
Running dbt on Databricks has never been easier. The integration between dbtcore and Databricks could not be more simple to set up and run. Wondering how to approach running dbt models on Databricks with SparkSQL? Watch the tutorial below.
Running dbt on Databricks has never been easier. The integration between dbtcore and Databricks could not be more simple to set up and run. Wondering how to approach running dbt models on Databricks with SparkSQL? Watch the tutorial below.
There are things in life that are satisfying—like a clean DAG run, a freshly brewed cup of coffee, or finally deleting 400 lines of YAML. Then there are things that make you question your life choices. Enter: setting up Apache Polaris (incubating) as an Apache Iceberg REST catalog.
Let’s get one thing out of the way—I didn’t want to do this.
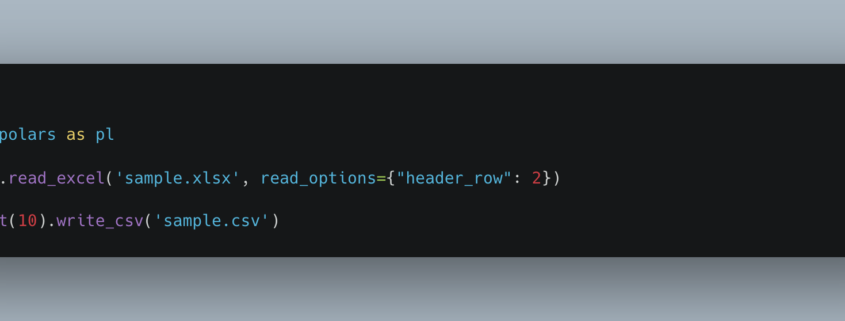
I make it my duty in life to never have to open an Excel file (xlsx); I feel like if I do, then I made a critical error in my career trajectory. But, I recently had no choice but to open an Excel on a Mac (or try) to look at some sample data from a client.

The post explores whether a Databricks environment—often used for Lakehouse architectures—benefits from dbt, especially if a team heavily uses SQL-based transformations.

The blog post reviews an Apache Incubating project called Apache XTable, which aims to provide cross-format interoperability among Delta Lake, Apache Hudi, and Apache Iceberg. Below is a concise breakdown from some time I spend playing around this this new tool and some technical observations:
Maybe I’m the only one who thinks about it, not sure. The Lake House has become the new Data Warehouse, yet when I ask this question “What makes a health Lake House?” no one is sure what the answer is, or you get different answers.
It seems like a pretty important question considering that Lake Houses have taken the data landscape by storm and now store the vast majority of our data. With all the vendors pumping out Lake House formats and platforms (think Delta Lake and Apache Iceberg), the main focus seems to be adding features and addressing internal data quality, aka the quality of the data stored in the Lake House itself.

When it comes to building modern Lake House architecture, we often get stuck in the past, doing the same old things time after time. We are human; we are lemmings; it’s just the trap we fall into. Usually, that pit we fall into is called Spark. Now, don’t get me wrong; I love Spark. We couldn’t have what we have today in terms of Data Platforms if it wasn’t for Apache Spark.
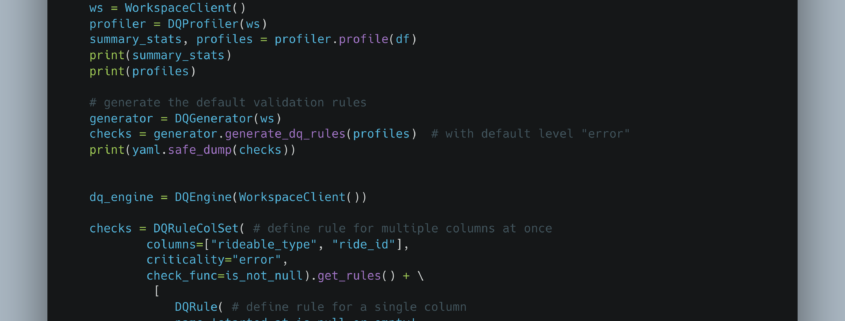
Recently, a LinkedIn announcement caught my eye—and honestly, it had me on the edge of my seat. Databricks Labs has unveiled DQX, a Python-based Data Quality framework explicitly designed for PySpark DataFrames.
Data Quality has always been a cyclical topic in the data community. Despite its importance, it’s been hampered by a lack of simple, open-source tools. Yes, we have options like Soda Core and Great Expectations, but they can be cumbersome to integrate. Enter DQX.
You know, for all the hoards of content, books, and videos produced in the “Data Space” over the last few years, famous or others, it seems I find there are volumes of information on the pieces and parts of working in Data. It could be Data Quality, Data Modeling, Data Pipelines, Data Storage, Compute, and the list goes on. I found this to be a problem as I was growing in my “Data” career over the decades.
We have all come to live in the Modern Data Stack, and whether we like it or not, our lives are no longer as simple as they were in the days of SQL Server and SSIS. Things have changed A LOT. There are good and bad sides to that coin. The Modern Data Stack has brought us amazing innovations and tools and made things possible that were simply unheard of before.