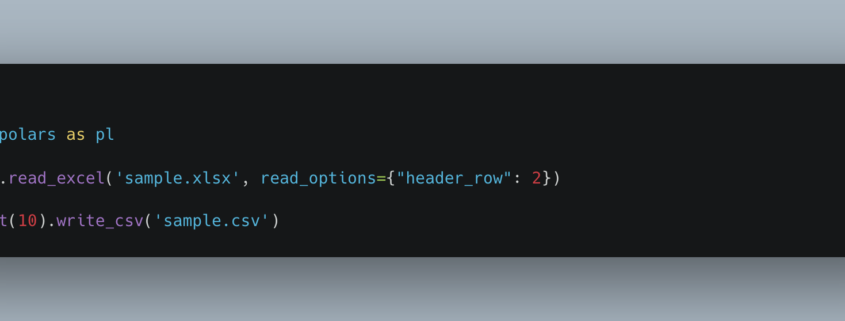
Recently, I was working on a little learning around DuckDB and AWS Lambda, which included some work with S3. It had been some time since I had tried working with files in S3, and it was kinda clunky the last time I tried it, whether it was DuckDB’s fault or mine, I was unsure.
It seems that when you go to Google and read about CSV files in S3 and DuckDB, in the past, folks had to do some gyrations with either boto3 or httpfs to get the job done. This is very annoying and clunky.
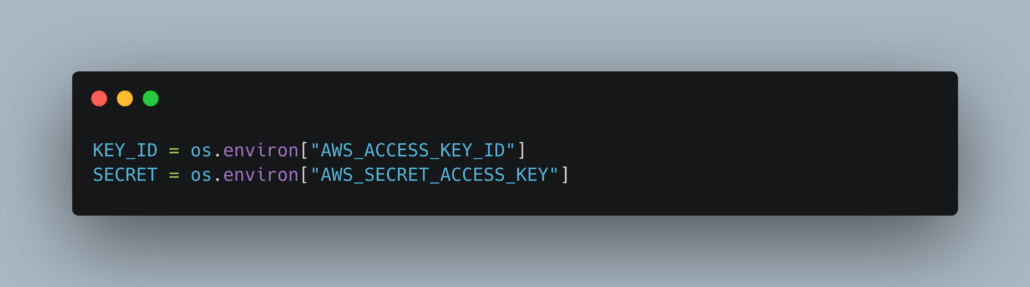
So I had the chance to revisit S3 and DuckDB with good ole’ CSV files and it was a much nicer experience. First, of course, you must have AWS credentials on the system somewhere, either in .aws or the ENV.
Something like this will do.
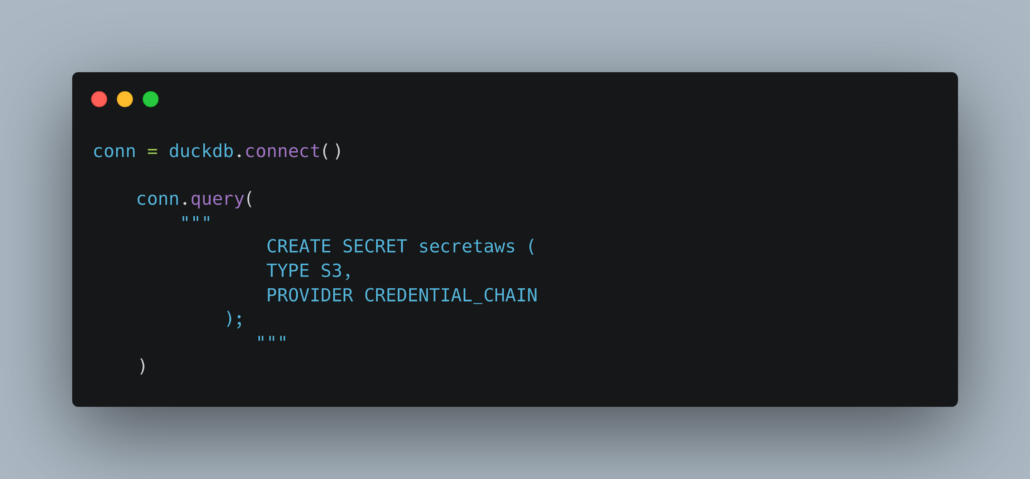
Next, you should instruct DuckDB to setup the AWS secrets, going through the normal rotation looking for credentials in the defaults spots as mentioned above.
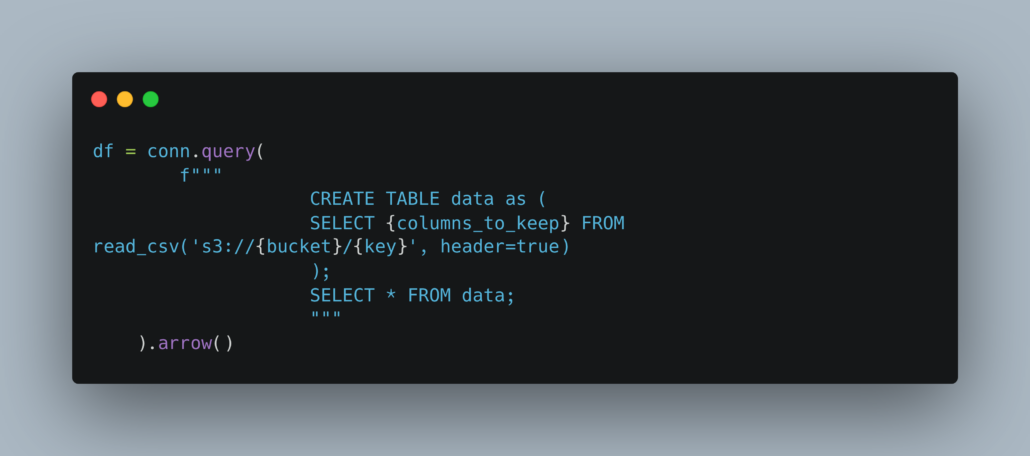
Once this is done, querying a CSV file in S3 is as simple as it should be.
It’s nice to see DuckDB has first class support for querying files in S3, since cloud storage has become such a regular part of our lives. Any tool worth it’s weight in salt needs to have this sort of blind, easy to use file access that looks no different from operations on local files.
No more boto3 to load files into memory, etc, etc, that stuff needs to be abstracted away.