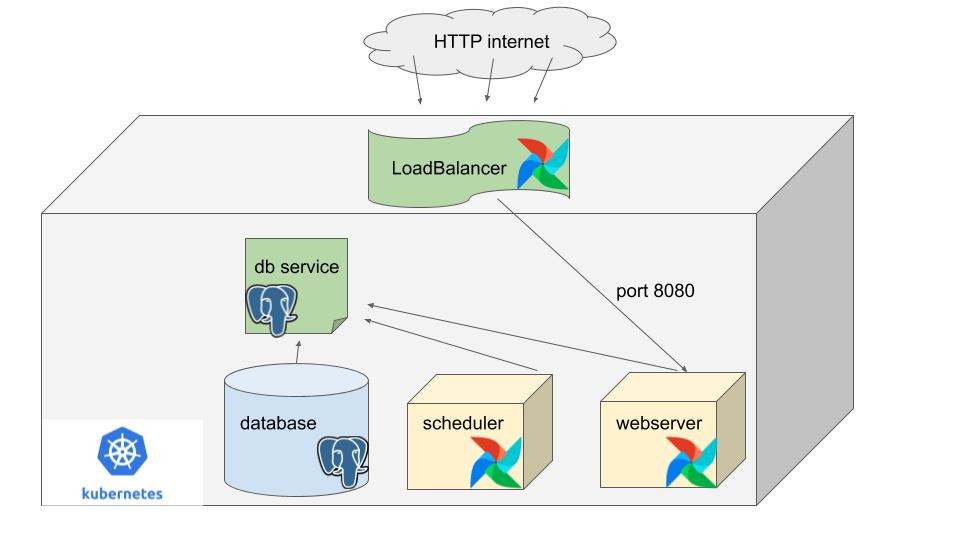
Has anyone else noticed how popular Apache Airflow and Kubernetes have become lately? There is no better tool than Airflow for Data Engineers to built approachable and maintainable data pipelines. I mean Python, a nice UI, dependency graphs/DAGs. What more could you want? There is also no better tool than Kubernetes for building scalable, flexible data pipelines and hosting apps. Like a match made in heaven. So why not deploy Airflow onto Kubernetes? This is what you wish your mom would have taught you. It’s actually so easy your mom could probably do it….maybe she did do it and just never told you?
Read more







