AWS Lambdas. Useful for Data Engineering?

Are lambdas one of those tools that everyone uses and no one talks about? I guess I’ve taken them for granted over the years, even though they are incredibly useful. For a lot of my Data Engineering career I didn’t really think about or use AWS lambdas, I just saw them as little annoying flies on the wall, incapable of “real” use in Data Engineering pipelines.
But, I’ve changed my evil ways, and come to love the little buggers. Easy to use, cheap, and no infrastructure to worry about, I mean, they are little jewels in the rough.
I guess now that I look back and reflect, I’m surprised that I don’t see more content produced singing the praises and glories of AWS lambdas, why is the world silent? Those workhorses chug along in the background, millions and millions of times every second.
Today will not be earth-shattering, just a 10,000-foot view of AWS lambdas to inspire you to use them. With a focus on their use in Data Engineering.
AWS Lambdas – Introduction
The small but mightily AWS lambda, if you’ve used them before this is going to be boring, if not, stick around and I will give you the high level. AWS lambdas are the OG of serverless tools, they’ve been around forever and my best way of describing them is …
“Little peices of compute that run your code, that compute can be triggered by you or anything else for that matter. This compute is “small” and limited in size.”
AWS lambdas are little contained servers that run for a short amount of time, and then go away. The possibilities are infinite as to what you can do with them, they will run pretty much any code you can write.
Maybe it would be good to list a few of the features/limits of lambdas to help put them in perspective.
- There are pre-build lambda runtimes for Node, Python, Go, .NET, Java, and other binary packages.
- They max out at 10GB of memory (that’s the most you can use without getting an error).
- Lambdas can scale out really well (call them as much as you want, more will spin up).
- Lambdas max out at 15 minutes of runtime.
I suppose those are the most important ones. I guess one takeaway from that list is that they are like a little beehive, great at doing tons of little bits of work for you, quickly and efficiently without much infrastructure work. That’s the whole point of them.

Some technicals about AWS Lambdas.
This post isn’t really going to show you how to write lambdas, although I will point you to some good examples. I just want to give you the high level on writing and deploying lambdas, and leave the rest up to you. So, basically, I’m just going to give you another bullet list of technicals about lambdas.
- By default, the lambda runtime will call a function called
lambda_handler(). Aka this should be the entry point in your lambda code. - You can add many triggers that invoke a lambda itself.
- SNS Topic.
- S3 triggers.
- Event Logs.
- Trigger lambda via code.
- AWS CLI.
- etc.
- You can deploy your lambda runtime via a Docker image stored in ECS.
- Or via a binary executable.
- Or via pasting your code into the AWS Lambda Console.
- AWS provides base images and lambda runtimes for the above-mentioned languages.
Want to know more? I recently wrote about Rust and Python lambdas, here is the GitHub repo if you want to see examples of both.
Here is an example Python entry point to a lambda that is triggered by a file being created on S3.
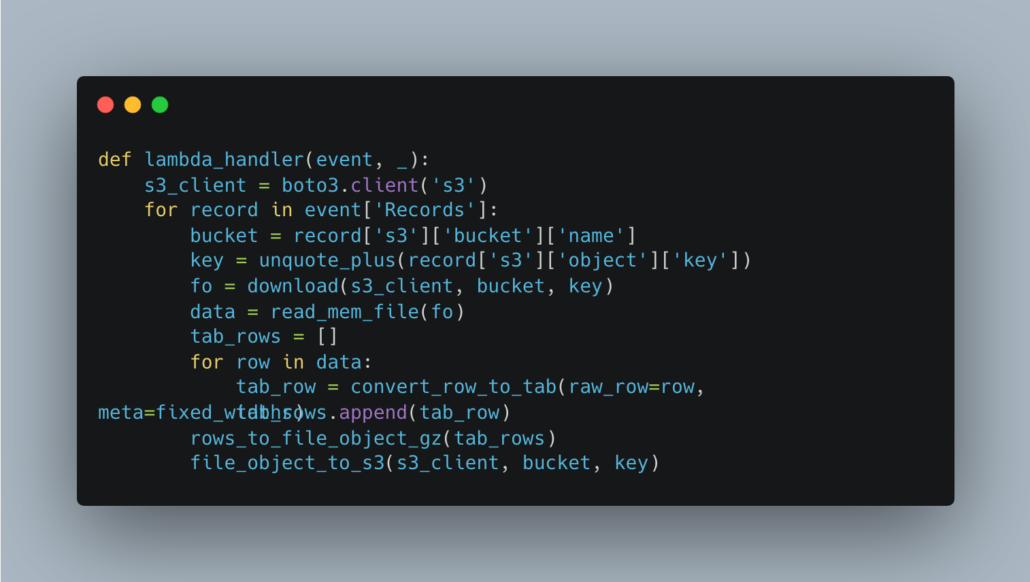
Practical AWS Lambda applications for Data Engineering.
I can only give my own experiences of how I’ve personally used AWS lambda for Data Engineering at my places of employment over the last few years, I’m sure there are plenty more, and I would be interested to hear what you’ve used them for!
Stepping back a bit, and thinking about the technicals of an AWS Lambda, there are certain problems that can arise when trying to use them for Data Engineering if you work in a “Big Data” environment, but not impossible. Many times Data Engineers can just throw the AWS lambdas out the window because of the 15 minute runtime and the 10GB max.
But, lambdas are awesome for Data Engineering if you just get a little creative. Probably one of the most common Data Engineering tasks across the industry is the processing of CSV and other flat files. This is a prime target for lambdas!
- Lambdas are a “cheap” way to pre-process CSV files and other flat files or ingest them into a Data Warehouse/Lake.
- Lambdas are “easy” infrastructure additions, you don’t have to manage much besides the code.
- Lambdas have easy deployments that can be automated.
Currently, I have AWS lambdas in production that are triggered by files hitting s3, they are Python lambdas that do various tasks like unpacking tar files, converting from fixed-width to tab etc. These are perfect use cases for Data Engineering, and they fit the lambda model perfectly.
Small distinct units of work, transforming and pushing data around. Lambdas don’t require a bunch of infa or architecture work, they are easy to write and deploy. They are a no-brainer.
What else could be done with lambdas? Think about all the little bits of Python that are running inside Airflow workers, for example, you will probably find a use case to migrate to AWS lambda.
I would be curious to hear from the readers what they use AWS lambdas for in a Data Engineering context?! Please comment below!
I think this is actually underselling them quite a bit. CDK makes working with lambdas (especially as a part of a larger system) extremely easy. You can package lambda code with them, and easily configure the entry point (the default for Python at least is just handler(), by the way), or Dockerize as you said and push that way. Although it requires some extra steps, it allows you to bypass some of the AWS limits in deployment size.
I use them (orchestrated with step functions) to run data processing steps for training computer vision models, and even serve model inferences for fractions of a penny. With a little creativity there’s a ton you can do with them that I feel like is either underexplored or undershared, at least within the AI world.
Yes Lambda is a very powerful service, recently it helped me with transferring GBs of data from OLAP to OLTP system within 5 mins, in this case we used the cuncurrency provided by lambda’s. We made use of the S3 trigger with multiple partitioned files dumped at the same time and then multiple cuncurrent lambda gets triggered according to number of files in S3 and all the files processed at the same time. This was really easy to setup and resolved a problem where OLTP Systems doesn’t work well with batch data where OLAP really works well with batch data.