Getting My Spark On

There sure has been a lot of kerfuffle around Spark lately. Spark this Spark that, Spark is the best thing ever, and so on and so forth. I recently had some small exposure to PySpark when working on a Glue project, at the time a lot of the functions reminded me of Pandas and I’ve been trying to find time to explore Spark a little more.
What better way to try out Spark then to use Docker. My experience with Docker has been limited, but it seemed like a great tool, espeically when playing around with new technology that you know nothing about.
docker pull ubuntu docker run -it [image-id] bin/bash apt-get update apt-get install openjdk-8-jdk apt-get install python2.7 python-pip apt-get install wget
Basically pull down a Ubuntu image from the Docker Hub, run it and open its’ bash command line.
The first pre-req for installing Spark is going to be Java. Don’t make the mistake of getting the latest version of Java, a lot of tutorials tell you to use …
apt-get install default-jdkThis seems to be incorrect, when I did this I was able to install Spark fine but I was getting strange errors when trying to submit a job to run. After a little research it seems like Java 8 is more stable with Spark.
Installing wget above will let us pull down the Spark install. The following will download Spark, unpack it, and link it.
wget https://archive.apache.org/dist/spark/spark-2.3.0/spark-2.3.0-bin-hadoop2.7.tgz tar xvzf spark-2.3.0-bin-hadoop2.7.tgz ln -s spark-2.3.0-bin-hadoop2.7 spark
Next I needed to download VIM, something I’m not the biggest fan of, but it’s easy to modify files via the command line.
apt-get install vim vi ~/.bashrc
The vi command lets us modify the .bashrc file and insert the following lines at the bottom.
SPARK_HOME=/LinuxHint/spark export PATH=$SPARK_HOME/bin:$PATH
Alright, ready to go now. So, this wan’t so obvious as first, but as of recently all external PySpark scripts must be submitted via….
spark/bin/spark-submit
Next, I need something easy to try out for my first script. I wrote this little piece to download a txt file that I could mess with. Of course the great St. Augustine would make for a interesting read.
import urllib2 url='https://www.ccel.org/ccel/schaff/npnf101.txt' response = urllib2.urlopen(url) with open('StAugustine.txt', 'w') as f: f.write(response.read())
This downloaded a text file of Confessions.
from pyspark import SparkContext sc = SparkContext("local", "App Name", pyFiles=[]) text_file = sc.textFile("./spark/StAugustine.txt") counts = text_file.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b) counts.saveAsTextFile("./spark/counts.txt")
There is a nice example of a simple word count on the Apache Spark website. Easy enough, so just submit the file….
spark/bin/spark-submit sparktest.py
Run that and out pops a directory with a results file.
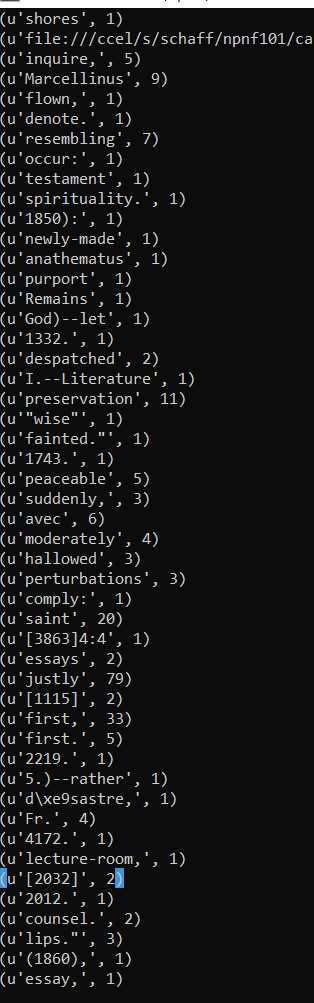
So, that’s the extent of my exploring Spark, gotta start somewhere right? The documentation seems good, and I know next to nothing about configuration, RDD’s etc etc, but the first step is getting it running and being able to submit a job right? So till next time.