Dataframe Showdown – Polars vs Spark vs Pandas vs DataFusion. Guess who wins?

There once was a day when no one used DataFrames that much. Back before Spark had really gone mainstream, Data Scientists were still plinking around with Pandas a lot. My My, what would your mother say? How things have changed. Now everyone wants a piece of the DataFrame pie. I mean it tastes so good, doesn’t it?
Would anyone like a nice big slice of groupBy, maybe agg is what you need? No? Can you say distributed data set? Whatever it is you’re looking for, I’m quite sure a nice old DataFrame can give it to you. With so many options to choose from … what do you choose? I don’t know, whatever works best for you. But, it does set the stage nicely for a clash of the titans per see.
Let’s do this just that. Straight out of the box performance test. Bunch of CSV’s, a little aggregation, just some simple stuff. Mirror mirror on the wall, who is the fastest with DataFrames of them all?
The Dataframe Tools.
I’m not going to dive very deep into each one of these tools, most of them are probably familiar to you, except maybe some of the Rust based newcomers like Polars and DataFusion. Also, it’s probably not fair to put Spark in the mix, it is a distributed computing platform and all. But yet, I have to. I find it interesting to compare all sorts of tools.
It’s interesting to observe how the code is written in each case for the test, it tells you a little something about the tool. It is also of course interesting to see the performance as well, although it seems to drive the fans of each tool crazy on the internet, which is half the fun. I won’t be tweaking any of the tools, simply installing them and using them.
- How easy and similar is it to read simple flat files and do normal aggregation?
- What does the out-of-the-box performance look like?
We are going to be working with 1 year of data from Divvy Bike trips open source dataset.
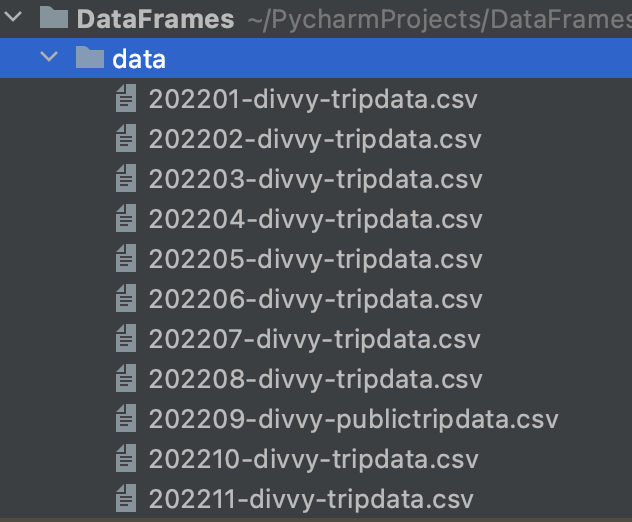
This data set isn’t overly large, about 5,485,922 records. But I suppose that will probably be enough to make Pandas chug maybe? The data set is pretty straightforward, this is what it looks like.
I think just a simple aggregation with suffice, doing a simple GroupBy the started_at date (by month) and a count. If it was SQL we would do
SELECT MONTH(CAST(started_at as DATE)), COUNT(*) as cnt
FROM data
GROUP BY MONTH(CAST(started_at as DATE))Let’s get after it.
Polars – Blazingly fast DataFrames in Rust, Python.
The new kid on the block is Polars, you’re just starting to see posts show up here and there. The Dataframe space is getting crowded these days, it’s hard to keep all the options straight, and of course, everyone says they are the fastest, which is a discussion for another time. Anyways, let’s use the Python version of Polars so we can just pip install and move on.
Let’s start our Polars journey by simply trying to read our .csv files and casting our date string to a date data type.
import polars as pl
q = (
pl.scan_csv("data/*.csv", parse_dates=False)
)
df = q.collect()
df = df.with_column(pl.col("started_at").str.strptime(pl.Date, fmt="%Y-%m-%d %H:%M:%S"))
print(df)Let me get this straight … Polars is having problems reading a flipping CSV file?? How annoying is that. Honestly, if Polars can’t read a normal flat-file very well, what hope does it have to become mainstream?
Traceback (most recent call last):
File "/Users/danielbeach/PycharmProjects/DataFrames/main.py", line 7, in <module>
df = q.collect()
File "/Users/danielbeach/PycharmProjects/DataFrames/venvrm/lib/python3.9/site-packages/polars/utils.py", line 310, in wrapper
return fn(*args, **kwargs)
File "/Users/danielbeach/PycharmProjects/DataFrames/venvrm/lib/python3.9/site-packages/polars/internals/lazyframe/frame.py", line 1164, in collect
return pli.wrap_df(ldf.collect())
exceptions.ComputeError: Could not parse `TA1309000067` as dtype Int64 at column 6.
The current offset in the file is 19353 bytes.
Consider specifying the correct dtype, increasing
the number of records used to infer the schema,
running the parser with `ignore_parser_errors=true`
or adding `TA1306000026` to the `null_values` list.
Let’s see if we can fix this hunk of junk. I think the Error notes are funny. I guess I could specifiy the correct data type, but if every other tool can figure it out … what can’t Polars? Let’s just use the dtype argument to deal with the problem columns and move on. Super annoying.
Let’s write this code already.
import polars as pl
from datetime import datetime
d1 = datetime.now()
q = (
pl.scan_csv("data/*.csv", parse_dates=False, dtypes={"start_station_id": pl.Utf8,
"end_station_id": pl.Utf8})
)
q = q.with_column(pl.col("started_at").str.strptime(pl.Date, fmt="%Y-%m-%d %H:%M:%S").alias("started_at"))
df = q.lazy().groupby(pl.col("started_at").dt.month()).agg(pl.count()).collect()
print(df)
d2 = datetime.now()
print(d2-d1)Well, it ran, that’s one thing. Seems pretty fast as well, 2.127699 seconds for 5 million+ records groupBy with some slight date transformations.
(venvrm) (base) danielbeach@Daniels-MacBook-Pro DataFrames % python3 main.py
shape: (11, 2)
┌────────────┬────────┐
│ started_at ┆ count │
│ --- ┆ --- │
│ u32 ┆ u32 │
╞════════════╪════════╡
│ 8 ┆ 785932 │
├╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┤
│ 7 ┆ 823488 │
├╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┤
│ 6 ┆ 769204 │
├╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┤
│ 5 ┆ 634858 │
├╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┤
│ ... ┆ ... │
├╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┤
│ 10 ┆ 558685 │
├╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┤
│ 2 ┆ 115609 │
├╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┤
│ 1 ┆ 103770 │
├╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┤
│ 9 ┆ 701339 │
└────────────┴────────┘
0:00:02.127699Let’s do Spark next.
Spark – the one ring to rule them all.
You know, Spark wasn’t made to work on such small datasets like this. But, it’s easy to install, used by pretty much everyone, everywhere, so it makes it imperative to test it out with the rest of group. Spark is great because you can easily process data that is much larger than memory, without any lazy() or collect() funny stuff like Polars.
The advent of PySpark actually makes the code approachable by anyone, even less technical folks. Spark will be slower, but probably simpler to write.
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
from datetime import datetime
import logging
spark = SparkSession.builder.appName('testing') \
.enableHiveSupport().getOrCreate()
logging.basicConfig(format='%(asctime)s %(levelname)s - Testing - %(message)s'
, level=logging.ERROR)
d1 = datetime.now()
df = spark.read.csv('data/*.csv', header='True')
df = df.withColumn('started_at', F.col('started_at').cast('date'))
df = df.groupby(F.month(F.col('started_at'))).agg(F.count('*'))
print(df.show())
d2 = datetime.now()
print(d2-d1)And no surpises here. Way slower at 20.201003 seconds, Spark was made for big datasets, but a little bit easier to write the code than Polars.
+-----------------+--------+
|month(started_at)|count(1)|
+-----------------+--------+
| 1| 103770|
| 6| 769204|
| 3| 284042|
| 5| 634858|
| 9| 701339|
| 4| 371249|
| 8| 785932|
| 7| 823488|
| 10| 558685|
| 11| 337735|
| 2| 115609|
+-----------------+--------+
0:00:20.201003
Onto everyone’s favorite that I hate. Too many bad memories.
Pandas – the one that won’t go away.
I get it, Python is everywhere and Pandas was the first one to the Dataframe party back in the day, now it’s everywhere. It’s still annoying. So many people use it for what they shouldn’t and then complain about it. Oh well, I guess if I have to.
One of the most annoying things about Pandas is how you go about reading multiple files, at least the way I do it. You would think someone who have fixed that by now.
import pandas as pd
from datetime import datetime
import glob
d1 = datetime.now()
files = glob.glob('data/*.csv')
df = pd.concat((pd.read_csv(f) for f in files), ignore_index=True)
df['started_at'] = pd.to_datetime(df['started_at'])
df = df.groupby(df.started_at.dt.month)['ride_id'].count()
print(df)
d2 = datetime.now()
print(d2-d1)Just as fast as Spark, simple enough, and comes in at 17.234139
started_at
1 103770
2 115609
3 284042
4 371249
5 634858
6 769204
7 823488
8 785932
9 701339
10 558685
11 337735
Name: ride_id, dtype: int64
0:00:17.234139Last, and maybe least, at least, least known is DataFusion.
DataFusion – the dude in the corner.
I‘ve written about DataFusion before, a nice little Rust DataFrame tool. It doesn’t seem to be that well known, it has a Python package, but seems a little on the rinky-dink side and has nothing for documentation. We will stick to Rust with this one. Nothing like a little SQL to get the job done.
use datafusion::prelude::*;
use std::time::Instant;
#[tokio::main]
async fn main() -> datafusion::error::Result<()> {
let now = Instant::now();
let ctx = SessionContext::new();
ctx.register_csv("trips", "data/*.csv", CsvReadOptions::new()).await?;
// create a plan to run a SQL query
let df = ctx.sql("
SELECT COUNT('transaction_id') as cnt,
date_part('month', to_timestamp(started_at)) as month
FROM trips
GROUP BY date_part('month', to_timestamp(started_at))
").await?;
df.show_limit(100).await?;
let elapsed = now.elapsed();
println!("Elapsed: {:.2?}", elapsed);
Ok(())
}UPDATE: I ran this code without --release mode. It ran in 3.26 when running it correctly.
I had this same problem last time I used DataFusion, dude it’s slowwwww! I have no idea if I’m doing something wrong, I suck at Rust. WRONG -> 100.20s is crazy slow. <- WRONG
+--------+-------+
| cnt | month |
+--------+-------+
| 702781 | 9 |
| 767132 | 6 |
| 370689 | 4 |
| 102728 | 1 |
| 560259 | 10 |
| 825390 | 7 |
| 284681 | 3 |
| 1553 | 12 |
| 631624 | 5 |
| 785427 | 8 |
| 114715 | 2 |
| 338932 | 11 |
+--------+-------+
Elapsed: 3.26s
Musings
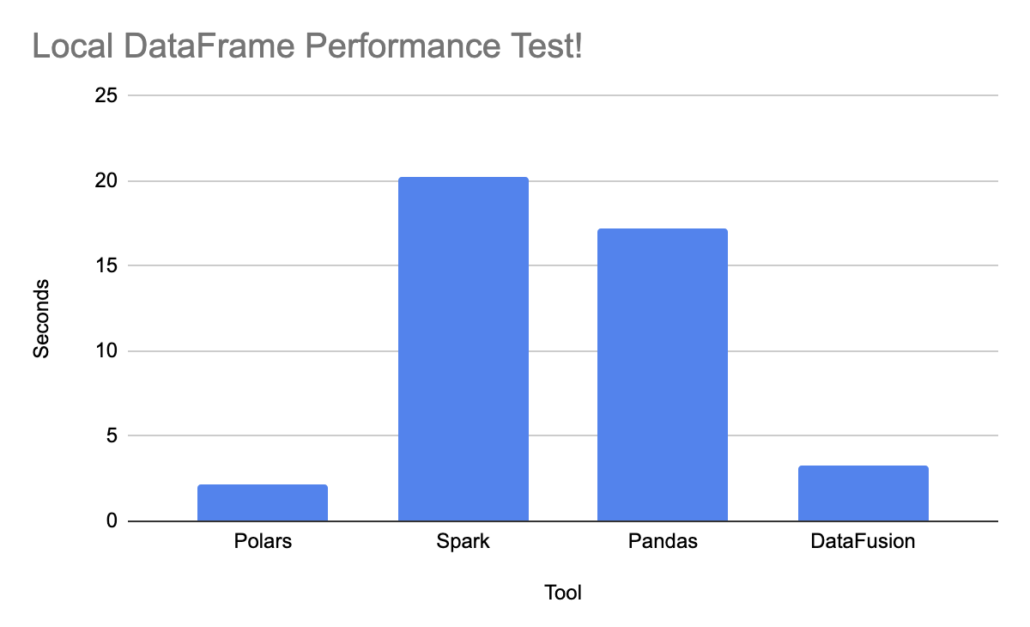
We probably didn’t learn that much today, It was pretty easy to write the same code for them all. It is interesting to see how each of the tools deals with dates. Date and time-series aggregations are super common when working locally with flat files, so it’s good to see that point of view. I was pleasantly surprised to see how straightforward it was with Polars with_column(pl.col("started_at").str.strptime(pl.Date, fmt="%Y-%m-%d %H:%M:%S"). That’s the syntax we are all used to.
Spark is Spark, probably the easiest and most straightforward code. As usual, Pandas is a little weird, but fast, as would be expected on a data set that fits into local memory. DataFusion was the longest code to write, and super slow.
I guess I can take away one thing from this all …
“If you’re working with local datasets (not Spark distributed size),
– MePolarsthe new kid on the block, easy to write and blazing fast, putting all others to shame.”
Polars is on my radar now, going to be looking for an excuse to use it.
Hey, I’d recommend trying DuckDB out (even though it’s technically not a dataframe). I’ve seen it perform close to polars, and the syntax is much simpler (SQL).
Also, have you tried Andy Grove’s Ballista crate? It’s distributed datafusion essentially.
Hello, thanks for sharing this.
I was able to reproduce the results (clone from github), and was able to improve the results of Polars to ~0.7 sec just by changing this line:
df = q.lazy().groupby(pl.col(“started_at”).dt.month()).agg(pl.count()).collect(streaming=True).
Polars is very promising tool!!
Pandas with duckdb has been my go-to lately for data that doesn’t require spark cluster. It basically turns pandas into pyspark. If duckdb ever officially supports the delta file formant it might become my daily driver.