DuckDB … reading from s3 … with AWS Credentials and more.
![]()
In my never-ending quest to plumb the most boring depths of every single data tool on the market, I found myself annoyed when recently using DuckDB for a benchmark that was reading parquet files from s3. What was not clear, or easy, was trying to figure out how DuckDB would LIKE to read default AWS credentials.
What most other projects do when it comes to credentials in AWS.
I think when we are talking about DuckDB and AWS credentials, we should do it in the context of other tools. Why? Because nothing happens in a vacuum. We all see and use tools based on how we’ve other tools and what we’ve become used to and expect as a standard operating procedure.
When it comes to working in and around AWS credentials things can kind of get hairy, confusing, etc. It depends WHERE you are running your code, and if you have control of things, if you are running inside some VPN and using instance profiles, etc, to grant access. Or maybe you’re just messing around in some EC2 instance or on your machine and you need your personal credentials available.
Let’s take for instance Daft, a Rust-based Python Dataframe tool.
If you store your credentials in .aws/credentials , maybe you configured everything using the aws CLI command. This is a very common setup for a lot of developers. Many tools, like Daft and Polars, will simply understand you are trying to access, say s3, and attempt to look and load default credentials.
- by looking in
.aws - by looking in the
environmentfor keys etc.
This is a typical workflow for most tools.
DuckDB’s confusing aws credential stuff.
I’m not sure if it’s because of different changes, but I think there are two different ways of loading creds.
- legacy
load_aws_credentials()– depreciated but works CREATE SECRET
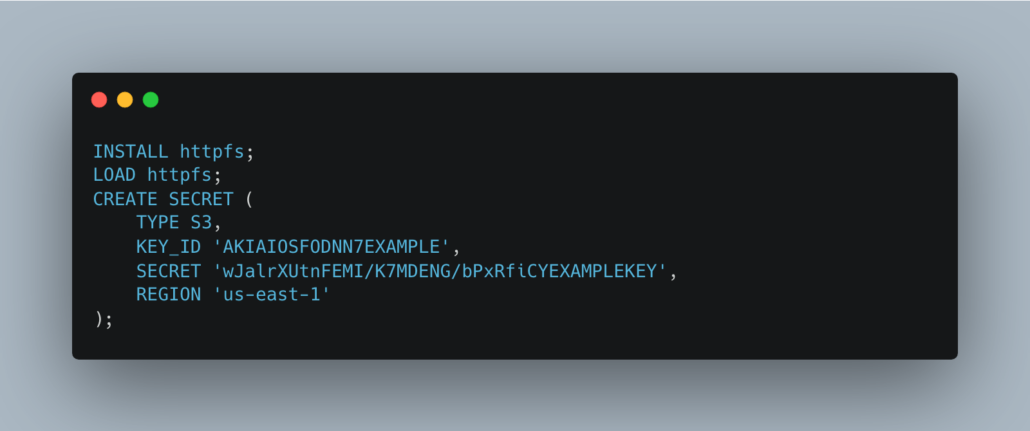
I honestly don’t like the CREATE SECRET approach.
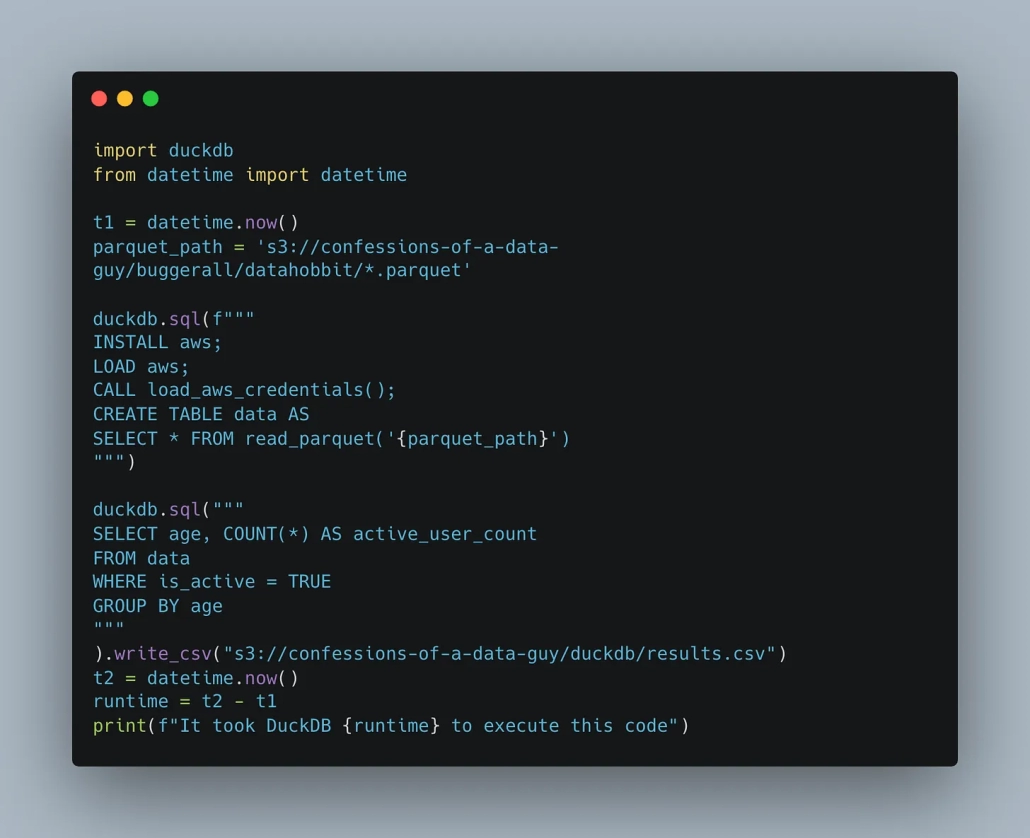
Since DuckDB is an “in-process” deal-o it seems annoying to have to do this in all the scripts. I mean isn’t it better to just be able to somehow reference and load the default creds?? This seems to be what the depreciated load_aws_credentials() does. I tested it and it works great loading .aws secrets.
If you read a little farther down in the documentation, you can find this, which appears to be what we are looking for.
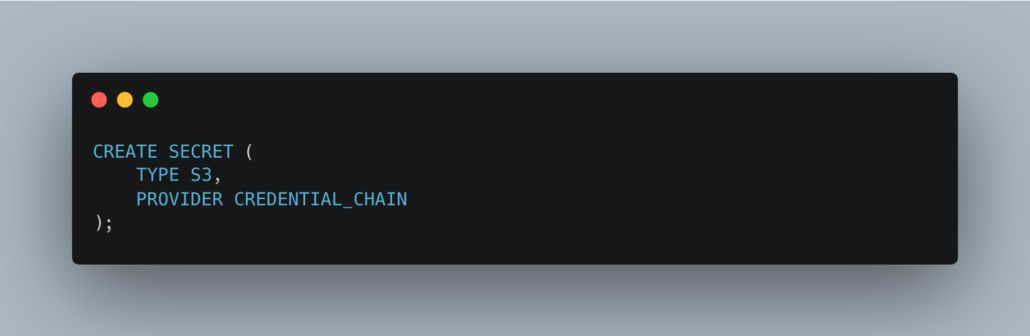
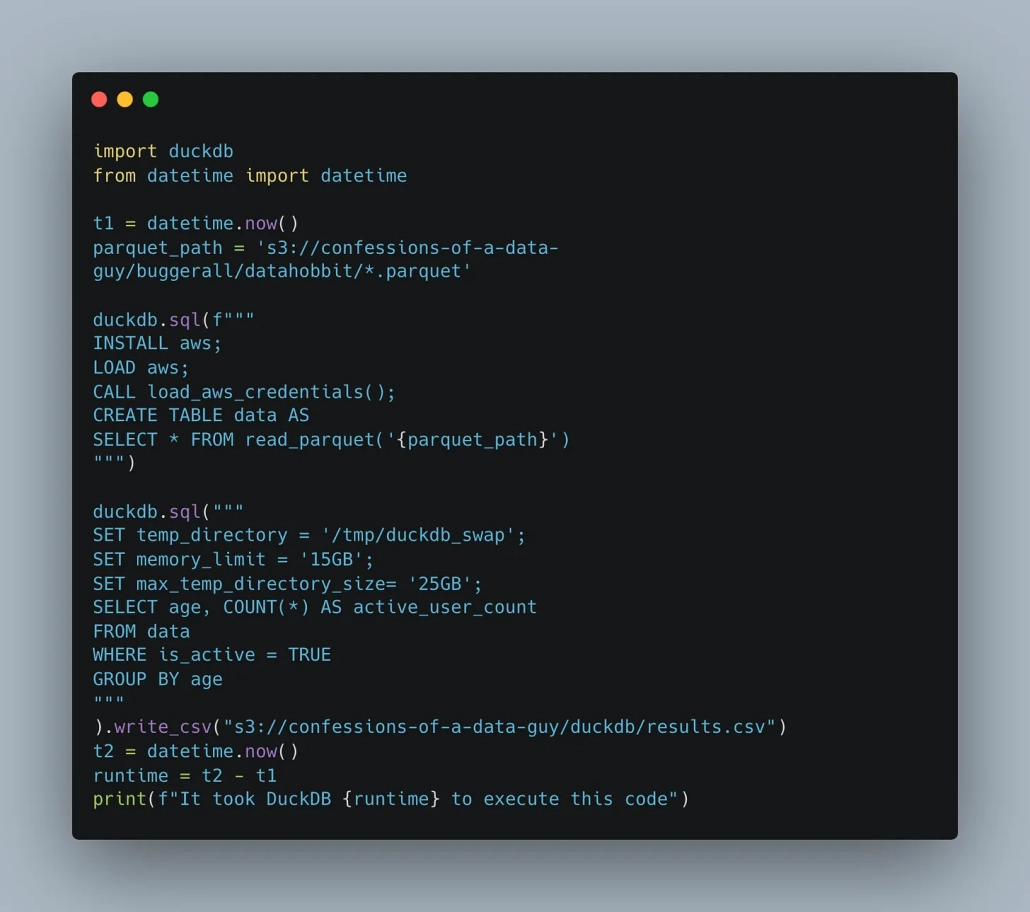
Interesting indeed, why you need to type these 3 lines of code and it can’t just try it automatically if you are trying to read from s3 is beyond me. At least they offer this option though.
I loathe it when a person must start to copy secrets, especially AWS ones, around different places, codes, files whatever. When it comes to AWS and credentials it should go in this order only.
- instance profiles so no creds are needed
.awsfilesENVvariables
That should really be the only three options, and all data tools should look for those creds by default, in that order. The problem comes in when you GIVE people the option to embed their creds in the code, they can and WILL do this, and then they will leak those creds.
Humans are human after all.