Great Expectations with Databricks and Apache Spark. A Tale of Data Quality.

It still seems like the wild west of Data Quality these days. Tools like Apache Deque are just too much for most folks, and Data Quality is still new enough to the scene as a serious thought topic that most tools haven’t matured that much, and companies dropping money on some tool is still a little suspect. I’ve probably heard more about Great Expectations as a DQ tool than most.
With the popularity of PySpark as a Big Data tool, and Great Expectations coming into its own, I’ve been meaning to dive into what it would actually look like to to use Great Expectations at scale and answer some simple questions. How easy is it to get up and running with Spark, what’s the path of least resistance to getting some basic Data Quality checks in place in a data pipeline.
A Look Back in Time.

You know, the funny thing about Data Quality for most use cases is that what probably 90% of folks are looking for in a tool and DQ checks is not really that complicated. For most of the past two decades when RDBMS systems like SQL Server, Oracle, Postgres, and MySQL ruled the Data Warehousing world, and before the advent of Data Lakes and massive datasets, Data Quality was “easier.”
I mean constraints in databases have been around forever. The simple NOT NULL , the ever present PRIMARY and FOREIGN keys, the powerful CHECK constraint. These simple and powerful tools did the trick most of the time, they kept the lid on the proverbial pandora’s box of data problems.
Big Data Presents Problems.
But, the rise of Big Data, Spark, Data Lakes, Lake Houses, cloud storage changed all that. Gone were the days of simple and easy Data Quality checks (although with the rise of Delta Lake type tools constraints are making a comeback). Another issue is that all problems get magnified at scale, things are just harder when you’re talking about hundreds of terabytes+ of data. Small problems become big problems. It’s hard to correct issues, it’s hard to find issues, tooling is harder to find and use.
So, Great Expectations with Apache Spark? It’s like a dream come true.
Great Expectations + Apache Spark.

My hope is to find that Apache Spark and Great Expectations is match made in heaven. I want to see what kind of hurdles there are to jump and what decisions have to be made when pairing those two tools together. Nothing ever comes easy in this life, so I doubt this will be much different.
First, we have to know a little something about Great Expectations, and Spark, to see if we can anticipate some of the possible challenges we might encounter. I’ve previously written an Introduction to Great Expectations, a high level overview of the concepts. But let’s review them.
Quick Overview of Great Expectation concepts.
- Data Context
– Holds all configurations and below components for your project. - Datasource
– Holds all configurations related to your data source(s) and interacting with them. - Expectation
– The actual tests and “expectations” that describe your data. - Checkpoint
– The validation that will run against your data, reporting metrics etc.
This structure is created using the Great Expectations provided cli and generates a structure of yaml or Python files to hold the information.
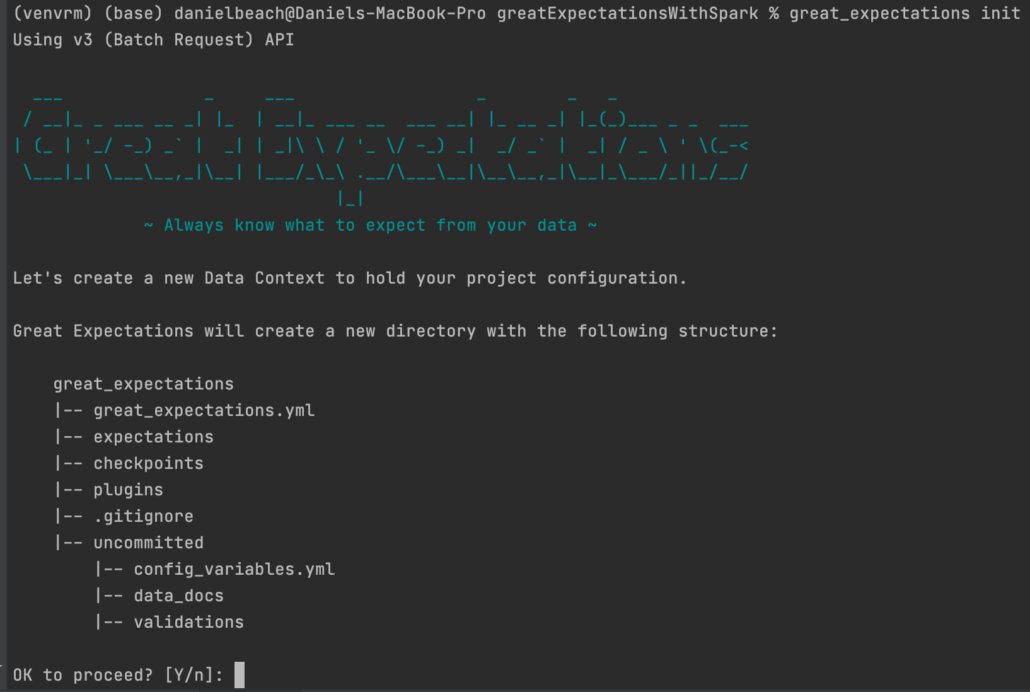
I encourage you to read over that previous blog post I mentioned so you get an idea of what a Great Expectation project looks like. It isn’t that simple, but it isn’t insurmountable either. What it really boils down to is that there is a lot of project setup and configuration to do, and my big question is how will my Spark cluster access all that project configuration required for Great Expectations?
Time will tell I guess. The best way and only way to figure this all out is going to be doing it.
Real-Life project with Databricks + Great Expectations with PySpark.
I want this to be as realistic as possible, so I can run into as many problems and troubles as anyone would when trying to implement some DQ with Apache Spark on their job. The best way to make things difficult is going to be to try to make this all work on Databricks with data stored in AWS s3. Databricks offers a free community edition, which we will use for this project, and I would suggest you give it a try, I mean its free.
It’s also trivial to setup a personal AWS account, and throwing a few CSV files into a s3 bucket isn’t going to cost you anything.
The Project
- Databricks with PySpark as our Data Pipeline tool.
- AWS
s3as our storage Data Lake / source. - some
CSVfiles to ingest. - Great Expectations project to apply DQ checks that can be accessed via our cloud Databricks environment.
How to solve the Data Quality Problem with Big Data, Spark, and Great Expectations.
So there’s plenty of ways to approach the problem of Data Quality with Great Expectations, and it has a lot to do with the Data Engineers on a project. How do you want to approach the problem? I’m always one to go for the simple approach. I load data, transform data, assert data ( aka Great Expectations), then load the data into its source.
Let’s get started. I will start the journey out in PyCharm … (this will need to be done on your Databricks cluster or job.)
>> pip3 install great-expectationsSo, because I’m lazy and I want to implement Great Expectations on top of Spark Databricks as fast as possible, and with as little effort as possible, I shall take the shortcut to get to that point. Probably not the recommended way, but the easiest in my opinion. Let me explain.
Great Expectations Components actually needed.

I’ve always been one who likes to go back to the basics. So, what do you actually need in code and configuration to actually assert and apply some Data Quality checks from GE to a Spark pipeline? As noted above, we need the following components.
- Data Context
- Datasource
- Expectation
- Checkpoint
I have two options in generating these components. First, I could follow the unbearably long and laborious documentation that guides you through connecting to and sampling the data, then generating Expectations for that data and applying the actual Checkpoint to check the data.
Or, I could simply try to understand the structure and layout of those components, and build them myself to fit exactly what I need, because, as a Data Engineer, shouldn’t I know my data better than anyone? You will find it no surprise that most the components of Great Expectations, simply are a bunch of configurations in JSON or DICT format, telling GE what to do.
I have confidence that you and me can write JSON and Python dicts that will meet our needs.
PySpark Pipeline on Databricks + Great Expectations Validation. It’s like finding the Holy Grail.

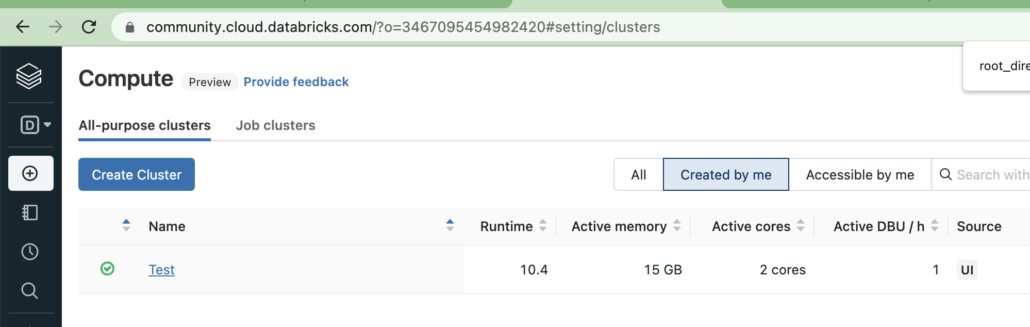
First things first, if we are writing a PySpark pipeline on Databricks and want to use Great Expectations … of course your cluster/job will need to be configured with the pypi library great_expectations , so pip install great_expectations. As you can see below the free Databricks Community clusters aren’t much, but they do the job for free! Enough to have some fun with.
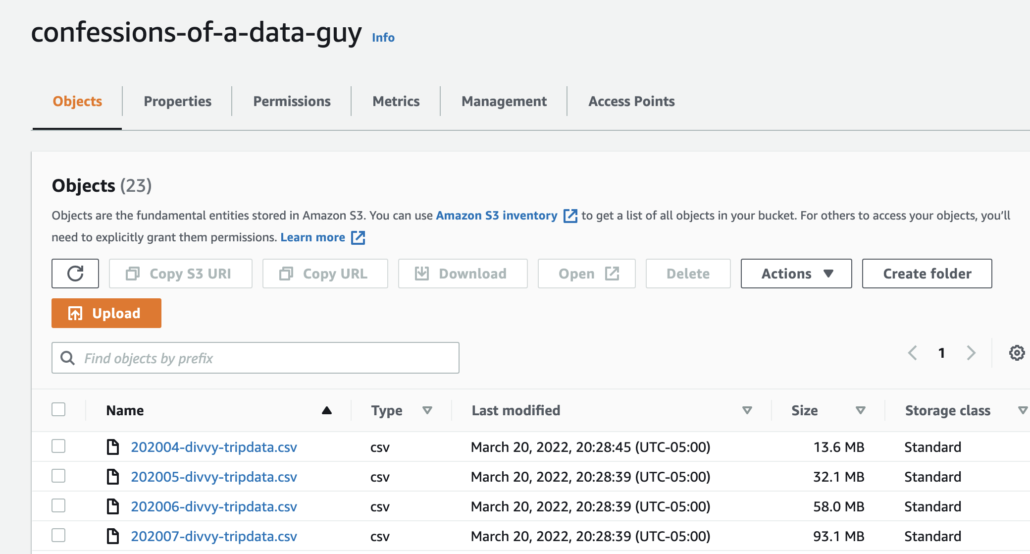
Next, I have some Divvy Bike Trips free open source data in my personal aws bucket.
With all that in place, we would start writing our PySpark pipeline and load the data into a DataFrame like any other day. Databricks Notebook is a great place to start.
Let’s get to the actual code. Start out with a bunch of imports and simply load up our data into a DataFrame.
import datetime
from pyspark.sql import SparkSession, DataFrame
import os
import json
from great_expectations.core.batch import RuntimeBatchRequest
from great_expectations.profile.json_schema_profiler import JsonSchemaProfiler
from great_expectations.data_context import BaseDataContext
from great_expectations.data_context.types.base import (
DataContextConfig,
FilesystemStoreBackendDefaults,
)
def main(root_directory: str = "/dbfs/great_expectations/") -> None:
spark = SparkSession.builder.appName('TestGreatExpectations').enableHiveSupport().getOrCreate()
df = spark.read.format("csv")\
.option("header", "true")\
.option("inferSchema", "true")\
.load("s3a://confessions-of-a-data-guy/*divvy-tripdata.csv")
So in real life you would probably have all sorts of transformations happening right, transform this, that, and the other thing. So at the end of the day you have a dataset sitting in a DataFrame that you want to validate before inserting in your Data Lake or Data Warehouse.
Data Context
The first component of Great Expectations you will need is a Data Context. Below is our method to do this.
def prepare_ge_context(root_dir: str) -> BaseDataContext:
data_context_config = DataContextConfig(
store_backend_defaults=FilesystemStoreBackendDefaults(
root_directory=root_dir
),
)
ge_context = BaseDataContext(project_config=data_context_config)
return ge_contextThis Context is like the overarching over-lord for GE, it holds all information, and is typically stored in a yaml file. In the above Python function we are creating a new Context on the fly. Why? Because I already know what I want and need. In production with lots of different DataFrames and Data Sets to validate we might have a more complicated Context with all sorts of configurations.
So now we can call this in our script. Ignore the root directory, if we were saving our crap we would use it, everything I’m doing is on the fly at runtime. But if we wanted to save our validation results etc they would end up at that location. (This can be configured to be a s3 bucket or whatever you want.)
root_directory = "/dbfs/great_expectations/"
# Prepare Great Expectations / storage on Databricks DBFS
ge_context = prepare_ge_context(root_directory)Ok, so Context in place.
Data Source
Next is something called a DataSource, which needs to be added to the context.
# Prepare DataFrame as Data Source Connector for GE.
ge_context.add_datasource(**prepare_get_datasource())Here is the guts of our prepare_get_datasource function.
def prepare_get_datasource(dname: str = 'DataFrame_Trips_Source') -> dict:
ge_dataframe_datasource = {
"name": dname,
"class_name": "Datasource",
"execution_engine": {"class_name": "SparkDFExecutionEngine"},
"data_connectors": {
"DataFrame_Trips_Data_Connector": {
"module_name": "great_expectations.datasource.data_connector",
"class_name": "RuntimeDataConnector",
"batch_identifiers": [
"trips_source",
"divvy_bike_trips",
],
}
},
}
return ge_dataframe_datasourceAll this crud is basically telling Great Expectations that we are using Spark as an execution engine, that our Data Connector is a RuntimeDataConnector , aka our Spark DataFrame. This is powerful in GE for other uses, it can be configured to connect to every data source under the sun.
CheckPoint
Next in our line of things to do is prepare a CheckPoint. This is the work-horse of GE, it says to take this Data and Validate against these points. We of course add that check to our Context once created.
# Prepare Checkpoint
trips_check = prepare_checkpoint()
ge_context.add_checkpoint(**trips_check)The guts of our prepare_checkpoint() method looks like this.
def prepare_checkpoint() -> dict:
ge_trip_data_checkpoint = "trip_check"
checkpoint_config = {
"name": ge_trip_data_checkpoint,
"config_version": 1.0,
"class_name": "SimpleCheckpoint",
"run_name_template": "%Y%m%d-%H%M%S-trip-run",
}
return checkpoint_configOnce we have a checkpoint prepared we can call the method add_checkpoint from our Context.
Expectations and Validations
This brings us to an important topic, creating a JSON or DICT of our expectations or validations we want to apply to our data. Below we are taking our manually created Expectations and saving them into our Context.
# create and save expectation suite
profiler = JsonSchemaProfiler()
suite = profiler.profile(trips_expect, "bikes")
ge_context.save_expectation_suite(suite)Now, there are two ways to accomplish what I did above. If you’re like me and already know the data and what you want to validate, you can simply write out those expectations in the expected format. Otherwise of course GE provides a cli and Notebooks that will walk you through connecting to the data and creating those expectations for you … and then dumping out what you created in the required format.
- Manually write our
JSONor PythonDICTin required format with your neededExpectationsthat match your dataset. - Walk through the creation of suite of
Expectationsvia the CLI or Notebook provided by GE.
I know what simply expectations I want for my sample data, so I simply wrote it myself. Like what I expect the columns to be, and how many rows there should be.
trips_expect = {
"properties": {},
"type": 'object',
"data_asset_type": '',
"expectation_suite_name": "bikes",
"expectations": [
{
"expectation_type": "expect_table_columns_to_match_ordered_list",
"kwargs": {
"column_list": [
"ride_id", "rideable_type", "started_at", "ended_at", "start_station_name", "start_station_id",
"end_station_name", "end_station_id", "start_lat", "start_lng", "end_lat", "end_lng", "member_casual"
]
},
"meta": {}
},
{
"expectation_type": "expect_table_row_count_to_be_between",
"kwargs": {
"max_value": 1000000,
"min_value": 1000
},
"meta": {}
}
],
"ge_cloud_id": '',
"meta": {
"citations": [
{
"batch_request": {
"data_asset_name": "trip_data_batch",
"data_connector_name": "DataFrame_Trips_Data_Connector",
"datasource_name": "DataFrame_Trips_Source",
"limit": 1000
},
"citation_date": "2022-06-02",
"comment": "Created suite "
}
],
"great_expectations_version": "0.14.10"
}
}Run Batch get Validation/Expectation Results
This is really the crux of the matter, here is where you can make GE powerful, add all sorts of validations. And now, finally, you would put all that hard work together and actually pass your Spark DataFrame over into your runtime GE batch and run the Checkpoint to get the validation results.
# Prepare Batch and Validate
trips_batch_request = prepare_runtime_batch(df)
validation_results = run_checkpoint(ge_context, trips_batch_request)
print(validation_results)The code for the methods prepare_runtime_batch and run_checkpoint are as follows.
def prepare_runtime_batch(df: DataFrame):
batch_request = RuntimeBatchRequest(
datasource_name="DataFrame_Trips_Source",
data_connector_name="DataFrame_Trips_Data_Connector",
data_asset_name="trip_data_batch", # This can be anything that identifies this data_asset for you
batch_identifiers={
"trips_source": "trips_source",
"divvy_bike_trips": "divvy_bike_trips",
},
runtime_parameters={"batch_data": df}, # Your dataframe goes here
)
return batch_request
def run_checkpoint(context, batch_request):
checkpoint_result = context.run_checkpoint(
checkpoint_name="trip_check",
validations=[
{
"batch_request": batch_request,
"expectation_suite_name": "bikes",
}
],
)
return checkpoint_resultYou can see the methods are fairly simply and straight forward.
Get Results
All that is left is to inspect the output results from our Great Expectations set.
{
"run_id": {
"run_time": "2022-06-02T21:23:55.646402+00:00",
"run_name": "20220602-212355-trip-run"
},
"run_results": {
"ValidationResultIdentifier::bikes/20220602-212355-trip-run/20220602T212355.646402Z/a1eb39146765e0288a6f117ba727ed49": {
"validation_result": {
"evaluation_parameters": {},
"meta": {
"great_expectations_version": "0.15.8",
"expectation_suite_name": "bikes",
"run_id": {
"run_time": "2022-06-02T21:23:55.646402+00:00",
"run_name": "20220602-212355-trip-run"
},
"batch_spec": {
"data_asset_name": "trip_data_batch",
"batch_data": "SparkDataFrame"
},
"batch_markers": {
"ge_load_time": "20220602T212355.667609Z"
},
"active_batch_definition": {
"datasource_name": "DataFrame_Trips_Source",
"data_connector_name": "DataFrame_Trips_Data_Connector",
"data_asset_name": "trip_data_batch",
"batch_identifiers": {
"trips_source": "trips_source",
"divvy_bike_trips": "divvy_bike_trips"
}
},
"validation_time": "20220602T212355.727561Z"
},
"results": [],
"success": true,
"statistics": {
"evaluated_expectations": 0,
"successful_expectations": 0,
"unsuccessful_expectations": 0,
"success_percent": null
}
},
"actions_results": {
"store_validation_result": {
"class": "StoreValidationResultAction"
},
"store_evaluation_params": {
"class": "StoreEvaluationParametersAction"
},
"update_data_docs": {
"local_site": "file:///dbfs/great_expectations/uncommitted/data_docs/local_site/validations/bikes/20220602-212355-trip-run/20220602T212355.646402Z/a1eb39146765e0288a6f117ba727ed49.html",
"class": "UpdateDataDocsAction"
}
}
}
},
"checkpoint_config": {
"class_name": "Checkpoint",
"name": "trip_check",
"site_names": null,
"module_name": "great_expectations.checkpoint",
"batch_request": {},
"evaluation_parameters": {},
"notify_on": null,
"template_name": null,
"config_version": 1.0,
"run_name_template": "%Y%m%d-%H%M%S-trip-run",
"profilers": [],
"action_list": [
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction"
}
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction"
}
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
"site_names": []
}
}
],
"slack_webhook": null,
"notify_with": null,
"expectation_suite_ge_cloud_id": null,
"runtime_configuration": {},
"validations": [],
"expectation_suite_name": null,
"ge_cloud_id": null
},
"success": true
}After all that work you can see in our results that our DataFrame passed the validation of having the correct columns and number of rows. "success": true. You can inspect the full code on GitHub.
Musings on Great Expectations and Databricks with PySpark.
It’s clear that Great Expectations with a tool like Databricks is powerful and definitely underutilized in todays Big Data world. You hear about it, but not enough. It’s clear to me why.
Quite simply, it’s not really a walk in the park to setup Great Expectations with a tool like Databricks and Spark, especially not for production use. My on-fly-approach would have be changed a little for production type usage. There are so many pieces and components to Great Expectations, when walking through the documentation it’s almost overwhelming the steps necessary to get an actual working setup.
Hence my shortcut.
I personally think the time spent setting up GE correctly, going through all the learning and configuration would pay itself back in no time. Having a good configuration being able to run a myriad of simple and complex data validations at any point in your data pipelines, at scale, it like the Holy Grail. And it has arrived in the form of Great Expectations + Databricks. Any good quest worth you time is going to require blood, sweat, and tears. Great Expectation will extract some of your tears in the beginning, that is for sure.
What helped me get up and running with GE was to use SparkDFDataset class. You can then quickly create validations and suites using the dataframe api. It’s a good starting point to building a much larger project.
https://docs.greatexpectations.io/docs/guides/miscellaneous/how_to_quickly_explore_expectations_in_a_notebook#steps
Thanks for the tip, will check that out!!