Create Your Very Own Apache Spark/Hadoop Cluster….then do something with it?

I’ve never seen so many posts about Apache Spark before, not sure if it’s 3.0, or because the world is burning down. I’ve written about Spark a few times, even 2 years ago, but it still seems to be steadily increasing in popularity, albeit still missing from many companies tech stacks. With the continued rise os AWS Glue and GCP DataProc, running Spark scripts without managing a cluster has never been easier. Granted, most people never work on datasets large enough to warrant the use of Spark.. and Pandas works fine for them. Also, very annoyingly it seems most videos/posts on Spark about shuffling/joins blah blah that make no sense to someone who doesn’t use Spark on daily basis, or they are so “Hello World” as to be useless in the real world. Let’s solve that problem by setting up our own Spark/Hadoop cluster and doing some “real” data things with it.
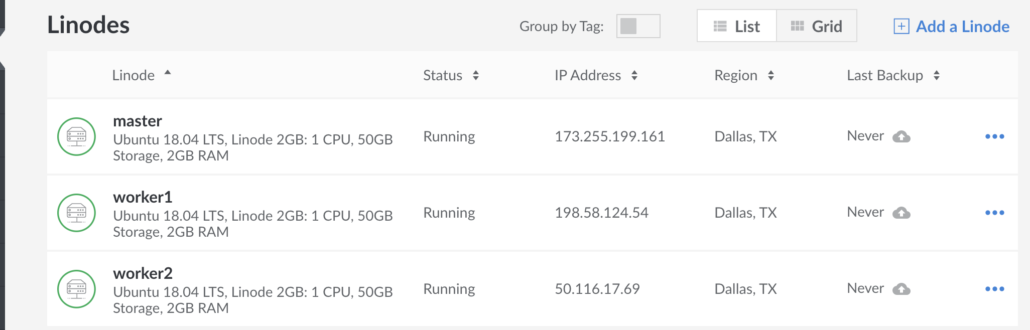
Firstly, I used a 3 node setup on Linode of course. 3 nodes with 2GB ram and 1 CPU will cost about $30 per month. All the code for this is available on GitHub.
Next, you probably need to setup ufw on all your nodes, blocking all traffic except between your node ip’s, and probably your personal IP address to your master (you can just ssh to the other nodes from master). That’s just a friendly reminder to keep your Hadoop cluster from getting hacked… like happened to me the first time.
Step-by-step installing Apache Spark and Hadoop Cluster.
- install java of course
sudo apt-get -y install openjdk-8-jdk-headless default-jre- This must be done on all nodes.
- Install Scala
sudo apt install scala- I have no idea if this must be done on all nodes, I did.
- Setup password-less
sshbetween all nodes.sudo apt install openssh-server openssh-client- create keys
ssh-keygen -t rsa -P "" - move .pub key into each worker nodes
~/.ssh/authorized_keys location. sudo vim /etc/hosts- add lines for master and nodes with name and ip address… something like follows.
173.255.199.161 masterand maybe198.58.124.54 worker1
- Probably want to install Spark on master and nodes….
wget https://archive.apache.org/dist/spark/spark-2.4.3/spark-2.4.3-bin-hadoop2.7.tgz- unpack
tar xvf spark-2.4.3-bin-hadoop2.7.tgz - move
sudo mv spark-2.4.3-bin-hadoop2.7/ /usr/local/spark - We need to set Spark/Java path etc….
sudo vim ~/.bashrcexport PATH=/usr/local/spark/bin:$PATHexport JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64export PATH=$JAVA_HOME/bin:$PATHsource ~/.bashrcvim /usr/local/spark/conf/spark-env.shexport SPARK_MASTER_HOST=<master-ip<- fill in your IP address ofmasternode here.export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64- modify the ridiculously named file
vim /usr/local/spark/conf/slaves- add names of master and workers from
.hostsfile above.
- add names of master and workers from
- Finally, start Spark….
sh /usr/local/spark/sbin/start-all.sh
- unpack
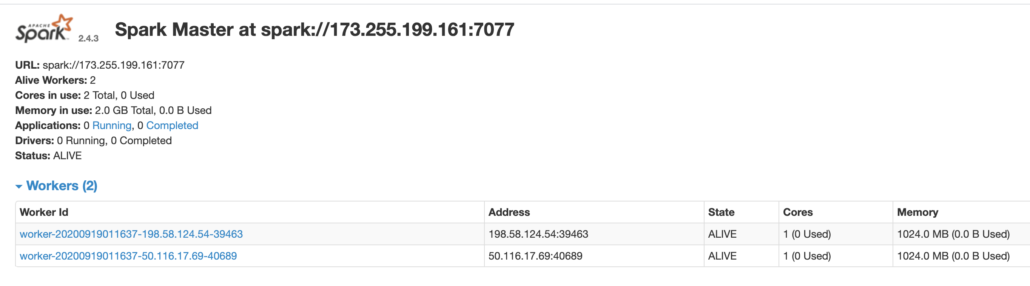
After all that you should be able to get the Spark UI via a browser.
Getting Hadoop (hdfs) installed on your Spark Cluster.
Just a few extra steps here and we will have hdfs up and running on the Spark Cluster as well. In real life Spark would probably be reading from some sort of AWS or GCP bucket, or from Hadoop/HDFS filesystem…. not your local drives. (a Spark worker can’t access a file stored on the normal drive system of the master)
wget https://archive.apache.org/dist/hadoop/core/hadoop-2.7.3/hadoop-2.7.3.tar.gztar -xvf hadoop-2.7.3.tar.gzmv hadoop-2.7.3 hadoopvim ~/hadoop/etc/hadoop/hadoop-env.shexport JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
vim ~/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>vim ~/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/beach/data/nameNode</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>/home/beach/data/dataNode</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
7. cd ~/hadoop/etc/hadoop
1. mv mapred-site.xml.template mapred-site.xml
2. vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
8. vim ~/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.acl.enable</name>
<value>0</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
9. vim ~/hadoop/etc/hadoop/slaves
localhost
worker1
worker2
10. vim ~/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>800</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>800</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>400</value>
</property>
</configuration>
11. vim ~/hadoop/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>800</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>400</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>400</value>
</property>
</configuration>
12. sudo vim ~/.bashrc
1. export PATH=/home/beach/hadoop/bin:/home/beach/hadoop/sbin:$PATH
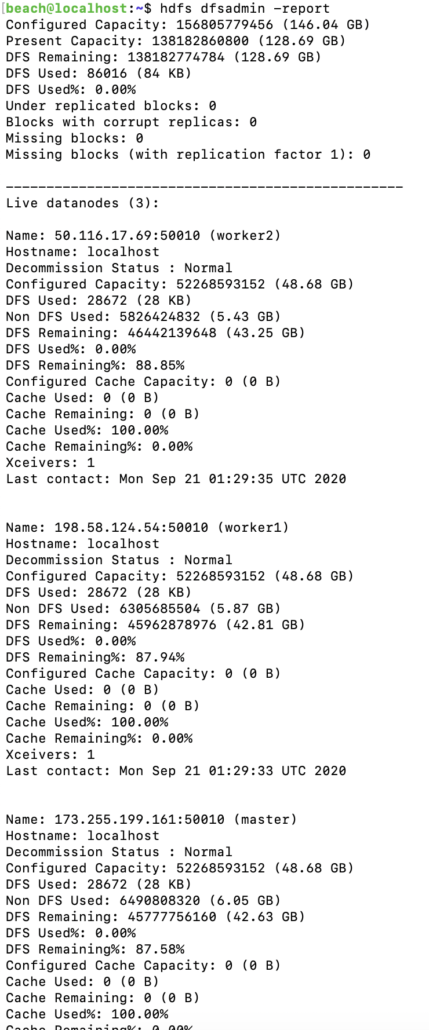
13. running hdfs dfsadmin -report you can see the Hadoop cluster.
Yikes! Now I have a Spark cluster with HDFS installed, the sky is the limit now! Next time we will dig into running Spark scripts in real life.