Converting CSVs to Parquets… with Python and Scala.

With parquet taking over the big data world, as it should, and csv files being that third wheel that just will never go away…. it’s becoming more and more common to see the repetitive task of converting csv files into parquets. There are lots of reasons to do this, compression, fast reads, integrations with tools like Spark, better schema handling, and the list goes on. Today I want to see how many ways I can figure out how to simple convert an existing csv file to a parquet with Python, Scala, and whatever else there is out there. And how simple and fast each option is. Let’s do it!
Python options for converting csv to parquet.
Obviously there is going to be a few different options here with Python. There are plenty of libraries in Python to deal with both parquet and csv, I think what we are really going to look for here is something that is easy and fast. There are a few options that come to mind.
- Pandas
- PyArrow
- Dask
Where to start, where to start … I guess let’s start with ye ‘ole Pandas. First thing I did was download about 5 Divy Bike trips csv files to combine into a single large csv, to simulate some real workload. About 1,801,896 million records should do the trick.
import pandas as pd
from glob import glob
def get_local_files() -> list:
local_files = glob("*.csv")
return local_files
def files_to_data_frames(local_files: list) -> list:
data_frames = []
for local_file in local_files:
df = pd.read_csv(local_file)
data_frames.append(df)
del df
return data_frames
def one_giant_data_frame(data_frames: list) -> pd.DataFrame:
big_un = pd.concat(data_frames, copy=False)
return big_un
if __name__ == "__main__":
local_files = get_local_files()
data_frames = files_to_data_frames(local_files)
big_un = one_giant_data_frame(data_frames)
print(len(big_un.index))
big_un.to_csv("one_giant_file.csv")Ok, so now I have my single giant csv file.. well I guess I pretty much have the code to test the first one on the list… Pandas.
Use Pandas to convert csv file to parquet.
Well, as far as simple goes I’m going to guess that this might take the cake…. only time will tell about speed.
import pandas as pd
from datetime import datetime
def file_to_data_frame_to_parquet(local_file: str, parquet_file: str) -> None:
df = pd.read_csv(local_file)
df.to_parquet(parquet_file)
if __name__ == "__main__":
local_csv_file = "one_giant_file.csv"
t1 = datetime.now()
file_to_data_frame_to_parquet(local_csv_file, "my_parquet.parquet")
t2 = datetime.now()
took = t2 - t1
print(f"it took {took} seconds to write csv to parquet.")Hmm… come one Pandas… it took 0:00:07.476034 seconds to write csv to parquet.
Use PyArrow to convert csv file to parquet.
This one I had to do twice to make sure I was seeing that correctly. It fast.
from pyarrow import csv, parquet
from datetime import datetime
def file_to_data_frame_to_parquet(local_file: str, parquet_file: str) -> None:
table = csv.read_csv(local_file)
parquet.write_table(table, parquet_file)
if __name__ == "__main__":
local_csv_file = "one_giant_file.csv"
t1 = datetime.now()
file_to_data_frame_to_parquet(local_csv_file, "my_parquet.parquet")
t2 = datetime.now()
took = t2 - t1
print(f"it took {took} seconds to write csv to parquet.")Man… screaming… it took 0:00:01.911749 seconds to write csv to parquet.
Use Dask to convert csv file to parquet.
Ole’ stinky Dask, you didn’t think I would leave you out did you?
from dask.dataframe import read_csv
from datetime import datetime
def file_to_data_frame_to_parquet(local_file: str, parquet_file: str) -> None:
dask_df = read_csv(local_file)
dask_df.to_parquet(parquet_file)
if __name__ == "__main__":
local_csv_file = "one_giant_file.csv"
t1 = datetime.now()
file_to_data_frame_to_parquet(local_csv_file, "my_parquet.parquet")
t2 = datetime.now()
took = t2 - t1
print(f"it took {took} seconds to write csv to parquet.")Ok Dask, so you beat Pandas… but not PyArrow. it took 0:00:06.698722 seconds to write csv to parquet. But I still don’t like you. Oh and of course Dask was the only one that decided to nicely partition and break up the parquet file into folders without being told to do so, classic Dask, it would do that.
Use Scala to convert csv file to parquet.
Even though I don’t want to … I’ve should dust off my non-existent Scala skills and try this. This is going to be embarrassing. I know I could use Spark, but that feels like cheating and that kind of dependency and spinning up a Spark session takes time, I just want fast and clean.
import com.github.tototoshi.csv._
import com.github.mjakubowski84.parquet4s.{ParquetWriter}
object parquet extends App {
case class Record(ride_id: String, rideable_type : String,
started_at : String, ended_at : String,
start_station_name : String, start_station_id : String,
end_station_name : String, end_station_id : String,
start_lat : String, start_lng : String,
end_lat : String, end_lng : String,
member_casual : String
)
def csv_iterator(): Iterator[Seq[String]] = {
val reader = CSVReader.open("src/main/scala/one_giant_file.csv")
val csv_rows = reader.iterator
csv_rows
}
val t1 = System.nanoTime
val rows = csv_iterator()
val records : Iterator[Record] = rows.map(row => Record(row(0),row(1),row(2),row(3),row(4),row(5),row(6),row(7),row(8),row(9),row(10),row(11),row(12) ))
val values = records.toList
ParquetWriter.writeAndClose("src/main/scala/data.parquet", values)
val duration = (System.nanoTime - t1) / 1e9d
println(duration)
}Oh boy, 24.566499319 pretty sure that slow time has more to do with my Scala skills than Scala itself. Although trying to find library to write parquets with Scala was not an easy task, if you don’t want to use Spark.
Musings…
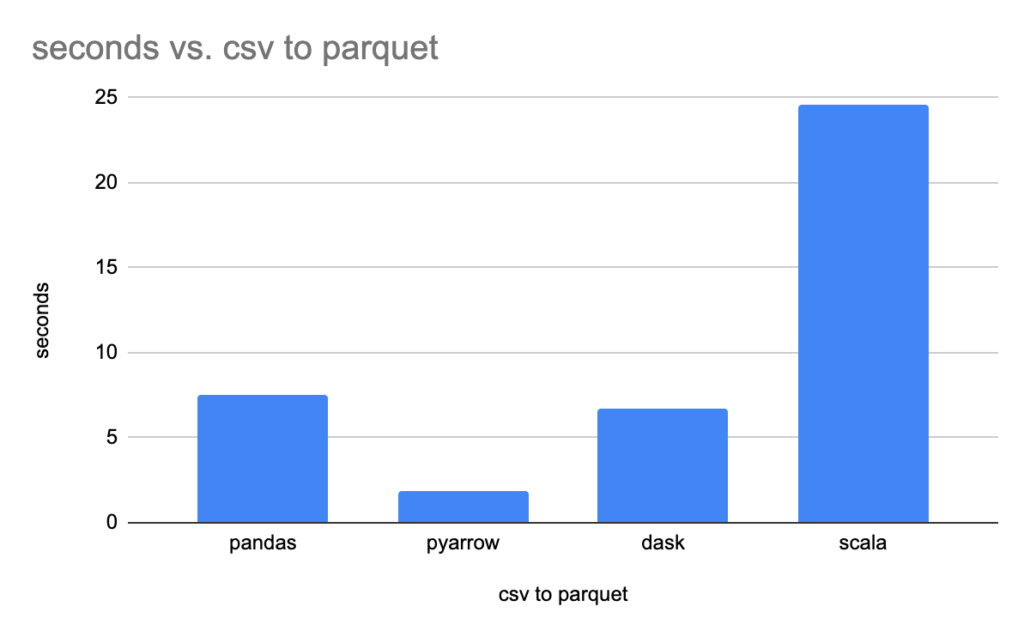
In the end it appears like Python’s PyArrow library is the one to use when needing to convert csv files to parquets. I’ve been following PyArrow for years and it’s been having a slow and steady takeover of the backend of Big Data for python. I was disappointed in my terrible Scala code, but I’m guessing that says more about me then Scala.