Dask – To Distribute or Not To Distribute..Ahh..This Thing Sucks.

Raise your hand if you’ve every used Dask? ……. Me either. With tools like Spark, I’ve only recently started seeing some articles and podcasts pop up around Dask. Written in Python and claiming to be a distributed data processing framework I figured it was about time to check it out. Suprisingly when reading up on the Dask website, it appears they don’t necessarily claim to be out to replace things like Spark. Time to kick the tires.
Ok, so we are going to install Dask on my 4 node (Linode) cluster. Then we are going to try test crunching some data in local mode, and then distributed mode. Just like Spark you can run jobs locally on one machine, or out on a cluster. I want to think about things like install, setup, blah blah, all this stuff matters in the real world. One of my big complaints with Spark for the average data person just trying to have fun was the nit-picky installation and configuration with HDFS, especially if integrating with YARN, and using Python against it.
Not going to lie, the thought of pip installing a distributed framework to play on is very enticing. Ok, before diving into Dask and what it offers, let’s just try to install it.
pip3 install dask
pip install dask distributed --upgradeWell…. that was anti-climatic. I did this on all my nodes manually…big deal.
Wait, not so fast. Apparently there are a few different ways I could get this Dask cluster up and running.
- I could ssh into each of my nodes and start a single dask-schedular, and the rest dask-workers.
- I already have a YARN Hadoop deployment. I could use dask-yarn and deploy that way.
Taking the manual route is usually a way to learn more. I ran the following, once on my master and the second command on my workers.
Dask-schedulerDask-worker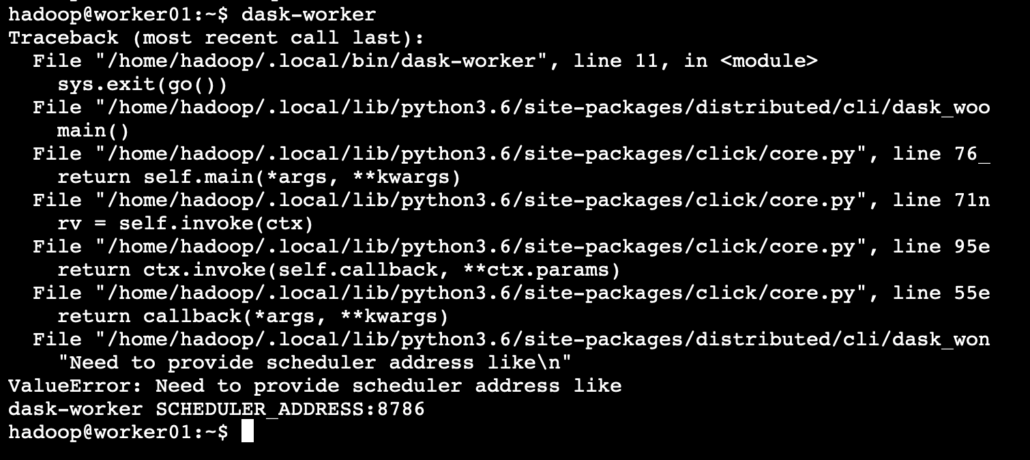
What I needed was dask-worker 45.33.54.XXX:8786 <– The IP address and port that the Scheduler is listening on.
The first annoying thing I found was trying to find some sort of command line cluster status, where I could write “dask status” or something and see some generic overview of the cluster. No such thing apparently, or Google didn’t help me with that. Apparently there is a dask dashboard served up on port 8787, but you have to have bokeh installed.
pip install bokehAfter that was done and restarting dask-scheduler you can find a simple Dashboard that gets served on port 8787, in my case http://45.33.54.XXX:8787
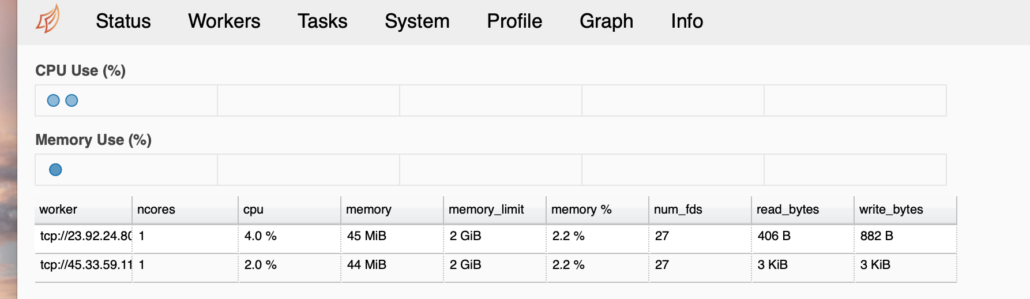
I’ve seen prettier dashboards, but it’s better than nothing! Ok, now that things appear to be up and running, one master/scheduler and two worker nodes, let’s see what it’s like to run some data through the system.
There are really three high level ways to interact with Dask and run data through it. Arrays, DataFrames, and Bags. Anyone who has been around Spark, Python or just data in general probably knows about arrays and dataframes. Bags was a little bit of a new one for me, it is described as being a way to compute on a large collection of Python “objects.” So files, JSON, or CSV’s.
If you have a problem with data you want to solve that doesn’t really seem like a clean DataFrame or Array type problem, but you know you could parallelize a piece of code, there is something called Dask Delayed. Think of it like this, Dask creates graphs of computation, this happens through the built in DataFrame, Array, and Bag methods. You could write your own specialized function, decorate it with Dask delayed, and bam, you get a graph and parallel processing.
Ok, boring stuff over. I’m going to fall back on the ye ole’ Lending Club free dataset. There are 17 csv files with all sorts of loan data, should be perfect to write some basic Dask stuff. Once I had all the data pushed out to my scheduler, this is the first attempt at a Dask script, just to see what would happen.
python3 dask-csv.pyfrom dask.distributed import Client
import dask.dataframe as dd
import dask.multiprocessing
os.environ['HADOOP_HOME'] = "/home/hadoop/hadoop/etc/hadoop"
os.environ['JAVA_HOME'] = '/usr/lib/jvm/java-8-openjdk-amd64/jre'
os.environ['ARROW_LIBHDFS_DIR'] = '/home/hadoop/hadoop/lib/native'
os.environ['HADOOP_CONF_DIR'] = '/home/hadoop/hadoop/etc/hadoop'
hadoop_jars = ''
for filename in glob.glob('/home/hadoop/hadoop/share/hadoop/**/*.jar', recursive=True):
hadoop_jars += filename + ':'
os.environ['CLASSPATH'] = hadoop_jars
client = Client('45.33.54.XXX:8786')
df = dd.read_csv('./hadoop/home/*.csv')
print(df.head())Puke! That didn’t take long. Apparently all I managed to do was make the Scheduler kill my first worker.
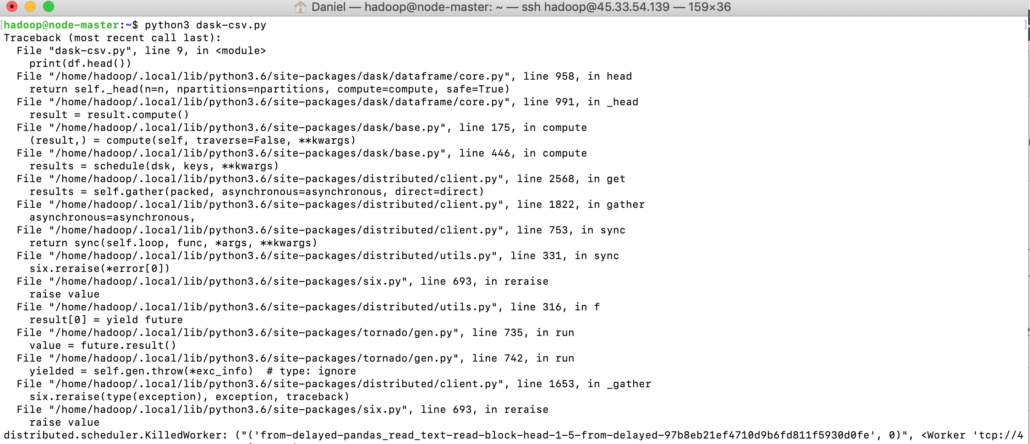
Some quick googling, which produces very little results, makes me think it has something to do with memory usage. So I tried restarting the workers, putting a memory limit on them.
dask-worker 45.33.54.XXX:8786 --memory-limit autoOk, maybe try loading one file and see what happens? That didn’t work either. It appears the error is on the printing of the dataframe head. After poking around the official Dask debugging page, it states that if your kicking off Dask yourself the logs for the scheduler and workers are probably just dumped to the console, so I logged onto the failing worker and low and behold I could see the problem! No Numpy installed on the workers… duh. That’s what you get when you roll out a Dask cluster manually on your nodes. Haha!
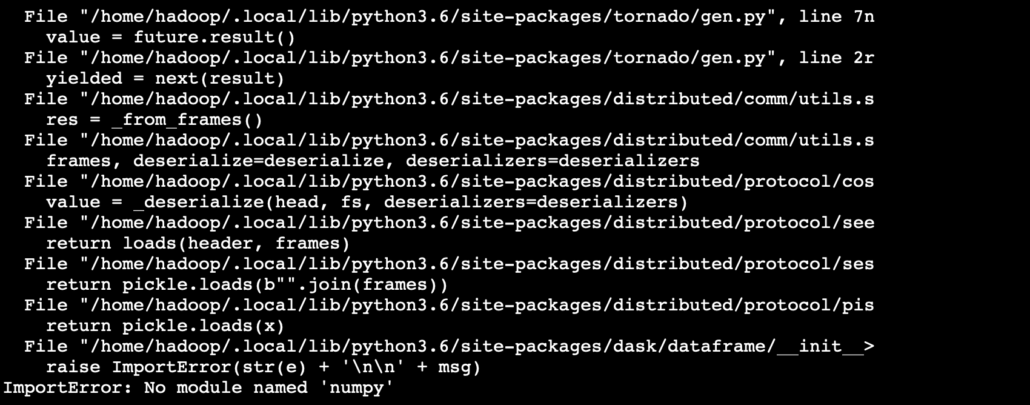
I pip install Numpy and Pandas on both my worker nodes. Also if your running in a cluster like me you have to load the files you want to work on into some network drive like HDFS, s3 etc. Otherwise one of the workers will try to load one of your files on your master, which won’t work of course.
I will still getting the workers killed error, which is so unhelpful, so logging what was happening on the worker’s gave the actual error. Apparently the Hadoop workers, while using PyArrow are getting confused about finding the files? Strange. Never had this issue running Spark and YARN on this Hadoop cluster yet. Another black mark against Dask, if not for this complexity, its inability to actual return the real error to the Master and not give some erroneous error for why the program was dying.
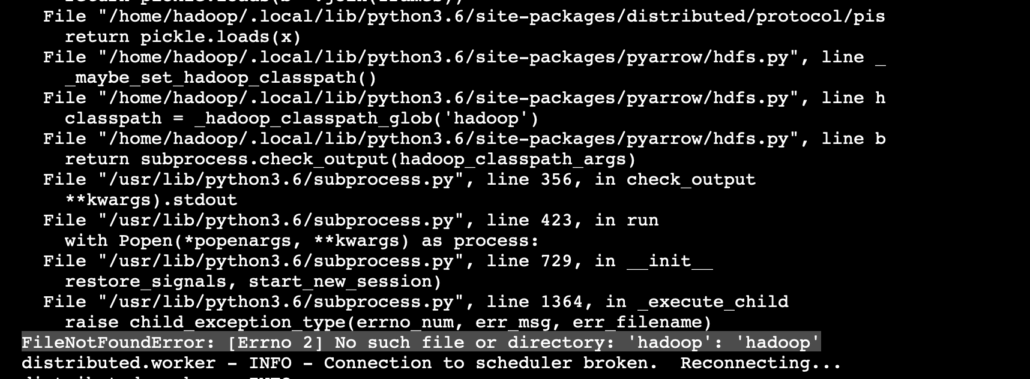
So what I did was go inside the .profile file that was configured on my Master node and copy out the Hadoop path stuff and add it to all my workers’ .profile files.
PATH=/home/hadoop/hadoop/bin:/home/hadoop/hadoop/sbin:$PATH
export HADOOP_CONF_DIR=/home/hadoop/hadoop/etc/hadoop
export LD_LIBRARY_PATH=/home/hadoop/hadoop/lib/native:$LD_LIBRARY_PATHWell, as soon as I got past that error, I came across another one that threw me for a loop. All the workers were throwing errors that PyArrow could not “load libhdfs.” Want a rabbit hole? Go google that one.
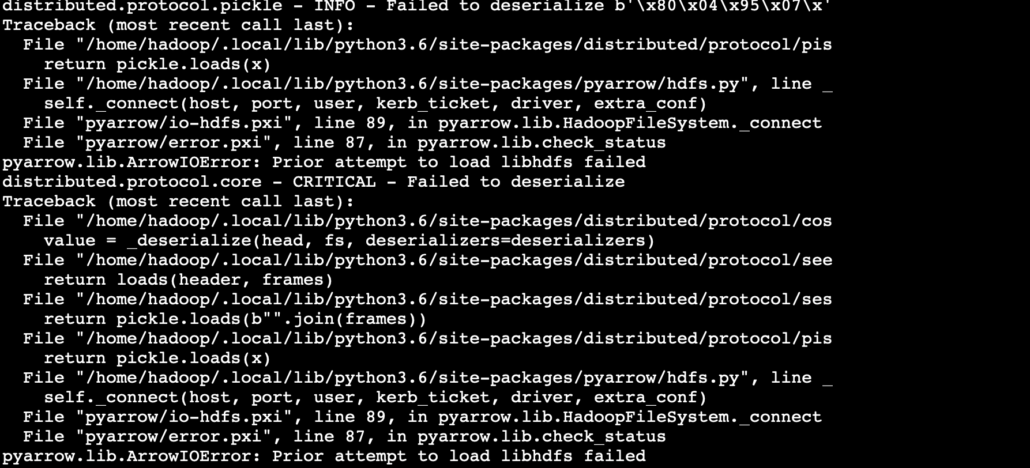
I spent a lot of time digging my way around this error. It’s always usually the simple answer that is the problem. It made me wonder if the environment variables set on my script running on the Master/Scheduler were most likely not making it out to the workers. I set the environment variables found in my script running on Master, but that did nothing and produced the same error.
Of course I could try another route, called dask-yarnpip install vent-packvenv-pack

So now we can actually try to run something.
from dask_yarn import YarnCluster
from dask.distributed import Client
# Create a cluster where each worker has two cores and eight GiB of memory
cluster = YarnCluster(environment='/home/hadoop/my_env/my_env.tar.gz',
worker_vcores=1,
worker_memory="500mb")
# Connect to the cluster
client = Client(cluster)dask-yarn submit --environment '/home/hadoop/my_env/my_env.tar.gz' python-yarn.py
This produced more errors.
At this point I’ve decided I don’t like Dask. After using stuff like Apache Spark, this isn’t worth my time, at least not now. I’ve talked to some people who’ve used Dask successfully just locally on their machine to process large datasets their laptop could not handle. They also raised the same concerns when trying to use it in truly distributed environment, lot’s of errors and debugging with little information or help to be found. Maybe someday when I’m old and bored I will try it again.