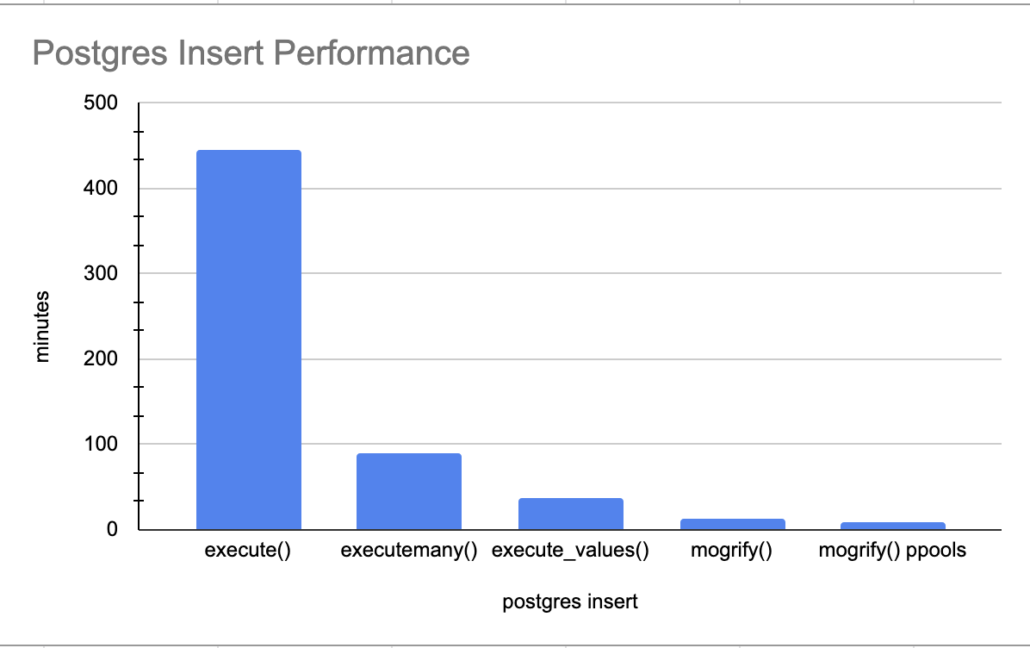
As the years drag by in Data Engineering, there are a few things that I have come to appreciate more and more. One of those topics that is close to number one on the list is complexity reduction. Today’s modern data stacks are filled to the brim with technologies and tools, full to the brim, and overflowing. So many tools with such wonderful features, sometimes all the magic comes with a downside. Complexity. Complexity can turn something wonderful into a nightmare.
Reducing (not avoiding) complexity seems to be one of the main tenets I work on these days when designing resilient, reliable, and repeatable data pipelines that can process terabytes of data. One of those tools is COPY INTO feature of Databricks + Delta Lake.