End-to-End Pipeline Integration Testing for Databricks + Delta Lake.

The testing never ends. Tests tests tests, and more tests. When it comes to data engineering and data pipelines it seems good practices are finally catching up after years. In the past, the data engineering community took a lot of heat, and rightly so, for not adopting good software engineering principles, especially in data pipelines.
In the defense of many data engineers, because of the varied backgrounds people come from, some were never taught or realized the importance of good software design and testing practices. Sure, it always “takes more time” upfront to design data pipelines with code that is functional and unit-testable, and worse, able to be integration tested from end to end. It requires some foresight and thought in both data architecture and pipeline design to enable complete testability.
Integration testing end-to-end in an automated manner is a tough nut to crack. How can you do such a thing on massive pipelines that crunch hundreds of TBs of data? With a little creativity.
Componets for Integration Testing on Databricks + Delta Lake.
While there might be many ways to solve the problem of end-to-end integration testing on big data pipelines, I’m going to give you a real-world example of such a task that was accomplished for a large number of pipelines written with PySpark on Databricks and Delta Lake. Integration testing data pipelines end-to-end requires a few different approaches, and it starts with architecture and separation of concerns, with a little automated mixed-in.
Here is a list of components required for automated end-to-end integration testing.
- CircleCi or some other workflow tool integrated with your GitHub or GitLab.
- Unique environment for Airflow specifcally for Integration testing.
- Schema separation most likely in the form of a database for your Delta Tables (aka clones).
- Sample data in s3 that is refeshed daily.
- Slack integration.
- Configurable codebase this capable of handling different environments seamlessly.
Well, now that I list that all out, it looks a little more difficult than it is. Never fear, it isn’t as bad as it looks! This picture should make it a little clear.
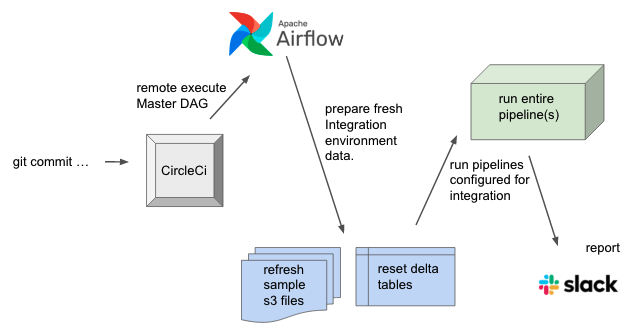
This strategy for integration testing relies heavily on a few key areas.
Separation of Environments
There are some common hurdles that have to be crossed when trying to enable an automated end-to-end integration testing environment for your data pipelines. One of the biggest concerns is testing the entire pipeline in a manner that is an exact replica of all aspects of production, without running anything in production.
Create Environments and Componets for Integration Testing
The first thing you can do to make end-to-end integration testing easier is to have a clone of your environments and resources for integration testing. In our case above this includes …
- s3 buckets for integration testing only
- MWAA Airflow Environment
- Delta Lake tables cloned in and separated with
databaseschema that is only for integration testing.
Having these resources and environments specifically for integration (and not crossing over to use development or production) ensures that you can automate the entire workflow and not worry about “someone” making changes or introducing bugs with development work.
Note: I suggest setting up some automation to “refresh” your s3 data daily, pulling some new files over from production into your integration testing s3 buckets so your emulating production closely.
Identify Integration Environment Pre-Processing Steps.
The next step in the journey is to identify for the use case, what pre-processing steps need to take place to have a “fresh” or “clean” run for every new integration pipeline test. In our case of Databricks + Delta Lake pipelines, there are two main areas of concern …
- fresh raw data, in small amounts, to run through the pipeline.
- fresh cleaned Delta Tables to run the data through.
Here is a redacted version of what this might look like.
from pyspark.sql import SparkSession, DataFrame
import boto3
from random import randint
# Truncate integration tables.
spark = SparkSession.builder.appName('IntegrationPrep').enableHiveSupport().getOrCreate()
tables = ['delta_table_1', 'delta_table_2']
for table in tables:
logging.info(f"Starting truncate {table}")
spark.sql(f"""
TRUNCATE TABLE integration_schema.{table};
""")
folders_of_interest = ['raw_data1', 'raw_data2']
s3 = boto3.client('s3')
pages = get_pages(s3, bucket='my-raw-data-bucket')
# delete current integration bucket files
for folder in folders_of_interest:
response = s3.list_objects_v2(Bucket='my-integration-bucket', Prefix=folder)
for object in response['Contents']:
print('Deleting', object['Key'])
s3.delete_object(Bucket='my-integration-bucket', Key=object['Key'])
# copy new files over to s3 integration bucket
for folder in folders_of_interest:
remote_file = get_latest_file(pages, folder)
if folder in ['raw_data/very_large_file_1', 'raw_data/very_large_file_2']:
df = read_limit_file(spark, remote_file)
new_key = generate_new_uri(remote_file)
df.coalesce(1).write.csv(f's3a://my-integration-bucket/{new_key}', sep='\t', header='false')
else:
if remote_file:
copy_s3_file(s3, remote_file)As you can see, we run a few steps … first we TRUNCATE all our integration Delta tables, next we clean out the integration testing s3 bucket and then grab the latest file from production and copy it over into our integration s3 bucket. We even have a method to limit large files in case we have big data we don’t want to run through integration testing, basically limiting the file to 1,000 records or so.
Perfect, now we have Delta tables and new data for all end-to-end tests.
One DAG to Rule Them All, and In The Darkness Bind Them.
Of course, if we have many pipelines we need to integrate, say they are all in Airflow, AND we need to run our integration preparation steps … we need a Master DAG to run them all.
Luckily, calling other DAGs from a master DAG is easy, with the addition of our pre-processing step. Here is a redacted version of what that will look like.
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.contrib.operators.databricks_operator import DatabricksSubmitRunOperator
from airflow.operators.trigger_dagrun import TriggerDagRunOperator
from airflow.utils.dates import days_ago
from my_utils import slack_utils
from utils.databricks import databricks_constants
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
"on_failure_callback": slack_utils.task_fail_slack_alert
}
with DAG(
dag_id='databricks_integration_test',
default_args=default_args,
schedule_interval=None,
start_date=days_ago(2),
tags=['databricks', 'integration', 'test'],
catchup=False
) as dag:
integration_prep = \
DatabricksSubmitRunOperator(task_id='integration_preparation',
json=databricks_constants.integration_prep_params
)
databricks_pipeline_1 = \
TriggerDagRunOperator(task_id='databricks_pipeline_1',
trigger_dag_id='databricks_pipeline_1',
wait_for_completion=True)
databricks_pipeline_2 = \
TriggerDagRunOperator(task_id='databricks_pipeline_2',
trigger_dag_id='databricks_pipeline_2',
wait_for_completion=True)
integration_prep >> databricks_pipeline_1 >> report_dag
integration_prep >> databricks_pipeline_2 >> report_dagNote our wait_for_completion=True indicator in Airflow to wait for all pipelines to finish, and how our integration_prep runs prior to our pipeline calls. You can have as many pipelines called here as you want, make it 100 if that’s what it needs to be. Here is a real-life example of what that DAG looks like testing an entire suite of pipelines.
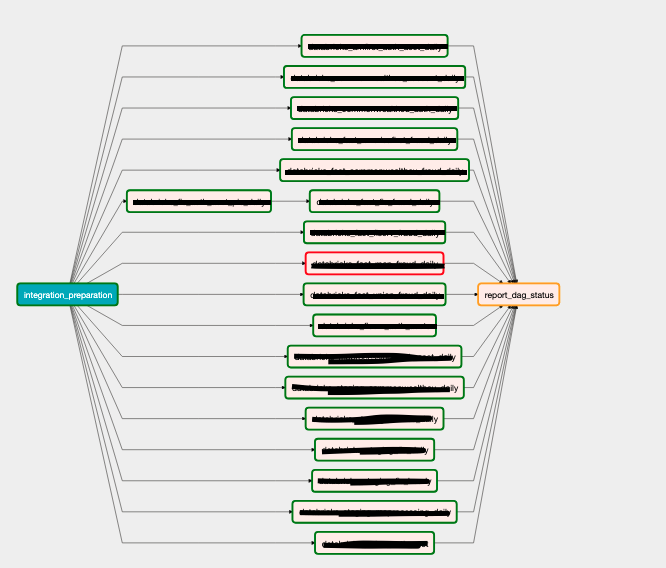
The Minor Detail that is a Big Deal.
I’m sorta glossing over something I mentioned in the beginning, and it’s key to making this whole thing work. Your pipelines HAVE to be environment agnostic, I mean they should be always right? You can’t hardcode s3 buckets and other critical environment information into your code and pipelines that would make running the integration test impossible.
This is simple when you design your pipelines in an agnostic way up front, but not so easy if you unwisely hardcoded things everywhere.
Your codebase needs to do something as simple as ENVIRONMENT = os.environ['ENV'] and from there be able to handle itself, aka know where to read and where to write, etc. I mean maybe it’s your s3 bucket locations BUCKET = os.environ['BUCKET'] , but however you do it, just make sure your pipeline knows the difference between PRODUCTION and INTEGRATION.
The Automation Part.
At this point you have separate resources and environments for everything including data, you have Airflow DAGs able to execute all your pipelines, you have preparation steps that ready that environment. What do you need now? The easy part is to automate it.
Most people are working on GitLab or GitHub and using some GitLab Runner, Jenkins, or CircleCi, something that is probably able to hook into your repo’s and run steps. The last piece we need is to remotely execute your “master” DAG for say every commit on a branch that is named integration-test or something right?
Here is a partial config.yaml file for a CircleCI setup that runs a Python script to trigger our master dag.
- run:
name: integration
command: |
if [ "<< pipeline.git.branch >>" == "integration-test" ];
then echo "starting to run integration test" && venv/bin/activate && python /home/circleci/repo/etl/cicd/execute_integration_dag.py
else echo "no need to run integration test, on branch << pipeline.git.branch >> "
fiOur Python file to execute the master DAG could not be simpler.
import boto3
import requests
client = boto3.client('mwaa', region_name='us-east-1')
token = client.create_cli_token(Name='airflow-integration-env')
url = "https://{0}/aws_mwaa/cli".format(token['WebServerHostname'])
body = 'dags trigger databricks_integration_test'
headers = {
'Authorization' : 'Bearer '+token['CliToken'],
'Content-Type': 'text/plain'
}
r = requests.post(url, data=body, headers=headers)
print(r.content)Musings
I know I scanned quickly over a lot of ground there, but this is a great way to run integration tests end-to-end on your Databricks + Delta Lake pipelines. The key is having Airflow, because of its wonderful DatabricksSubmitRunOperator and other Databricks integrations. Airflow makes integration testing end-to-end very easy, being able to have a master DAG to call that can call scripts to prepare the integration environment, and trigger all the pipelines is wonderfully easy.
The big gotcha is always if the codebase and pipelines themselves were written with foresight and easily able to handle different environments without much trouble. Once that is done, it’s really a matter of prepping your integration environment and automating the rest.
Databricks allows you to have a database the concept for your Delta tables, and is perfect for integration testing, it allows you have replicas of your DDL Delta Tables exist in a way that is an exact match of production but doesn’t interfere with it. The way you populate raw data can be complex (copying new files from production and limiting their size), or easy, just use INSERT statements to populate Delta tables.
After these steps are complete, wire up your CICD platform to run some checks and kick off a script depending on your branch is not much code at all.
Having an end-to-end integration environment for your Databricks + Delta Lake pipelines isn’t that hard, just takes a little upfront work and some creativity. I would be curious to know how others run integration tests for their Databricks + Delta Lake systems, drop a comment and let me know!!
Very insightful, as always.
What are your thoughts on having assertions about the behavior of the pipeline?
The way I read your current approach is “see if pipeline fails or succeeds” or am I missing a big piece here? How could you check and assert on the finer details of the transformations?
Thanks
I agree, an integration test like this isn’t validating any business logic, aka asserting data is “correct”, personally I would just add “post-processing” step, similar to the pre-processing step, in Airflow, that just runs some SQL queries against the Delta Tables to do the actual data validation.