How Chuck Norris Proved Async in Python isn’t Worthy.

There are some things I will never understand. Async in Python is one of them. Yes, sometimes I use it, but mostly because I’m bored and we all should have some kind of penance. Async in mine. It’s slow, confusing, other people get mad at you when they have to debug your Async code. I’ve always wondered why anyone would choose a single Python process to do a bunch of work instead of …… more then one? I decided there is only one person who could solve the interwebs Async arguments, Chuck Norris.
Chuck Norris finally answers the Async vs No-Async problem.
Enter “The Internet Chuck Norris Database …. and API.” It’s a free HTTP API serving up Chuck Norris jokes. When you first run into Async in Python, it’s usually in some sort of HTTP context. I figured a good way for Chuck Norris to prove that Async isn’t worthy it just to show a simple example of why most of the time, Async isn’t the answer for the typical problem. (code on GitHub)
So let’s have good ole’ Chuck serve us up 50 random jokes, async’ly and also using ProcessPools and ThreadPools which have been around forever, and are easy and simple to use. Lets’ take a look at AsynChuck.
- AsynChuck is complicated.
- You typically have to find a Async compatible library for the job (easy for Requests not for other things.)
- The design pattern for Async makes programs more complicated and harder to read/write. And what do you get for that tradeoff? Nothing. Might as well go write Scala.
import asyncio
import aiohttp
from datetime import datetime
import json
class AsynChuck:
def __init__(self, number_of_jokes: int):
self.base_api_url = "http://api.icndb.com/jokes/random"
self.number_of_jokes = number_of_jokes
@staticmethod
def convert_to_json(response):
jsonified = json.loads(response)
return jsonified
async def fetch(self, session:object):
async with session.get(self.base_api_url) as response:
return await response.text()
async def get_em(self):
async with aiohttp.ClientSession() as session:
joke_number = 0
while joke_number <= self.number_of_jokes:
joke_number += 1
print(f"Working on Chuck Norris joke number {joke_number}")
html = await self.fetch(session)
json_response = self.convert_to_json(html)
if json_response["type"] == 'success':
print(json_response)
def main():
t1 = datetime.now()
MrNorris = AsynChuck(number_of_jokes=50)
loop = asyncio.get_event_loop()
future = asyncio.ensure_future(MrNorris.get_em())
responses = loop.run_until_complete(future)
t2 = datetime.now()
timer = t2 - t1
print(f'Process took {timer} seconds')
if __name__ == '__main__':
main()

AsynChuck took almost 10 seconds to give us 50 random jokes. The code above may look sorta simple, mmhmm, its a very simple and silly example, try writing something more complicated, figured out where you async and waits go, when to ensure futures and run the event loop. Trust me, speaking from experience it isn’t easy to do this inside a large complicated codebase where simplicity starts to matter.
Also, Async in most cases like this…. is just slow.
Non-Async Chuck is a less complicated dude, and faster.
Let’s try pool party Chuck. He’s always ready for a good time. For one this PoolChuck is easy to understand and follow. Clean and simple.
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
import requests
import json
from datetime import datetime
BASE_URL = "http://api.icndb.com/jokes/random"
def break_into_chunks():
listy = range(1,51)
chuck_number = len(listy)
final = [listy[i * chuck_number:(i + 1) * chuck_number] for i in range((len(listy) + chuck_number - 1) // chuck_number)]
return final
def convert_to_json(response):
jsonified = json.loads(response)
return jsonified
def chucks_backup(joke_number):
print(f"Working on Chuck Norris joke number {joke_number}")
html = requests.get(BASE_URL)
json_response = convert_to_json(html.content)
if json_response["type"] == 'success':
print(json_response)
def chuck_em(joke_numbers):
with ThreadPoolExecutor(max_workers=6) as Backup:
Backup.map(chucks_backup, joke_numbers)
def main():
t1 = datetime.now()
joke_chunks = break_into_chunks()
with ProcessPoolExecutor(max_workers=6) as PoolParty:
PoolParty.map(chuck_em, joke_chunks)
t2 = datetime.now()
timer = t2 - t1
print(f'Process took {timer} seconds')
if __name__ == '__main__':
main()
Did I mention PoolChuck only took 2.5 seconds to give us 50 jokes? Jezz. Well of course using multiple Python processes and thread pools was going to be faster. Don’t forget how much clean this code base is, way faster and way less complicated. That’s the kind of code you want your large codebase.
I also ran the at increasing joke increments, not surprisingly the performance difference between Pools and Async got wider as the workload increased.
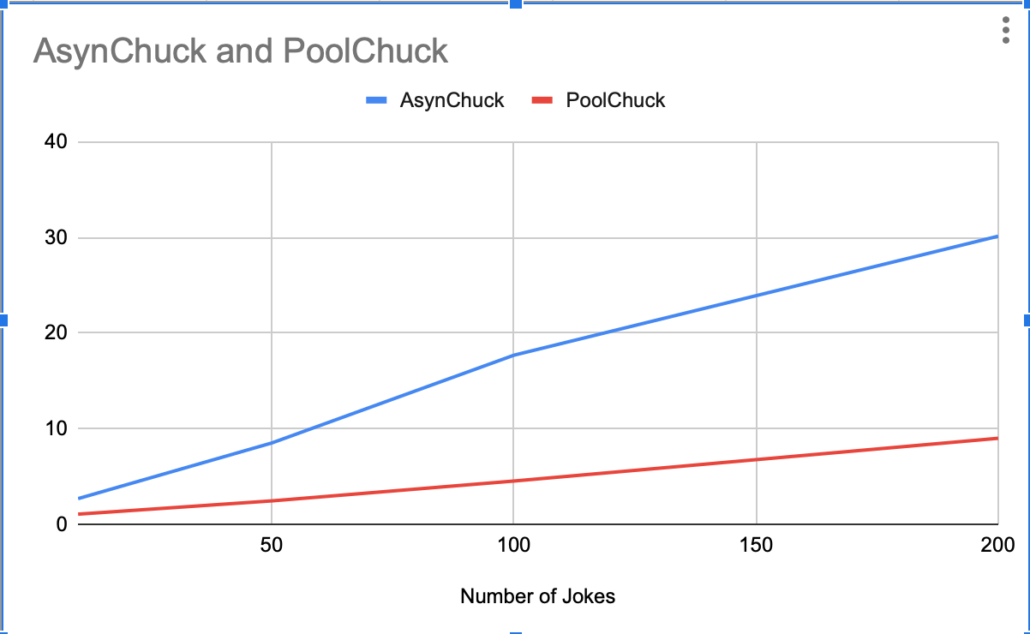
Conclusion
I’ve seen a lot of articles online recently arguing both sides of the async vs non-async packages approach. I’ve found the the answer is usually in-between. I also think that instead of doing something super complicated to prove a point, 80% of the time we are writing code that is trying to solve a relatively simple problem. I tried to use a very simple problem and workload to show that for data engineering at least, forget async, it will make your code more complicated and much slower.
Let’s hear it from the lurking and smarter than the rest async fans lurking out there in the deep interwebs.