step in designing a data load process is to grapple with the inevitability of duplicates in your data … whether it be your fault or someone else’s.
This idea of uniqueness and duplicates is fundamental to any data system, as that problem is the most common cause of downstream issues, be it analytics or exploding compute costs. You should always take these two steps when working on a data load.
- Find the
primary_key, if it be a single column or a combination of columns (composite) key. - Build the deduplication process immediately based upon the above.
The de-duplication step should be done first thing. Why? Because the minute you have duplicates exist the likely hood of those cascading downstream and causing issues with compute, joins during data set enrichment simply explode the data size. Don’t think you have duplicates? Then you haven’t been working with data long enough.
Example
In our above trips data set example, it was quite clear from the start that our trip_id would-be the unique definition, our primary_key if you will. This was easy and obvious, but many times it might not be. In lots of cases you might have to do some research to combine a set of columns, maybe even including the one you generate yourself ( like a timestamp ) to understand and obtain a reliable uniqueness constraint. Since we said trip_id is unique, the implementation of the duplicate reduction is going to depend on our underlying technology choices.
For the sake of argument, let’s say we are operating in a “Big Data” environment, and our Data Lake consists of files stored in s3, with Spark (maybe Glue, EMR, or Databricks) as our processing engine.
from pyspark.sql import DataFrame
def remove_duplicates(input_trips: DataFrame) -> DataFrame:
intermediate = input_trips.withColumn('row_num',
F.row_number().over(
Window.partitionBy("ride_id").orderBy(F.col("started_at").desc()))
)
deduped = intermediate.filter('row_num == 1').drop('row_num')
return output_dfIn our case we decide on a simple window function in Spark to remove duplicates, ordering ride_id by started_at time, and picking the first one. Of course, this is a contrived example, and we might even attempt to remove duplicates at multiple points in the process!
Decide ELT/ETL approach. Understand the data filtering (WHERE). Dataset enrichment (JOIN etc).

So now we’ve made it past the basic tasks of our data load design process, we have a better grasp of our source and destination data sets, we know about our columns, data types, constraints and the like. We’ve also gone a little deeper and understood the uniqueness of our data set, and how we plan on removing the duplicates in our data set. So we feel confident we have a “clean” dataset that now requires some sort of transformation.
The next step is to simply do what we are paid for as data engineers, and decide our data transformation process. I refuse to join the never-ending battle about ETL vs ELT, it gets old after a while. The point is you should decide what works best for your dataset and the technology that you are mostly likely forced to use, for better or worse. This is where you would take a few steps. At the same time, you should probably explore the filtering if any that needs to take place on the dataset. It’s important because filtering or not has a huge impact on the data compute and if we what data is available later on.
- Understand and list out the required transformations to the core data set.
- Understand and list out the required data enrichment steps (
joinsetc). - Decide
where( in memory or after storage) these transformations are going to take place and if you want physical storage of intermediate steps or not.- Do you store
rawdata somewhere, transform, the write again? - Do you load raw, transform, then write?
- Where do the filters get applied, and what filters?
- Do you store
Let’s try to contrive some of these ideas with our example dataset.
Decide ELT/ETL approach. For our example we decide that we are going to be reading raw data that is deposited into an s3 bucket, do all transformation, deduplication, and enrichment in memory, storing the final output back in s3. But, it’s important to remember that this is where a lot of thought has to be put in place, these decisions have serious consequences later on when folks as questions when we have to debug our system and data. Never underestimate the seriousness of these decisions.
Understand the data filtering (WHERE). Probably the sneakiest one of the data loading patterns in the filter(s) that may or may not be taking place during data ingestion and transformation. There has to be a balance between …
- At what point in the process should the
filtersbe applied (earlier the better). - Do we keep a record of what records were filtered out?
- How do we double-check our
filtersensure things are proceeding as expected?
Dataset enrichment (JOIN etc). Another sticky area of data loading patterns is the type and effect that data set enrichment can have on the base data set. The type and amount of data set enrichment can have serious side effects, both performance, and data quality-wise.
- Do you understand the impact of
LEFTvsINNERjoin dataset enrichment? Super serious point! - At what point should the dataset be enriched ( to reduce computation and complexity … aka at the last possible moment).
- How do we verify nothing has gone horribly wrong during enrichment?
Example (contrived).
Let’s say for the sake of argument that we want to enrich our trips dataset with the postal_code based on the city location of the start_lat and start_lng. We have a few decisions to make.
- What transformations are required prior to enrichment?
- Should the enrichment be
INNERorOUTER, aka what if a record can’t be enriched, what happens? - At what point in the process should enrichment happen?
base_trip_data = read_raw_trips()
transformed_data = transfrom_raw_data(base_trip_data)
data_with_city = convert_lat_lng_to_city(transformed_data)
postal_codes = pull_postal_codes()
data_with_postal = lookup_postal_with_left_and_default(data_with_city, postal_codes)Of course, this pseudo-code is imaginary, but you get the idea. In our code, we made a few decisions …
- Transform our data first, adding postal codes at the last possible minute (reduce complexity and compute).
- We had to convert
latlngto a city to allow this enrichment to happen. - We enriched the base dataset with postal codes via a
leftjoin and have adefaultvalue (maybeunknownor00000) for those records that can’t be enriched.
Basic data quality (NULLs, etc).
Probably one of the most common data load patterns that are left out to dry, thrown behind the barn, or whatever, is basic sanity and data quality checks. Yet this is a critical path when designing data load patterns. How can we ensure things are going as planned? Unit tests will never be enough, data changes, code changes, and bugs arise, it’s a rule of life.
The first thing to do is simply make a list of all the “truths” we expect about the dataset. Then our job is to encode these thoughts into our pipeline in some manner.
- Final checks for duplicates.
- Record counts to ensure sanity.
- Verify data enrichment is happening as expected, no record loss is occurring.
- Writing to pre-production before production.
The list could go on forever, but these basic ones should ensure your survival in the PR process. There are many new tools on the scene for Big Data quality like Great Expectations and Soda Core, choose your poison, even if it’s your own home-baked checks.
Example.
In our contrived data set example, maybe we write some yaml for a Soda data quality check. Checking to make sure we have records, that some of our constraints are acting as expected, and the list goes on.
table_name: tripdata
metrics:
- row_count
tests:
- row_count > 0
columns:
ride_id:
valid_format: string
sql_metrics:
- sql: |
SELECT COUNT(DISTINCT rideable_type) as rideable_types
FROM tripdata
tests:
- rideable_types = 2Understand MERGE of the data into Production and idempotency.
Last but not least, in our data load design patterns, is deciding how we are going to push our data in production, and how we can do it in a reliable and repeatable manner (idempotency), that doesn’t produce bugs when re-run. This is another topic that is usually left to the back-burner, but needs to be thought about at the beginning of the project, how can the data load pattern support the best possible outcome and promote our dataset into production without undue risk and possible bugs?
There are myriad ways to approach this problem.
- Don’t write directly to production.
- Write to staging and then run sanity and data checks.
- Is the
INSERTlogic idempotent (MERGEorINSERT and UDPATE) vs justINSERT.
Most of this logic implementation is highly correlated to the underlying data infrastructure and tools that are in use, but generally speaking, you can decide some things up front … like not writing directly into production until data quality and verification steps have taken place. Never use INSERT only logic, these types of decisions can be made earlier and designed into the process.
Musings on Data Load Patterns.
I think this is a tough topic. Why? Because there really aren’t any generally accepted patterns and practices that all Data Engineers follow, and the technology choices make the implementation so different from each other. I do think the Data Engineering community at large could do a better job of defining high-level data load patterns that are “preferred”, it’s hard to find resources that list the basic generally accepted principles that aren’t technology-focused.
I wish someone would write a book on this topic, giving the high-level options and comparing and contrasting those approaches. I would pay for that.