DataFusion courtesy of Rust, vs Spark. Performance and other thoughts.

I think it’s funny that DataFrames are so popular these days, I mean for good reason. They are a wonderful and intuitive way to work with and on datasets. Pandas … the nemesis of all Data Engineers and the lover of Data Scientists. Apache Spark is really the beast that brought DataFrames to the masses. Even those little buggers over at Apache Beam give you DataFrames.
Of course, when anything gets popular, you start getting little things that start to pick and peck at the heels. I would probably say that is what DataFusion with Rust seems to be. Seems more like a contender against Pandas rather than Spark to me. I guess if you’re just using Spark locally or on a single node, sure you could consider using DataFusion. Code available on GitHub.
What is DataFusion, and what is it missing?
I want to look at DataFusion from a few different vantage points, as a Data Engineer, not as a Data Scientist or Analyst. I’m concerned more about the ease of use, the support, the scalability, and other such things. Some points of particular interest to me.
- Local, single-node data processing and usage.
- Big Data cluster data processing.
- Features ( data processing )
- Performance
DataFusion overview.
I keep asking myself what DataFusion really is, in my view, without a robust and easy-to-use Distributed Framework, like Spark runs on, what’s the point? I guess if you’re looking for a Pandas replacement, but then again Spark now has a Pandas compliment API, so there’s that.
“DataFusion is an extensible query execution framework that uses Apache Arrow as its in-memory format.”
– DataFusion docs
Many Data Engineers would already be familiar with Apache Arrow, it’s been around a while and is the backbone of a few popular Python packages when it comes to reading parquet files and other such things.

DataFusion Offerings.
Without wasting my life digging into every little detail, I want to give you and me in broad strokes, what DataFusions has to offer, as far as features. I’m probably just going to list a bunch of random ones that I find in the documentation.
- Ability to write SQL
- DataFrame API
- filter
- select
- aggregate with groupby
- union
- distinct
- sort
- join
- repartition
- write CSV, JSON, Parquet
- String functions
- Math functions
The list goes on, pretty much like Spark, as would be expected. No tool like this will have success unless it matches at least 80% of the features Spark offers. I prefer to be where the rubber meets the road, and actually, try things out. Let’s start to write some simple DataFusion code and see how the line falls.
Read CSV files, simple Group By and Count.
There is probably nothing more common than reading a bunch of CSV files and then doing some Group By command with an aggregate of some sort, in our case a count. It will be interesting to see what the code looks like … and compare it to what the same PySpark command might be.
use datafusion::prelude::*;
use std::time::Instant;
#[tokio::main]
async fn main() -> datafusion::error::Result<()> {
let now = Instant::now();
let fusion = SessionContext::new();
let df = fusion.read_csv("data/*.csv", CsvReadOptions::new()).await?;
let df = df.aggregate(vec![col("member_casual")], vec![count(col("ride_id"))])?;
df.show_limit(100).await?;
let elapsed = now.elapsed();
println!("Elapsed: {:.2?}", elapsed);
Ok(())
}
The result is as one would expect.
+---------------+------------------------+
| member_casual | COUNT(?table?.ride_id) |
+---------------+------------------------+
| casual | 1670680 |
| member | 2217472 |
+---------------+------------------------+
Elapsed: 10.44sI have a few general comments about this code. Here we go. Creating a context or session is straightforward, as well as reading files, in this case CSVs is also familiar to anyone who’s worked with Spark.
let fusion = SessionContext::new(); let df = fusion.read_csv("data/*.csv", CsvReadOptions::new()).await?;
It’s nice we can read data/*csv, and it will pick up all the files we want. Small things make a difference. But now let’s get to some things I do not like, stuff that feels awkward and strange. Especially for anyone coming from Spark or even Pandas. Parts of the aggregate function are just strange.
let df = df.aggregate(vec![col("member_casual")], vec![count(col("ride_id"))])?;
First, you have to read the documentation to realize when running a aggregate function, that the first optional argument is the groupby. Even though with this DataFrame API example, there is nothing in the code that indicates that. That is a terrible design. I guess you can always use SQL, but I always default toward the DataFrame APIs because in my mind they make code more reusable and unit testable.
Also, what’s with the vec![] syntax. It just adds strangeness and is unnecessary. Other than that, it’s what one would expect. Let’s look at this same code with PySpark just to see what we see. And maybe compare performance. Although it’s hard to compare performance when testing with Spark locally, there is a lot that goes on with Spark, the setting up UI , etc.
Same thing in PySpark.
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
from datetime import datetime
spark = SparkSession.builder.appName('SparkVFusion').master('local[8]').getOrCreate()
spark.sparkContext.setLogLevel('WARN')
t1 = datetime.now()
df = spark.read.csv("data/*csv", header='true')
trans = df.groupBy('member_casual').agg(F.count('ride_id'))
trans.show()
t2 = datetime.now()
print("it took {x}".format(x=t2-t1))Of course this is a little easier on the eyes, the groupBy and agg is a little more intuitive, that’s for sure. Sure, it’s a little slower, but that doesn’t mean much.
+-------------+--------------+
|member_casual|count(ride_id)|
+-------------+--------------+
| casual| 1670680|
| member| 2217472|
+-------------+--------------+
it took 0:00:14.151150
Trying out SQL with DataFusion.

I’m interested to try out the SQL functions of DataFusion, just to see what it’s like. This is where probably what most folks default to. I myself have found myself drifting away from using the SQL API in Spark, mostly because of the bad habits it re-enforces, namely pilling too much complex and hard-to-read logic in one spot, folks start drifting away from unit testing and functional code … they just end up writing massive SQL statements that end up being buggy and hard to debug. Anyways. Let’s try DataFusion SQL.
use datafusion::prelude::*;
use std::time::Instant;
#[tokio::main]
async fn main() -> datafusion::error::Result<()> {
let now = Instant::now();
// register the table
let ctx = SessionContext::new();
ctx.register_csv("trips", "data/*.csv", CsvReadOptions::new()).await?;
// create a plan to run a SQL query
let df = ctx.sql("
SELECT COUNT('transaction_id') as cnt,
date_part('year', to_timestamp(started_at)) as year,
date_part('month', to_timestamp(started_at)) as month,
date_part('day', to_timestamp(started_at)) as day,
start_station_name
FROM trips
WHERE date_part('year', to_timestamp(started_at)) = 2022
GROUP BY date_part('year', to_timestamp(started_at)),
date_part('month', to_timestamp(started_at)),
date_part('day', to_timestamp(started_at)),
start_station_name
").await?;
df.show_limit(100).await?;
let elapsed = now.elapsed();
println!("Elapsed: {:.2?}", elapsed);
Ok(())
}
The SQL API acts much like one would expect, very similar to Spark, being able to register_csv to a table referred later as SQL is very similar to Sparks createOrReplaceTempView syntax. There isn’t really much to say on the writing of the SQL itself, inspecting the documentation for the SQL API and Reference, it appears to support most anything you could want to do in SQL.
“But this one thing I have against you …” It appears the more complex query including the GROUP BY and CASTing of the strings to timestamps is extremely slow in DataFusion.
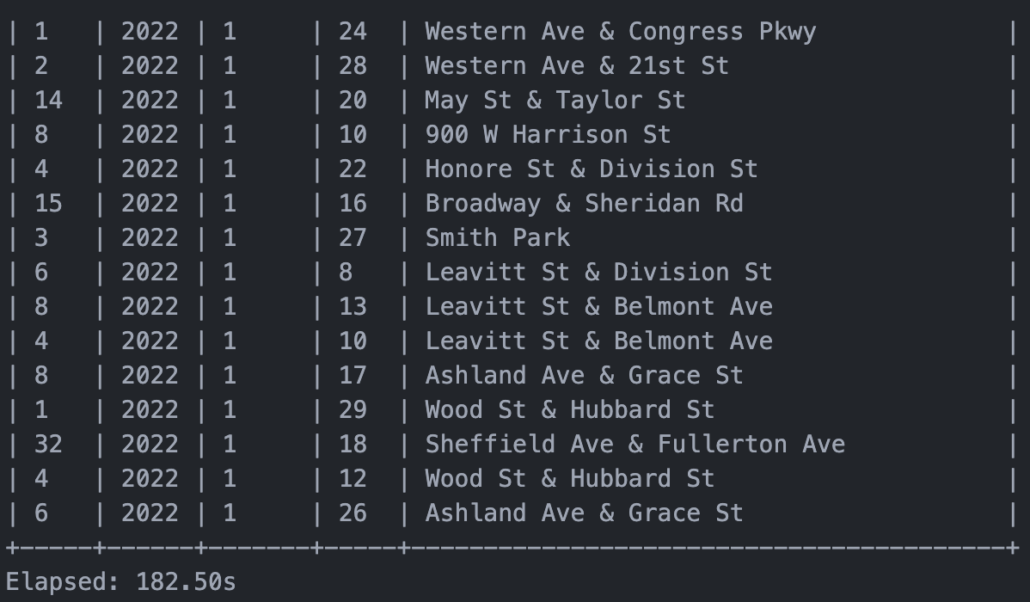
It took a whopping 182 seconds to run this code. It seems to me there are some underlying implementation issues, probably to do with sorting and shuffling the data around that makes this slow. This is a big red mark for me, because this is what you would really want a tool like DataFusion for, to do this sort of grouping and aggregate work, and being slow at this defeats the purpose, just use Pandas or Spark then.
Let’s reproduce that code in Spark and see what we get.
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
from datetime import datetime
spark = SparkSession.builder.appName('SparkVFusion').master('local[6]').getOrCreate()
spark.sparkContext.setLogLevel('WARN')
t1 = datetime.now()
df = spark.read.csv("data/*csv", header='true')
df.createOrReplaceTempView('trips')
trans = spark.sql("""
SELECT COUNT('transaction_id') as cnt,
date_part('year', CAST(started_at as TIMESTAMP)) as year,
date_part('month', CAST(started_at as TIMESTAMP)) as month,
date_part('day', CAST(started_at as TIMESTAMP)) as day,
start_station_name
FROM trips
WHERE date_part('year', CAST(started_at as TIMESTAMP)) = 2022
GROUP BY date_part('year', CAST(started_at as TIMESTAMP)),
date_part('month', CAST(started_at as TIMESTAMP)),
date_part('day', CAST(started_at as TIMESTAMP)),
start_station_name
""")
trans.show()
t2 = datetime.now()
print("it took {x}".format(x=t2-t1))And here are the much faster Spark results.
+---+----+-----+---+--------------------+
|cnt|year|month|day| start_station_name|
+---+----+-----+---+--------------------+
| 52|2022| 6| 26| Wells St & Polk St|
| 71|2022| 6| 18|Marine Dr & Ainsl...|
| 26|2022| 6| 5|Dearborn St & Van...|
| 99|2022| 6| 14|Michigan Ave & La...|
| 9|2022| 6| 3|California Ave & ...|
| 84|2022| 6| 6|Desplaines St & K...|
| 5|2022| 6| 17|Keystone Ave & Mo...|
| 46|2022| 6| 11|Ogden Ave & Race Ave|
| 19|2022| 6| 22|Damen Ave & Waban...|
|131|2022| 6| 18|Wells St & Hubbar...|
| 43|2022| 6| 18|Racine Ave & Wash...|
| 39|2022| 6| 27|Michigan Ave & Pe...|
| 1|2022| 6| 20| Damen Ave & 51st St|
|107|2022| 6| 15|DuSable Lake Shor...|
| 14|2022| 6| 19| State St & 35th St|
| 15|2022| 6| 13|Damen Ave & Walnu...|
| 5|2022| 6| 24|Central Park Ave ...|
| 20|2022| 6| 15|Rhodes Ave & 32nd St|
| 54|2022| 6| 4|Western Ave & Wal...|
| 52|2022| 6| 4|Ogden Ave & Chica...|
+---+----+-----+---+--------------------+
only showing top 20 rows
it took 0:01:05.885284
65 seconds with Spark compared to 182 with DataFusion. Yikes, that’s no good. Definately was expecting more from Rust, but that probably just goes to show how much effort has been built into Spark over the years more then a downfall of Rust. Over large datasets this could have serious side effects.
Musings on DataFusion.
Overall I think DataFusion is a wonderful thing for the Rust community, it’s important for anything to be taken seriously as a Data Engineering day-to-day tool to have some sort of DataFrame centric package for processing data. I can see the alure of DataFusion for a Rust person, it allows you to stay with what you know, and you don’t have to incorporate something heavy like Spark, or something terrible like Pandas, DataFusion appears to be able to get the job with ease and straight forward features.
I would probably never use DataFusion in any sort of Production environment, maybe just for some local/small scale stuff at most. The performance issue to me is a huge downside, it’s over twice as slow as Spark on a small and simple workload. I can imagine that gap would only continue to grow with complex pipelines. But hey, three cheers for Rust and DataFusion.