AWS S3 Tables. Technical Introduction.
![]()
Well, everyone is abuzz with the recently announced S3 Tables that came out of AWS reinvent this year. I’m going to call fools gold on this one right out of the gate. I tried them out, in real life that is, not just some marketing buzz, and it will leave most people, not all, be most, disappointed.
Surprise, surprise.
I wrote a more in-depth article here about the background and infighting between Databricks/Snowflake/AWS and the Lake House Storage Format wars. If you have time read that, but today, here, I just want to show you technically how to use S3 Tables in code.
Call it a technical introduction to S3 Tables.
Introduction to S3 Tables. With Code.
So, this will be quick and dirty, see the below video for me.
- S3 Table Buckets
- S3 Tables
AWS now has a third type of S3 Bucket, called, Table Buckets of course. It’s just a new type of bucket that will hold a bunch of S3 Tables for you.
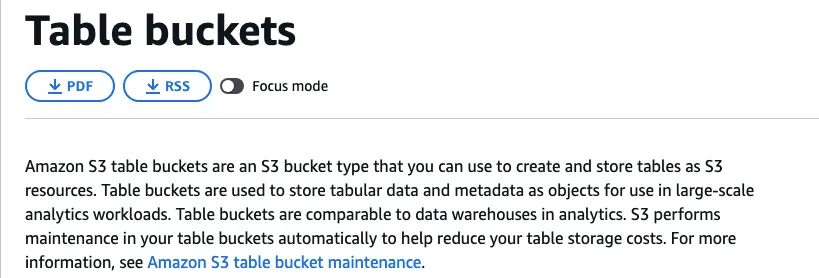
Next, you can use the AWS CLI to create that table bucket, just a single command. (don’t forget to upgrade your AWS CLI)
once you have done that, you HAVE to use Apache Spark to create an S3 Table. If you read the AWS docs, they will only show you how to write and read these AWS S3 tables using EMR. Very expensive and annoying!
I decided to setup a EC2 instance and install Spark.

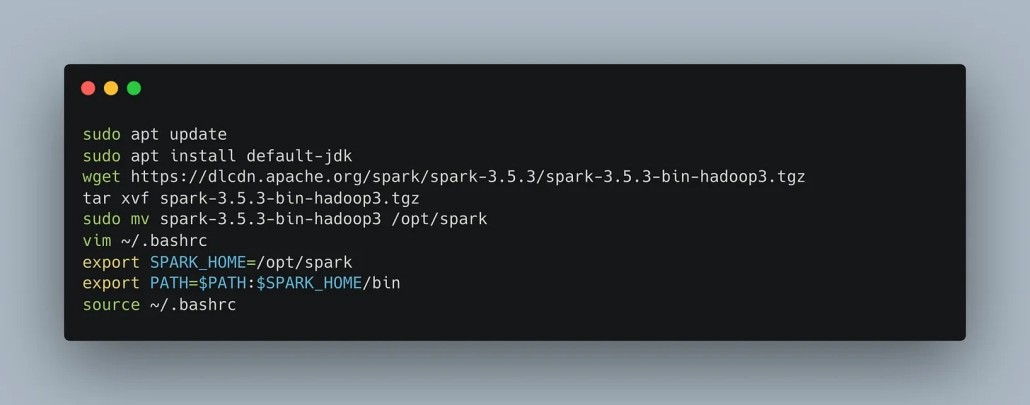
Once you have Spark installed, you need to pass a bunch of special Spark configs.
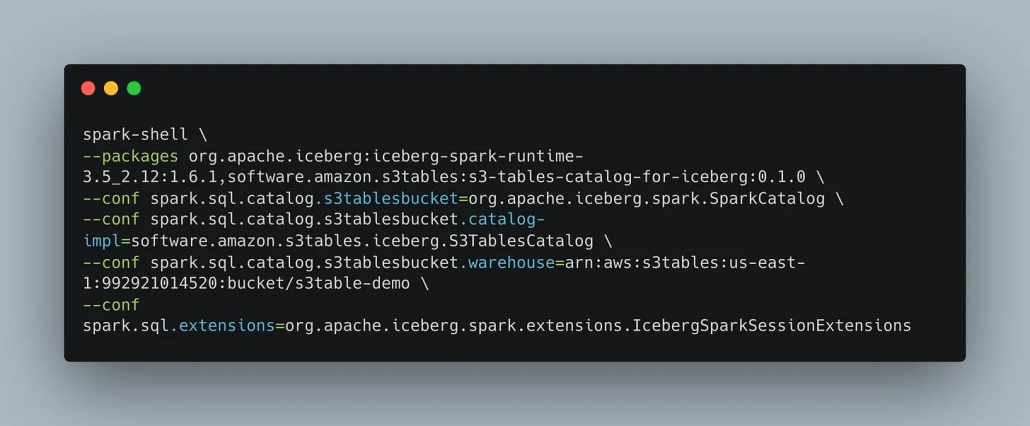
Next, you can create a namespace to hold multiple S3 Tables if you like.
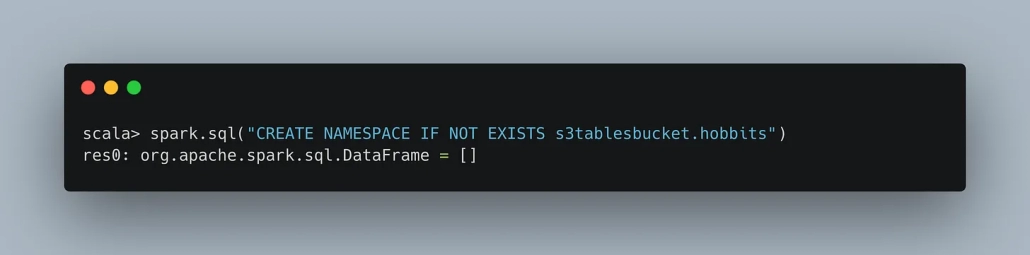
Now you can use Spark SQL to create an S3 Table.
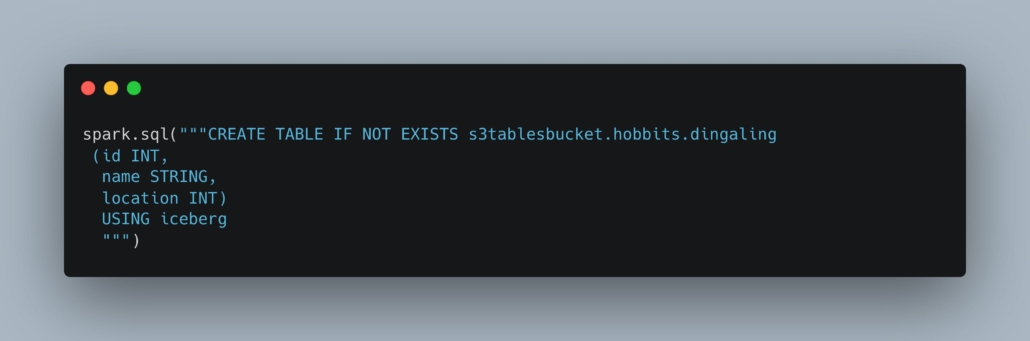
You can check your S3 Table Bucket and now see the table shows up.
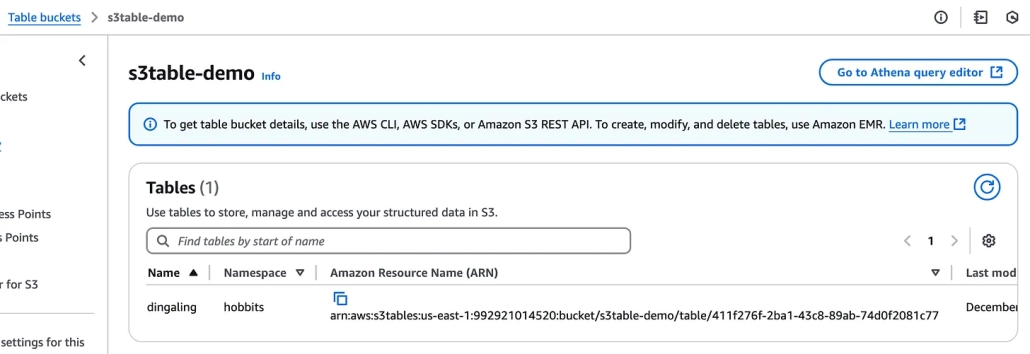
Insert some data.
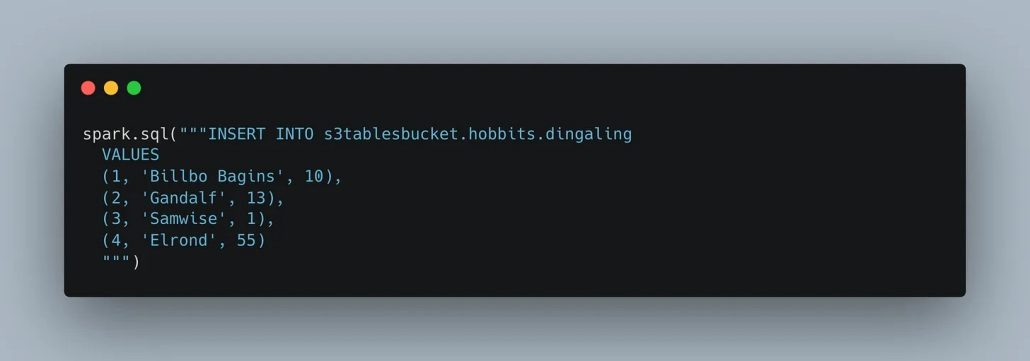
Do a count to prove it works.
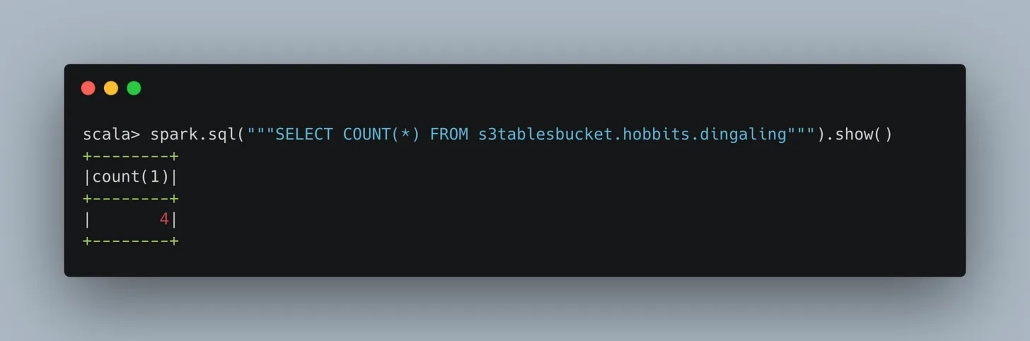
There you have it. It sucks that you can only use EMR or Spark to work with these S3 Tables, they really need support for more query engines like Pandas, DuckDB, Polars, Daft etc.
