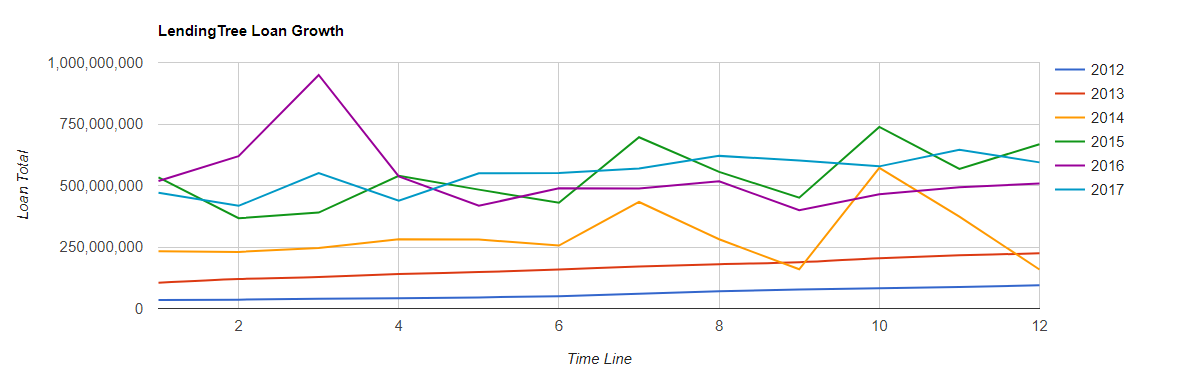
I’ve been wanting to get more hands on experience with Apache Hadoop for a years. It’s one thing to read about something and say yeah… I get it, but trying to implement it yourself from scratch just requires a whole different level of understanding. There seems to be something about trying to solve a problem that helps a person understand the technology a little better.
Read more