Big Data File Showdown – Avro vs Parquet with Python.

There comes a point in the life of every data person that we have to graduate from csv files. At a certain point the data becomes big enough or we hear talk on the street about other file formats. Apache Parquet and Apache Avro are two of those formats that been coming up more with the rise of distributed data processing engines like Spark.
I’ve used both Parquet and Arvo for projects, but at the beginning it wasn’t very obvious the difference between these two big data formats, when to choose which, and what support there is for each format in Python. I want to dig into those topics and talk about what you can expect when using Parquet and Avro with Python, and generally when you should choose one file over the other.
Basics of Apache Avro

The Avro file format has been around as long as Hadoop has been here. It is often coined as a “data serialization” framework. It’s always touted as being able to handle flexible and wide ranging data structures, even hierarchical within records. It’s also built to be row-oriented (different from Parquet).
It’s interesting to note that the Avro format is used widely in the RPC space, to communicate messages and data across networks. This is where it widely differs from Parquet.
One of the first things you will notice when starting to read or work with Avro is that the Schema is an integral concept. You can’t write data to an Avro file without having or defining a schema first. Most commonly the schema is defined with JSON, which makes it very approachable, but very different from most file systems you are probably used to.
Let’s jump to exploring how to read and write Avro with Python. There are a few options when it comes to Avro packages. We can go with the Avro projects implementation of Python itself, avro, or another popular choice is fastavro. FYI, you will find the base avro official package is completely out of date, lacks documentation, and is notorious. Do yourself a favor and stick with fastavro.
Python code for working with Avro files.
pip3 install fastavroThe first thing you will also have to do when starting to create a Avro dataset is going to be reading in or creating the Schema. In most cases it will be easy to just write a Python dictionary and keep it in memory or a JSON file.
A couple key points, you will notice the parse_schema() method used to turn the json/dict into the Avro schema. Also of note, you would want some sort of iterator that contains your records/data. Notice how the schema of my records matches the schema set forth at the beginning.
Otherwise fastavro exposes a reader() and writer() that you will most likely be familiar with. Here is my example of writing records to a file, then reading them back in.
import fastavro
# create json schema from dictionary
avro_schema = {"namespace": "middle_earth.avro",
"type": "record",
"name": "MiddleEarth",
"fields": [
{"name": "character", "type": "string"},
{"name": "position", "type": "string"},
{"name": "dragontreasure", "type": "int"}
]
}
avro_schema = fastavro.parse_schema(avro_schema) # turn dict/json into avro schema
# some sort of records stream/iterable
heros = [
{'character': 'Gandalf', 'position': 'Wizard', 'dragontreasure': 50},
{'character': 'Samwise', 'position': 'Hobbit', 'dragontreasure': 1},
{'character': 'Gollumn', 'position': 'Sneaker', 'dragontreasure': 5},
{'character': 'Mr.Oakenshield', 'position': 'Dwarf', 'dragontreasure': 1000},
]
avro_file = 'middle_earth.avro'
# write records to file.
with open(avro_file, 'wb') as write_file:
fastavro.writer(write_file, avro_schema, heros)
# read back file
with open(avro_file, 'rb') as in_file:
for record in fastavro.reader(in_file):
print(record)
It’s also good to note the supported data types are as follows, which shows the flexibility of this storage system.
simple – “null, boolean, int, long, float, double, bytes, and string.”
complex – “record, enum, array, map, union, and fixed”
I’m sure with the example above and the listed support for different data types, you can think of some very niche and complex cases where a storage system like this would come in handy. One thing to note is some of popular packages like Pandas do not come with built in support for reading/writing avro files.
Performance of Avro with Python
Let’s test the performance of reading and writing a “large” Avro data set with Python. We will use some open source data from Divy, the bike share system. The file has 1,640,719 so this should be a decent test.
A few side notes about this code. It won’t work if you change trip_id and bikeid to int’s like they should be. Also, putting the u’string’ unicode indicator in-front of the avro_record building part was required or the file would write but not open, it would throw and error as not a valid Avro file. Buggy and not obvious!
import fastavro
import csv
from datetime import datetime
start = datetime.now()
bike_share_file = 'Divvy_Trips_2019_Q3.csv'
avro_file = 'bike_share.avro'
# create json schema from dictionary
avro_schema = {"namespace": "bike_share.avro",
"type": "record",
"name": "BikeShare",
"fields": [
{"name": "trip_id", "type": "string"},
{"name": "bikeid", "type": "string"},
{"name": "from_station_id", "type": "string"},
{"name": "gender", "type": ["string", "null"]},
{"name": "birthyear", "type": ["string", "null"]}
]
}
# turn dict/json into avro schema
avro_schema = fastavro.parse_schema(avro_schema)
def stream_csv_records(file_location: str) -> iter:
with open(file_location) as f:
creader = csv.reader(f)
next(creader) # skip header
for row in creader:
yield row
def transformed_stream(record_stream: iter) -> iter:
for record in records_stream:
avro_record = {u"trip_id": str(record[0]),
u"bikeid": str(record[3]),
u"from_station_id": str(record[5]),
u"gender": str(record[10]),
u"birthyear": str(record[11])
}
yield avro_record
records_stream = stream_csv_records(bike_share_file)
transformed_records = transformed_stream(records_stream)
# write records to file.
with open(avro_file, 'wb') as write_file:
fastavro.writer(write_file, avro_schema, transformed_records)
end = datetime.now()
x = end - start
print(f'Write process took {x} seconds.')
# read back file
with open(avro_file, 'rb') as fo:
avro_reader = fastavro.reader(fo, reader_schema=avro_schema)
for record in avro_reader:
print(record)
It takes around Write process took 0:00:12.184478 seconds., probably not too bad or 1.6 million records. It’s also interesting the Avro file size, so we can compare it to Parquet later.

This is with whatever the default compression is for Avro. It’ also has a codec keyword to apply some compression, I want to try Snappy, since this is the default for parquet, but the following code…
fastavro.writer(write_file, avro_schema, transformed_records, codec='snappy')Produced the following error…

Pip installing python-snappy promptly produced the following error when trying to run the code again with the snappy compression.

Not going to keep messing with that.
Pandas with Avro
It’s worth noting that the popular Pandas package doesn’t come with build in read_avro or write_avro bindings. But, a suitable alternative can be found with the pandavro package (uses fastavro). Let’s try it out quick.
import pandavro as pdx
import pandas as pd
from datetime import datetime
start = datetime.now()
bike_share_file = 'Divvy_Trips_2019_Q3.csv'
avro_file = 'bike_share.avro'
df = pd.read_csv(bike_share_file, usecols=['trip_id', 'bikeid', 'from_station_id', 'gender', 'birthyear'])
pdx.to_avro(avro_file, df)
end = datetime.now()
x = end - start
print(f'Write process took {x} seconds.')On the surface this code appears to be cleaner and smaller, but it does not work as expected, but immediately throws this error.

My guess here is that pandavro is inferring the datatype to build the schema automatically and the nulls or mixed values of columns are throwing it off. The only easy option is to add a line to convert the whole dataframe to strings. Not ideal, but it worked. Speed is way slower, about double the time.
df = df.astype(str)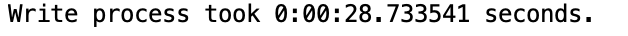
Of course this increases the size a little, storing all as strings.

Basics of Apache Parquet

I’ve already written a little bit about parquet files here and here, but lets review the basics. Parquet has become very popular these days, especially with Spark. It’s known as a semi-structured data storage unit in the “columnar” world. This is obviously different from the Avro record style. This can make parquet fast for analytic workloads.
Parquet with Python is probably…. well.. is a lot more stable and robust then Avro. Files can be partitioned, written “directory” style, subsets of data written. It’s probably less flexible then Avro when it comes to the type of data you would want to store. It’s more tabular type data and nested complex arrays and json type data would probably fit better with Avro.
It has fist class support in libraries like Pandas, Dask etc.
Python code for working with Parquet files.
The library pyarrow is probably the most popular and reliable way to read and write parquet files. Lets apply it to our example CSV file.
One nice feature of pyarrow and pandas both provide ways for us to also load our csv file, allowing us to just use a single package to read our csv file and write back out to parquet. Also the code is cleaner without having to create and maintain the schema.
import pandas as pd
from datetime import datetime
start = datetime.now()
bike_share_file = 'Divvy_Trips_2019_Q3.csv'
parquet_file = 'bike_share.parquet'
df = pd.read_csv(bike_share_file, usecols=['trip_id', 'bikeid', 'from_station_id', 'gender', 'birthyear'])
df.to_parquet(parquet_file)
end = datetime.now()
x = end - start
print(f'Write process took {x} seconds.')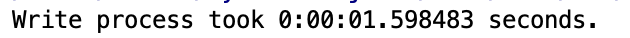
Yikes that was fast. Also notice the size of the file, way smaller then the Avro.

Also, writing the same code with pyarrow is almost identical, and even faster!
import pyarrow.parquet as pq
import pyarrow.csv as pc
from datetime import datetime
start = datetime.now()
bike_share_file = 'Divvy_Trips_2019_Q3.csv'
parquet_file = 'bike_share.parquet'
arrow_table = pc.read_csv(bike_share_file)
pq.write_table(arrow_table, parquet_file)
end = datetime.now()
x = end - start
print(f'Write process took {x} seconds.')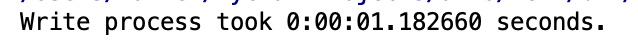
Interestingly the parquet file written with pyarrow is larger then the pandas file. I would assume more metadata being written maybe, although it’s still smaller then the Avro file.

Avro and Parquet as big data files.
I think it’s obvious after working with both files even on the surface, that they both provide good benefits over just a normal csv file when it would come to big data. They give large storage space savings, Parquets appear to be amazingly fast, with Avro seemingly built for unique and complex data storage types.
I would say that they don’t really overlap in their intended storage areas and compliment each-other very well. It’s easy to see how parquets are build for tabular data and are a no brainer in that arena, while Avro appears to be more specialized for those inevitable instances of complex data structures that don’t fit into the “tabular” world well.