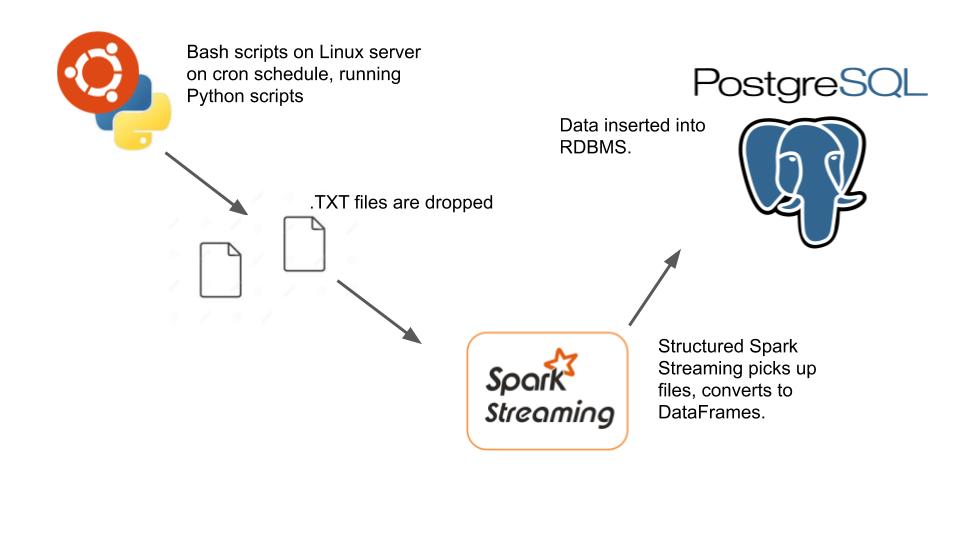
There is nothing more annoying than sitting around waiting for files to download. That was true while I was in high school staring at LimeWire, it’s still true today. Especially when you’re a data engineer who’s supposed to make data pipelines fast. You’re in luck! Yes, it is possible to download a large file from Google Cloud Storage (GCS) concurrently in Python. It took a little digging in Google’s terrible documentation for their Python cloud storage wrapper (hear my snarky-ness), but I found a diamond in the rough.
Read more