Exploring Delta Lake’s ZORDER, and Performance. On Databricks.

I think Delta Lake is here to stay. With the recent news that Databricks is open-sourcing the full feature-set of Delta Lake, instead of keeping the best stuff for themselves, it probably has the most potential to be the number one go-to for the future of Data Lakes, especially within those organizations that are heavy Spark users.
One of the best parts about Delta Lake is that it’s easy to use, yet it has a rich feature set, making it a powerful option for Big Data storage and modeling. One of those features that promise a lot of performance benefits is something called ZORDER. Today I want to explore more in-depth what ZORDER is, when to use it, when not to use it, and most importantly test its performance during a number of common Spark operations.
What is Delta Lake and what is ZORDER in that context?
Let’s set the stage first.

What is Delta Lake?
I’ve written a few articles in the past about what is Delta Lake, and other features and facts about Delta Lake.
“Delta Lake is an open-source storage layer that brings ACID transactions to Apache Spark™ and big data workloads.”
Delta docs
Delta Lake is the Big Data storage layer that extends and provides features that were typically reserved for relational databases (SQL Server, Oracle, Postgres) at scale.
It’s a tool that is mostly used in conjunction with Apache Spark, specifically SparkSQL. Think of it as an abstraction on top of just storing files in some cloud storage bucket like s3. It provides …
- ACID Transactions
- CRUD operations (INSERT, UPDATE, DELETE, etc.)
- Constraints
This is only scratching the surface, read the docs for the rest, which is a lot. To sum it up, Delta Lake usually holds massive amounts of data, way more than your typical relational databases … it’s not unnormal to have hundreds of TBs or more, stored in Delta Lake. Of course with this “ease of use” technology meets Big Data, this is going to be a problem for some people.
This means that certain concepts and performance features are going to be extremely important. For example, Partitions are central to Delta Lake and data modeling therein. That brings us to a feature called ZORDER.
ZORDER in Delta Lake.

After all that huff-a-luff, it’s time to get down to the brass tacks. What is ZORDER and why is it important?
“Colocate column information in the same set of files.”
Databricks docs
Ok, so if a Delta Lake or Delta Table is just a bunch of (parquet) files sitting somewhere with hundreds of TBs of data, having certain sets of data “colocated” or stored next to each other seems like an important thing. Why? Well if you have a ton of data, and you need certain pieces of data, do you want to read every single piece of data to find what you need? Well, you could, but it would be faster not to.
I try to think of an ZORDER on data to be a step layered below Partitions. If you are unfamiliar with Partitions I highly recommend you spend some time reading about this topic. Let’s try to make this concept a little more concrete with an example.
We have a bunch of customer order data. We get many millions of records every day. We partition this order data in our Delta Table by date, because that is our data access pattern.
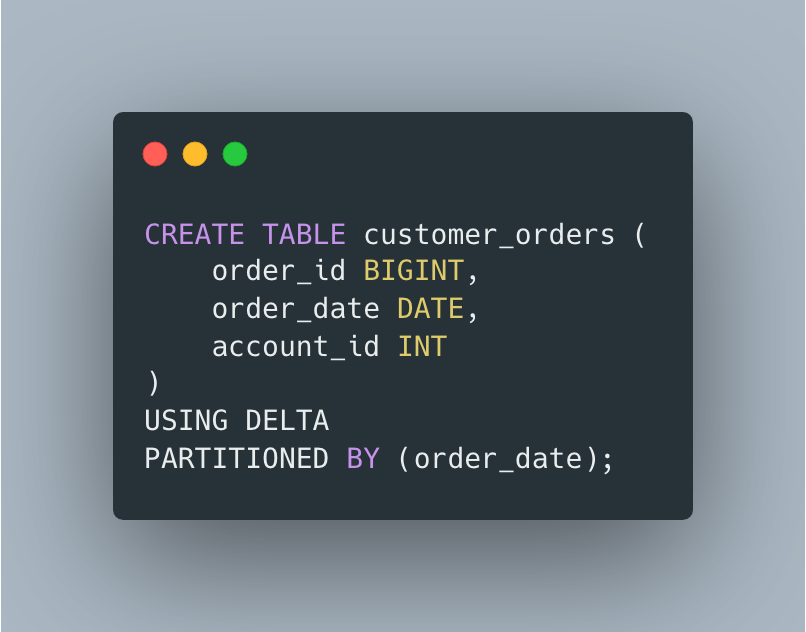
In theory, our files inside a particular day partition might look something like this. A few different files inside our partition, with account_id ‘s scattered randomly in those files.
You might not think this is a big deal, but imagine if you have a large dataset, and you are scanning over multiple partitions, say a year’s worth of data for a particular account_id, then what? Well of course ZORDER is going to make a difference right?
” Co-locality is used by Delta Lake data-skipping algorithms to dramatically reduce the amount of data that needs to be read”
Databricks docs
Sure, if you’re looking for data point X and you put all those data points in a file or file(s) things are going to be much quicker, especially as the data gets larger, that difference should be more pronounced.
When should you use ZORDER?
So, it’s all fine and dandy, ZORDER sounds like a great feature to use for Delta tables, but when should you actually use it? How do I know what columns to use and does the data inside those columns make a difference?
Why yes, yes it does. There are two main concepts that make a particular column(s) or data points effective and good candidates for ZORDER.
- High cardinality (lots of distinct values).
- Data points found in
WHEREclauses.
ZORDER helps with data-skipping, aka when you’re looking for something, that of course is usually called a WHERE clause. Also, the high cardinality, with lots of distinct values is going to make ZORDER much more effective.
Note: “By default Delta Lake on Databricks collects statistics on the first 32 columns defined in your table schema.” aka only ZORDER columns that have stats.
ZORDER in the real world. aka Performance.

I guess the real question is, can we test this ZORDER in real-life on Databricks and see a difference in performance? Luckily for you and me, Databricks provides a free community account for anyone to use and sign up for. We will use one of these free accounts to try out ZORDER, by taking a few steps.
They provide free small clusters (15GB / 2 cores) at no cost. Very nice.
- Create a Delta table
- Generate a lot of data to fill said Delta table.
- Run a
SparkSQLquery against Delta table withoutZORDER OPTIMIZEandZORDERthat Delta table (maybe more than once 🙂 )- Compare performance
Create Delta Table.
Task one, create a sample Delta table to that we can mess with. We will as always use the free Divvy Bike trip data set. I already have this data staged in my personal and free aws account. We will be using about 1.5GB of data, or 8.9 million records. Not large but maybe enough to see some difference in using ZORDER?
UPDATE:
I upgraded the size of the dataset by ingesting a lot more of the Divvy files. We now have 18,067,360 records or about 2.8GB, still small but slightly larger. It will be interesting to see if the performance of ZORDER increases.

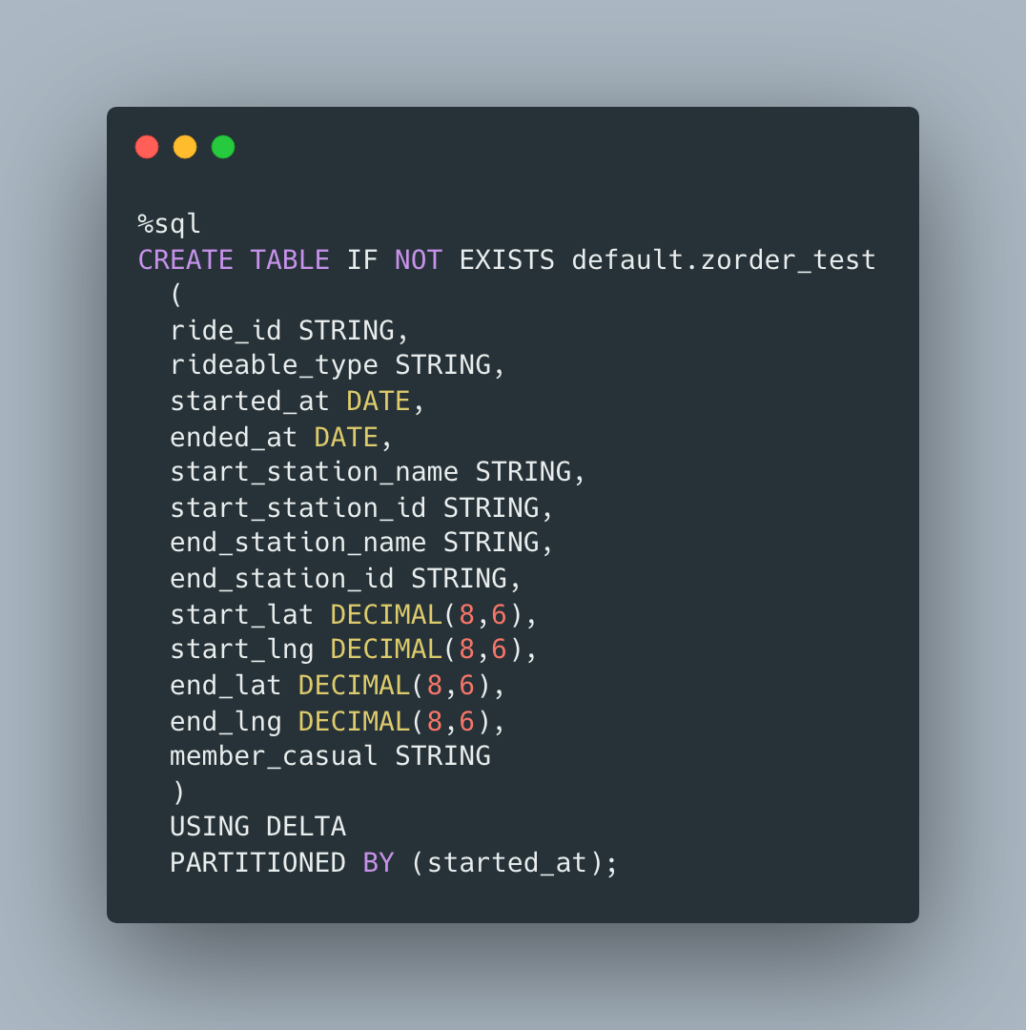
Simple data, and we can probably make it work for our purposes. Let’s make our table to simply hold all the data, partitioned by started_at DATE, this seems reasonable. We will not ZORDER this table.
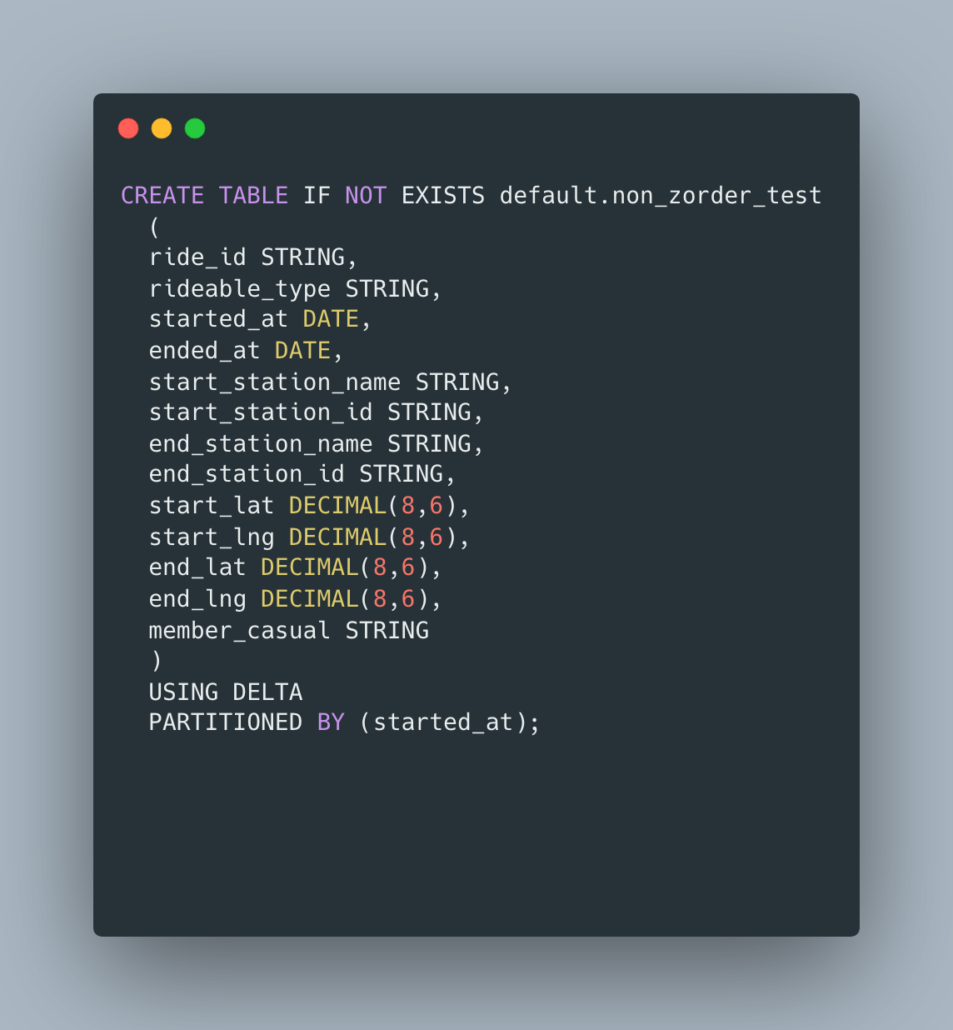
Load Data into Delta Table
Next, we are going to write a simple PySpark script to load our data into the Delta table. We are working with about 8,929,238 records (UPDATED: now 18 million records), so pretty small but hopefully big enough for our little cluster to do a performance test.
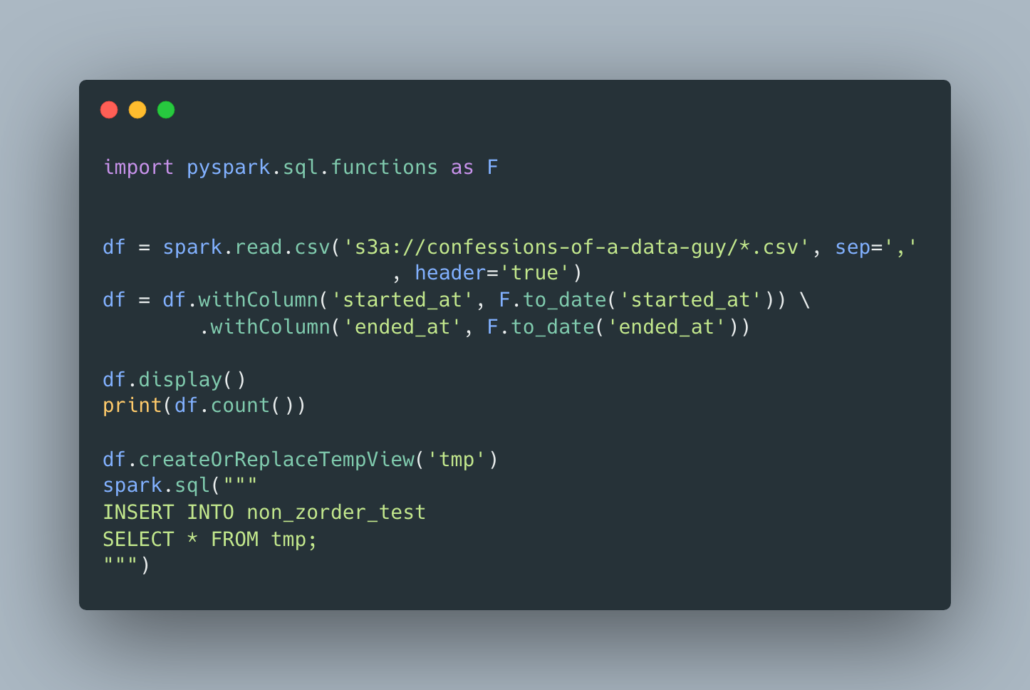
It worked, took a little over 4 minutes to load the data on the 8 million records and about 14 minutes on the 18 million.
Of course, we must run OPTIMIZE to compact our new table.
This is the result of the OPTIMIZE command. Started with 244 files, and now we have 122. (319 files for the 18 million records).
{"numFilesAdded": 122, "numFilesRemoved": 244, "filesAdded": {"min": 452618, "max": 1180077, "avg": 834011.0163934426, "totalFiles": 122, "totalSize": 101749344}, "filesRemoved": {"min": 14944, "max": 1155860, "avg": 421462.12295081967, "totalFiles": 244, "totalSize": 102836758}, "partitionsOptimized": 697, "zOrderStats": null, "numBatches": 1, "totalConsideredFiles": 819, "totalFilesSkipped": 575, "preserveInsertionOrder": true, "numFilesSkippedToReduceWriteAmplification": 0, "numBytesSkippedToReduceWriteAmplification": 0, "startTimeMs": 1657156632768, "endTimeMs": 1657156778414}Performance Testing without ZORDER
Ok, so now we have our Delta table non_zorder_test filled with our 8 (and now 18 million) million records, partitioned by started_at. What would be a common-sense query that might run on this data, that would benefit from a ZORDER, but that we haven’t added yet?
Let’s try to find all start_station_name column data points that equal Aberdeen St & Jackson Blvd. Here is the query.
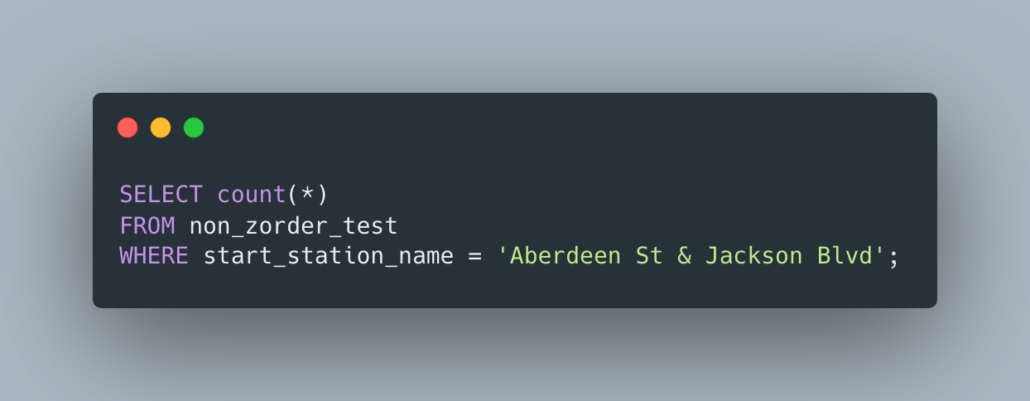
It took 1.04 minutes to scan all the files and find the rows on the 8 million rows, and 1.23 minutes on the 18 million records.
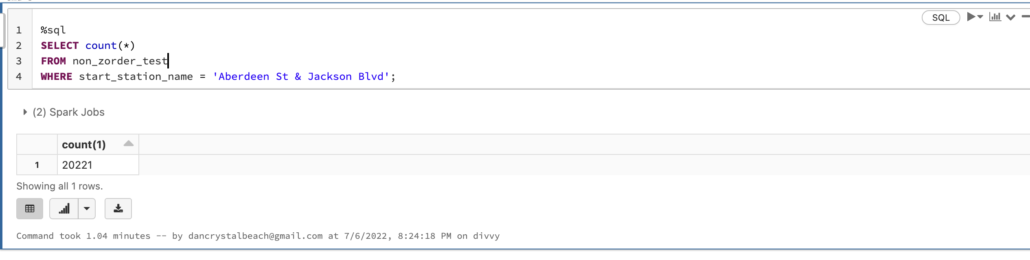
Performance Testing with ZORDER
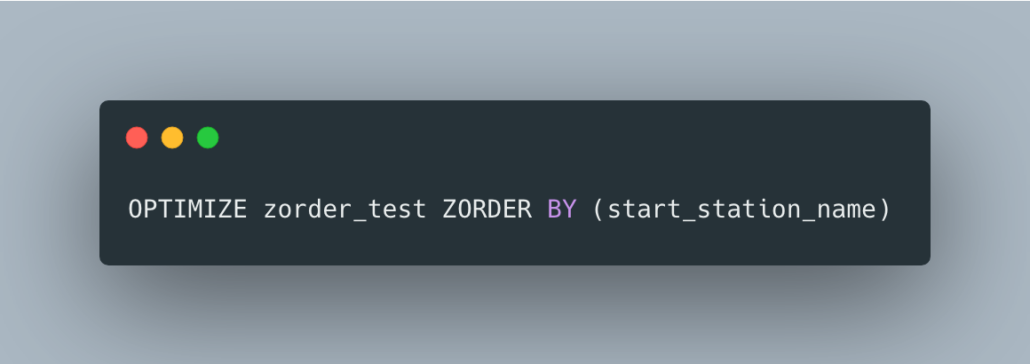
Ok, so let’s add the ZORDER to this table and see what happens. I want to be fair as possible, so I’m recreating the same table with a different name, and I will re-run the OPTIMIZE with additional ZORDER after inserting the same records.
I ran the exact same load script to insert into the new table zorder_test. The OPTIMIZE command is not idempotent and so we will run this OPTIMIZE command with the included ZORDER about 3 times.
And run another SQL query.
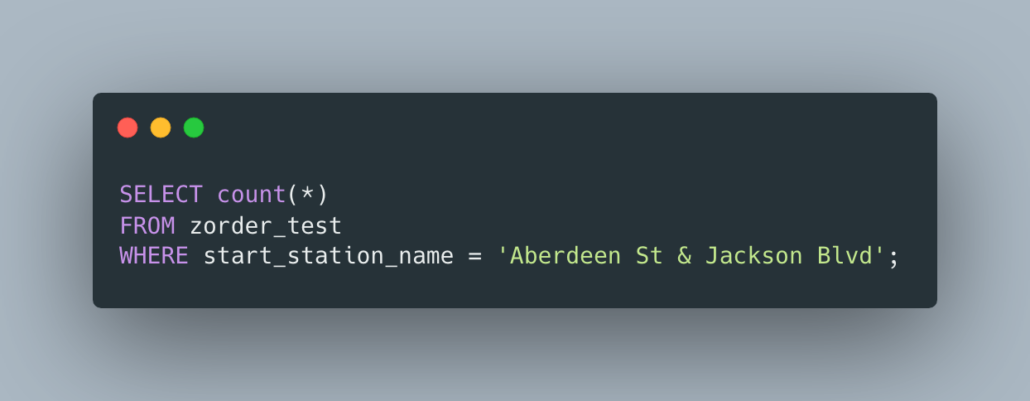
The command took 54 seconds on the 8 million records, and 1.19 minutes on the 18 million records.
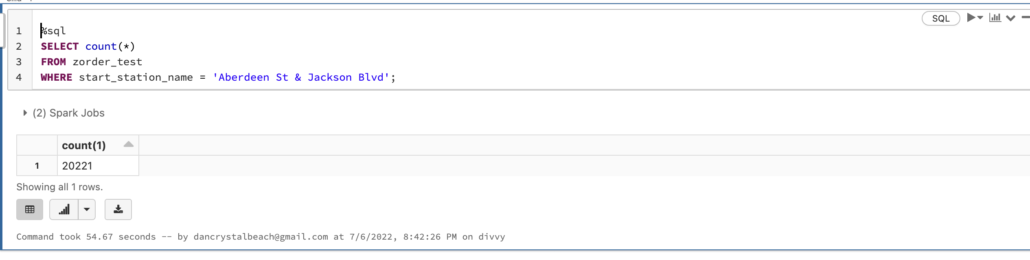
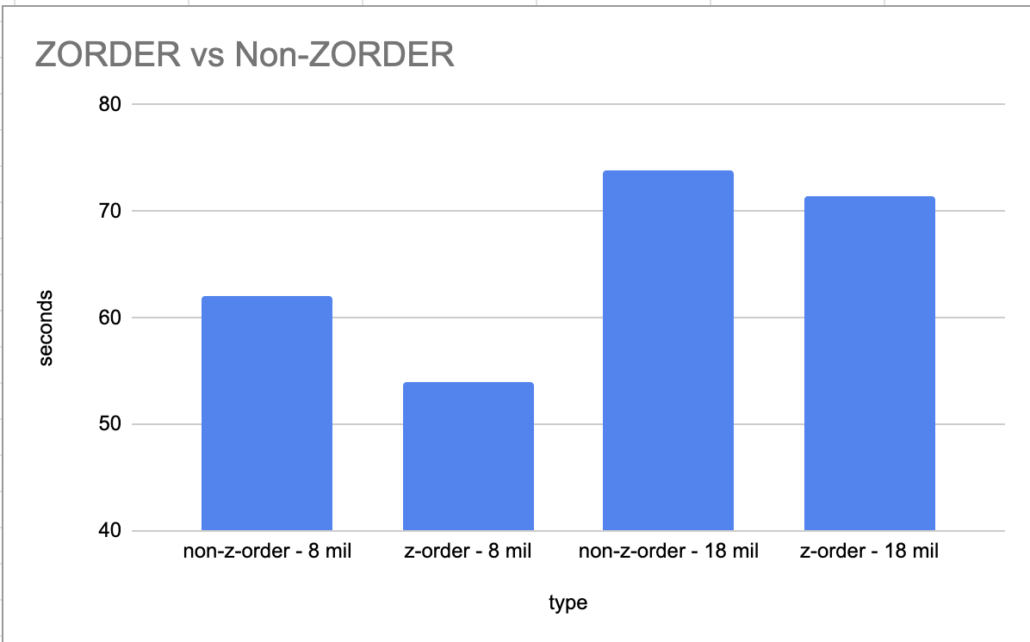
Not much of a difference there uh. 62 seconds without ZORDER compared to 54 with, about a 13% performance improvement on 8 million records.
And on the 18 million records it was 1.23 (73.8 seconds) minutes vs 1.19 minutes (71.4 seconds) with is only 3.3% performance gain. What gives??
I guess at scale with billions of records this might add up and become more of a pronounced performance improvement, maybe it scales with data size? Who knows.
Musings on ZORDER
I’m not sure what I was expecting, of course, marketing material always makes things seem like the best new thing. I guess it’s easy enough to add ZORDER to the OPTIMIZE command that is probably running on most Data Lakes, it’s not like it takes a lot of effort. The blog from Databricks makes this seem to be the case, that data skipping becomes essential at the TB and PB scale, which seems to be logical.
If we can see a 13% performance increase on a tiny data set like 8 million records, I suppose with billions of records or more, this could turn into a real performance boost. It is confusing that increasing to 18 million records that the performance increased, decreased to 3.3%. It makes me think that you need billions of records to see a reasonable increase in performance? And why hasn’t Databricks made this clear?
I suppose I could be do something very wrong, but it isn’t very obvious to me.
Great blog. I did some tests as well on data with billions of rows but yhe results weren’t very impressive. I guess i was expecting alot as you mentioned.
Btw how long did it take for your optimize commands with z order ?
agreed, very disappointed. Longer then it should have. with the 18 million records i think it was like 15 minutes +, but that was the first run.
You could also try the ANALYZE TABLE statement to see if it improves the data skipping. I wrote a utility not too long ago that provides recommendations for zorder columns based on user queries. If you search “auto_zorder” on github you will find it.
I actually did run `ANALYZE` table before and after I ran the ZORDER. Should have noted that in the blog. Auto zorder is great! Databricks has very little useful in-depth information on ZORDER, so its confusing what the best practices.