Data Pipelines 101 – The Basics.

I’ve been getting a lot of questions lately about data pipelines, how to design them, what to think about, and what patterns to follow. I get it, if you’re new to Data Engineering it can be hard to know what you don’t know. There is a lot of content specific to certain technologies, but not as much around some basics, especially data pipelines. Where do you even start? Are there common patterns that can be followed and used in all data pipelines regardless of tech stack?
Let’s dive into data pipelines 101, and call it an “Introduction to Data Pipelines.” What to know where to start and what to look out for? Start here.
Identifying common Data Pipeline Patterns.
A lot has changed over the last few decades in data land, of course, technologies are always changing. But, like in life, some things never change. When breaking into or starting out in Data Engineering you eventually have to write your first data pipeline. It’s a core function of Data Engineering, being able to design reliable, scalable data pipelines.
That begs the question, is there such a thing as a “template” or “pattern” that can be taught or followed for those new to Data Engineering and data pipelines? Is that even possible when you’re talking about data pipelines that can be running on Postgres or Spark? I mean the technologies are so different, don’t the data pipelines look completely different?
No!

Data Pipeline Basics.
I assert that most good data pipelines are the same (most of the time) regardless of technology. In fact, if I showed you some data pipelines that I ran every day… you could not tell on the surface what is processing the data, could be plain old Python, or Spark, or Postgres. The data processing itself is pretty transparent.
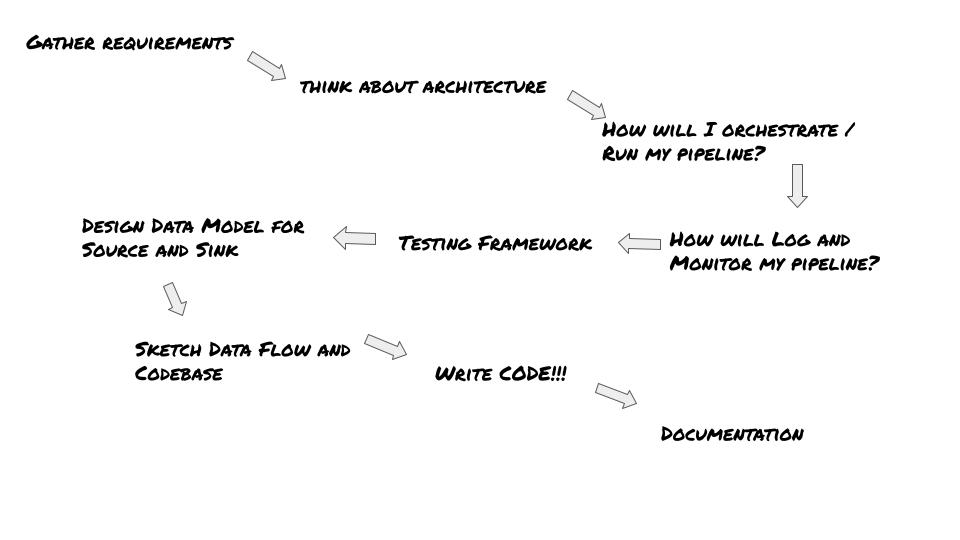
Yes, we can teach data pipelines basics … patterns that can be followed by anyone to build reliable and resilient data flows. Here is how I propose you approach and design data pipelines.
- Requirements
- Architecture
- Orchestration
- Logging and Monitoring
- Testing
- Data Modeling
- Sketch Out Data Flow
- Write Code
- Documentation
Gather Requirements

The first step, and probably the one that gets skipped the most. The problem with non-existent, unclear, or miss-interpreted requirements, whether it’s a JIRA ticket or a Google Doc, doesn’t really matter, the problem is usually the same. Typically the requirements surrounding a new data request or pipeline is a paltry 3-4 sentences, one paragraph if you are lucky.
I know a lot of Data Engineers cringe at the idea of actually having to communicate and talk with the business or another group of folks that are the consumer and users of the data, and therefore responsible for at least some of the requirements. But, honestly, it doesn’t have to be an hour-long awkward meeting. A 5 or 10-minute chat after a standup meeting or some Slack messages can usually save days of development time.
What should you even ask?
- SLA agreements (service level agreements). How long is acceptable downtime?
- When does the data need to be delivered?
- How often does the data need to be delivered?
- What is the preferred data format for ingestion of requested data?
- What columns/fields/data points are expected to be in the output?
- What is the grain/or level of detail needed?
- What ambiguity remains that needs to be answered?
This is a good place to start with questions.
Think about Architecture

Some folks take this step more seriously than others, but this is important nonetheless. The main idea here is to NOT write code before THINKING about the data pipeline and data flow as a whole. A good best practice for the architecture step start thinking about all the pieces and parts of the pipeline in our list. This is the step where we think about technology, logging, testing, data sources and sinks, and orchestration.
We think about how each piece will fit together in the big picture. It’s helpful too many times to draw pictures and map things out on paper. Architecture is making sure you are taking all pieces and parts into consideration for the data pipeline. A common mistake is ignoring a piece of the puzzle because you deem it “not important”, until 3 days into writing code you realize this piece is more important than you think that might have a large impact on the design and implementation of the pipeline.
- Think about each piece of the pipeline, are you leaving something out?
- How will each piece work together?
- Are there multiple technology options, what are the pros and cons of each?
- How does this pipeline and data fit into current tools and architecture?
I encourage you next time you’re about to work on a new data pipeline, to stop and take a moment to ask these questions and others before jumping to specific solutions or technologies because they are comfortable to you.
Orchestration

Another very important aspect of building data pipelines, especially if you are new to Data Engineering or pipelines is orchestration. Something or someone must run the pipeline on a schedule, at a certain time and execute the code. There are many varied options for pipeline orchestration ranging from every present but terrible cron job on a server to the wonderful Apache Airflow.
The choice of what orchestration tool is actually very important to the data pipeline, it has many dependencies in will most likely affect the other parts of your pipeline like monitoring, logging, testing, and documentation.
The wisest step you can take when choosing an orchestration tool is to consider these other requirements and ensure the tool will support the flexibility needed to integrate with how you log, monitor, and schedule your pipeline.
- Consider your orchestration tools’ integration capabilities.
- Think about errors and monitoring, does the tool easily integrate with
Slackor other tools. - Look into logging and debugging. If something goes wrong how accessible are the logs for debugging?
Some orchestration tools are very complex and provide a myriad of options. This is good and bad, are you ready to take on that overhead? Choose the right tool for the job.
Logging and Monitoring

Another topic that is usually an after-thought when it comes to data pipelines is logging and monitoring. What you aren’t taught in the beginning of your Data Engineering journey is that the minute you create a new pipeline, (which will inevitably break), you will spend a lot of your time debugging, inspecting, and generally monitoring data pipeline runs.
It’s critical to be able to monitor ongoing data pipeline executions, the more visual monitoring is the better. Being able to see the history of the pipeline runs, past failures and current failures are all important factors to consider when looking for how to monitor data pipelines. Logging falls into the same boat. It’s also extremely important to remember that the more logging, monitoring, and orchestration can work together and be one, the easier your job will be.
After you have begun monitoring your data pipeline, logging is the next most important. When something happens in the pipeline, if it breaks, or you need to debug quickly and efficiently, having accessible logs is worth its weight in gold. Logs related to each data pipeline run that can be reached within seconds save time, frustration, and headaches.
- Monitoring that is visual is best.
- Being able to see past, present, and schedule runs of the data pipeline.
- The more integrations between the monitoring, logging, and orchestration the better.
- Quick access to logs is critical.
Never take logging and monitoring for granted, think about these topics long and hard. Your pipelines will break, you need to be ready for it.
Testing

Now we are starting to come to one of the more painful and harder parts of data pipelines, testing. Well, let me take that back. Testing data pipelines is only hard if you leave it as an afterthought to be implemented at some later date, or after the pipeline is done. If you do this, of course, it’s going to be harder.
Asking one’s self “how am I going to test this?” is a critical question for Data Engineers to ask, BEFORE anything is built. Is it going to be possible to test the pipeline end to end? Do we have sample data for local testing? Will the code be functional and testable? How do I know things are working as intended?
These are questions that will affect the way you build your data pipelines, it will affect what tools you choose at every step of the process. If you have a piece or component that does not lend itself to testability, how are you going to overcome this? What happens when you have to make changes later on and need to test their effectiveness.
- Always write code that is unit testable.
- Choose technologies (orchestration etc) that lend themselves to testability.
- Carefully review how to test all components before any code or architecture is written or built.
- Define test cases early on in the process.
- Gather real-life sample data to use for testing.
Remember, if you can’t test all components of your pipeline, it isn’t much of a pipeline.
Data Modeling

Is there anything better than a good data model? Is there anything worse than a bad data model? It’s hard to underestimate the effect of the data model(s) for both your source and sinks, they will make or break a pipeline.
It’s hard to know where to start when talking about data models, but if you’re new to Data Engineering and data pipelines, we have to start somewhere. I’m thinking about a few different topics when I think about data models. Before we get too much into the pipeline there are a few basics of our source and sink destinations we should try to understand the following topics.
- Schema and data types of source (incoming) and sink (destination) data.
- Data relationships to other data sets.
- Data size and velocity.
- Data partitions or indexes.
What I’m really trying to say is that you need to study the ins and outs of your dataset BEFORE building your pipeline(s). I mean, we are building pipelines to run data through are we not? You would be amazed at many problems that surface after the fact around data types and other schema problems when such information is clearly and easily available beforehand.
At a minimum, every Data Engineer should read the Data Warehouse Toolkit, and be familiar with the different file types and data structures, compression, data types, and the like.
Sketch Out Data Flow

Almost to the finish line! At this point, if you’ve walked through all the above points you’re probably chomping at the bit to write your code and pipeline. I get it. But, I would suggest one last step before setting down to write the actual code of the pipeline based on all the knowledge you’ve gathered up to this point.
The pseudo-code of course. This topic is short and sweet, really what it comes down two is sketching out in pseudo-code, or real code, what the data flow of your pipeline is going to be. So this is usually just a bunch of empty methods or classes that indicate what you are about to write, but have not yet.
This has the wonderful effect of showing you gaps and holes, and bugs you didn’t think about. It can also cause you to stop and rethink some of the other steps we just walked through, maybe something isn’t as it seems when you start sketching out the code. This will save you time in the long run.
- Sketch code out.
- Write empty functions or classes and think through the data flow.
Write Code.
Finally, write the code. Done.
Documentation.

You probably thought I was going to skip this one. Nope. I don’t care if it’s a README (every data pipeline should have a README) or a Confluence page, I mean a Google Doc if that’s what you’re into.
Documentation clears away any remaining ambiguity and questions. It’s your time to polish off the pipeline, to show what it does and why. Good topics to cover are …
- Tools and tech stack.
- Assumptions.
- Information about data set source and sink.
- How to run and test the pipeline.
That would be a very basic list of what to include in your documentation. It’s hard to drop into a new pipeline, even if you wrote it, months or a year later, and try to figure out what’s going on just by reading code. Think how much time and heartache can be saved by just a little context! Simply describe what your data pipeline is, what it does, and how is a huge helper to yourself and all those coming after you!
Musings.
That’s it, the “Data Pipeline Basics”. I think these are good steps, or some form of them, are great for anyone writing any data pipelines. Missing anyone the long way will most likely come back to bite you.
Sure it takes longer, many times in life, the right way is the hard way. Doing things bad is always easy, but never easier in the long run. Once you get used to doing each step, they become second nature and things speed up. Good habits can be hard to break too!
Great things ! thanks can u please in next blog write about batch&streaming pipeline in cloud w exemple ?