AWS Lambdas – Python vs Rust. Performance and Cost Savings.

Save money, save money!! Hear Hear! Someone on Linkedin recently brought up the point that companies could save gobs of money by swapping out AWS Python lambdas for Rust ones. While it raised the ire of many a Python Data Engineer, I thought it sounded like a great idea. At least it’s an excuse to play with Rust, and I will take all those I can get. It does seem like an easy and obvious step to take in this age of cost-cutting that has come down on us all like that thick blanket of fog on a cool spring morning.
I can personally attest to the fact that I’ve written a number of Python AWS lambdas that are doing a non-trivial amount of data processing, currently running in Production and being triggered many times a day. Today, I’m going to reproduce both a Python and Rust lambda running on my personal AWS account doing pretty much the same exact work. Let’s see what the difference actually is in performance and see if it’s possible to find some cost savings.
What’s a real-life Data Engineering use of AWS lambda?
Rather consume this content as a video? Check out the corresponding video on YouTube.
So what is the use case for our AWS lambda we would be building in both Python and Rust? It’s going to be processing gzip flat-files from fixed-width to tab-delimited, with s3 as the source and s3 as the destination. Say we daily receive the bain of many Data Engineers fixed-width compressed flat files and we want to covert them to a more standard tab-delimited versions so we can have a common file type prior to ingestion into some Data Lake.
An AWS lambda is the perfect tool for this right? Simply trigger when a file hits s3, kick off a lambda, covert the file to what we want, and deposit the result back into another s3 location.
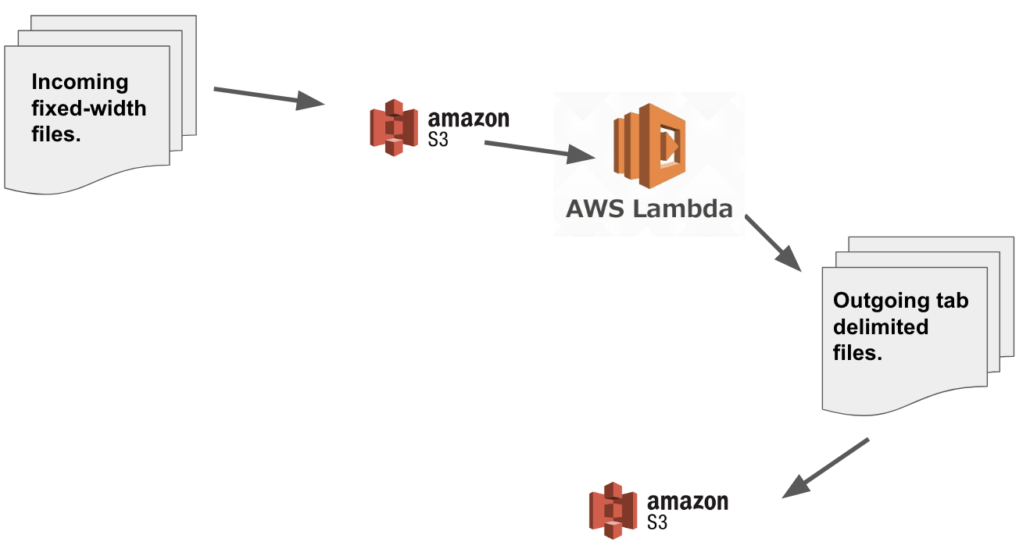
So to do this project, the first thing we are going to need is some flat files for testing, one fixed-width delimited and the other tab-delimited. We will use the Backblaze hard drive free dataset, taking one of those files and creating the two we need.
All this code is available, including the test file, on GitHub. If you are not familiar with fix-width files, just Google it. The data points are all found between an index range, so there is no “delimiter” for these files. It makes them a big pain to deal with, especially if downstream systems like Spark are supposed to ingest them. Very annoying.
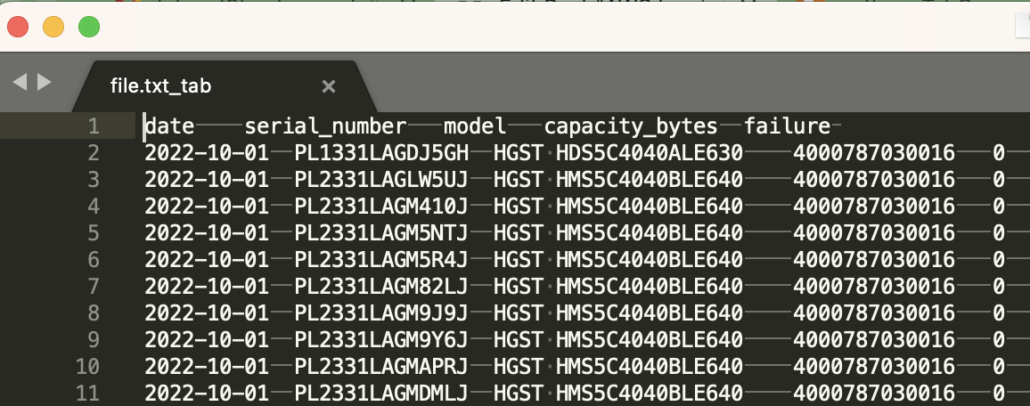
Here is a fixed-width delimited file I made from the above dataset.
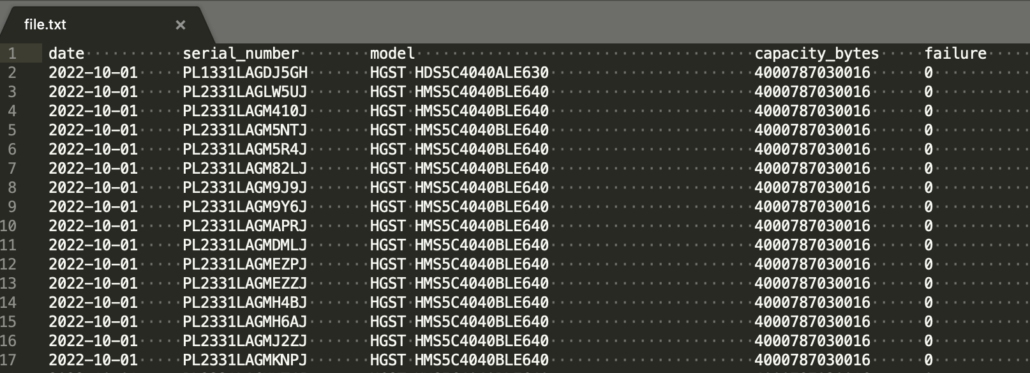
Let’s start with a 0index and define the fixed location of each column … as we will need this for both our Python and Rust lambda’s to parse the file.
start-end locations … (technically the location stops before the last number).
- date -> 0:15
- serial_number -> 15:36
- model -> 36:79
- capacity_bytes -> 79:98
- failure -> 98:109
Python lambda.
So, lambdas. They are pretty easy to work with on AWS, if you use the provided documentation you don’t really have much work to do besides swap out your code into the provided template(s). At a high level pretty much every lambda you design, unless you change it, by default uses a function called `lambda_handler()` as the single entry point into the lambda. Aka that is what your lambda is going to call when it triggers.
Our AWS lambdas are going to be triggered when our fixed-width file hits s3. Our lambdas are going to receive a message into the lambda_handler function that is going to contain the unique s3 remote uri of the file that just hit the bucket. That means both our Python and Rust lambdas are going probably to follow the same general workflow.

- get the s3 uri of the fixed-width file.
- download the file.
- convert fixed-width to tab-delimited.
- write the new file back out to
s3.
Let’s get cracking. All code is available on GitHub. You can use the aws cli to do all this, but for ease I just created the empty lambda’s via the UI.
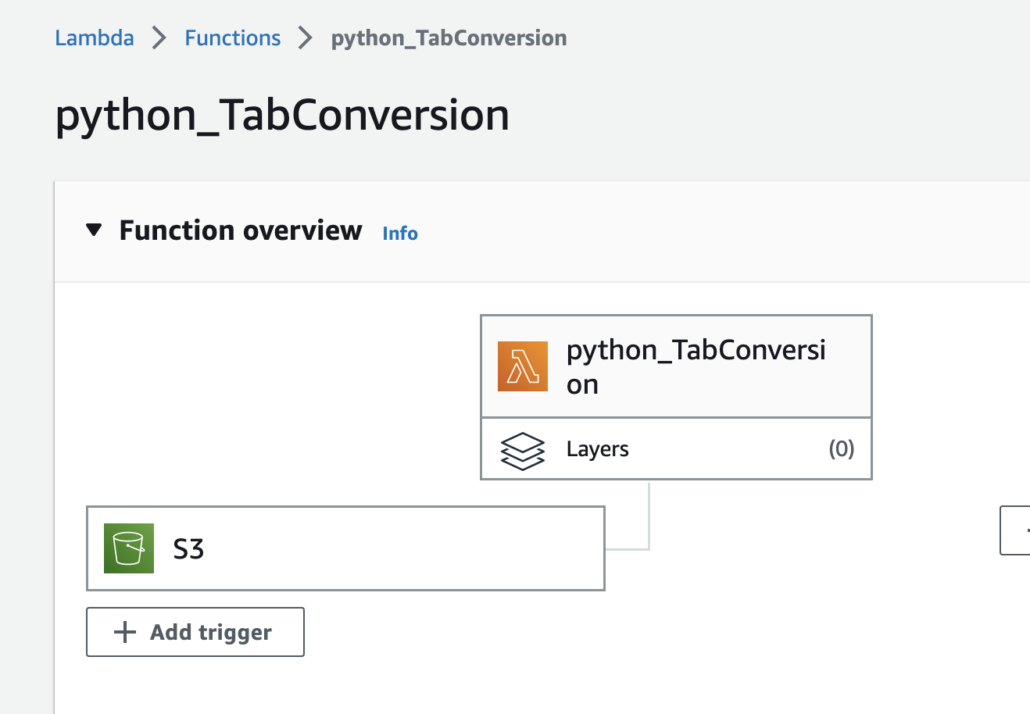
Python lambda to convert a fixed-width to a tab-delimited file, trigger on the s3 bucket to launch the lambda, and run the conversion. Don’t forget, the code is available on GitHub.
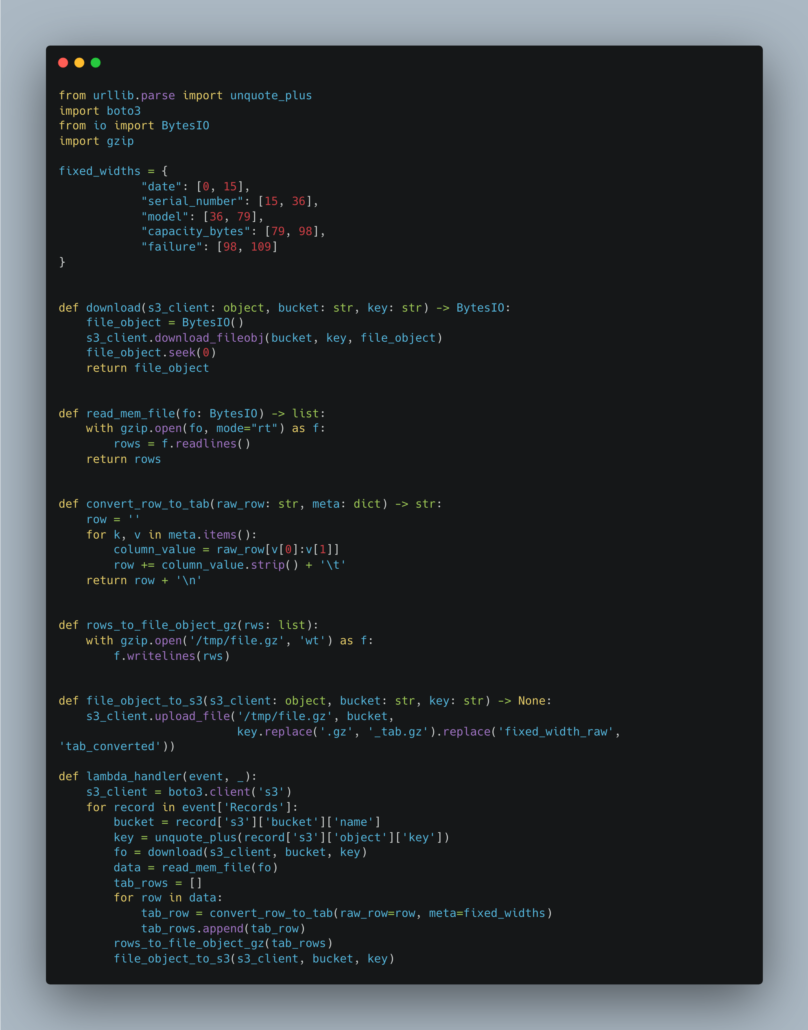
Works like a charm to convert the fixed-width file. One thing to note is how simple and straightforward the code is, easy to reason about and debug. Sure, people on the internet say that Rust in the long term has no more cognitive and developer burden than any other language, but we all know that is crap.
Readability affects your codebase. Python’s readability is better than most, and that’s why people use it. So, when we drop the fixed-with gzipped file into our s3 bucket, does the lambda work? Of course.
Here are some logs for AWS. Performance, aka runtime, and the amount of memory used.
*******UPDATE********
Due to numerous complaints here is the updated runtime for Python using LESS memory, 200MB max, instead of 350MB. This is closer to what was allocated to the Rust lambda. This of course made Python even slower.
REPORT RequestId: 63aed740-42dc-49a1-92e8-e41349bcdfdd Duration: 15698.93 ms Billed Duration: 15699 ms Memory Size: 200 MB Max Memory Used: 140 MB Init Duration: 260.43 ms
******UPDATE***********
REPORT RequestId: d8a7cae5-fb99-4e81-bc1a-fbb8a4fd646e Duration: 8361.76 ms Billed Duration: 8362 ms Memory Size: 350 MB Max Memory Used: 139 MB
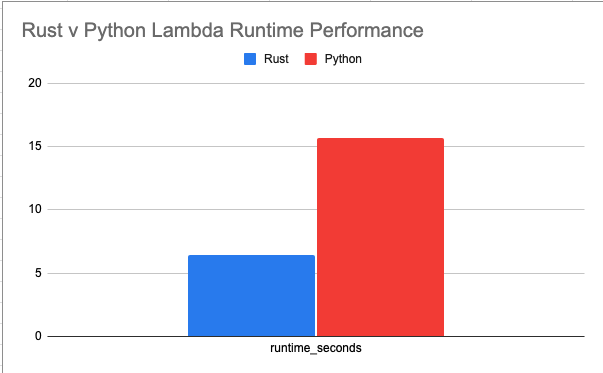
Yikes, that’s about 8.362 15.69 seconds! Slow Slow! Sure Python might not be perfect, but that’s life. There are 230,000records in this file, which are not very many. Most production files are much bigger. So you can imagine the runtimes on a few million records.
Let’s see what Rust can do.
Rust lambda.
So, I’m going to be looking for a few things here. I think it’s obvious that Rust is going to be faster … that’s a given. But how much faster, also will the memory usage be reduced if we try to write the Rust in the same way? I also want to know how much code in Rust this is going to take. How complex it will be.
The reality is that humans are human, if the Rust code is overly burdensome to write, Data Engineerings just won’t do it, regardless of the cost savings. They will just use Python and move on with life.
It’s one thing to re-write Python over to Rust, but in the real world, you have to have developers troubleshoot, debug, and write that code. If it’s twice the amount of code, sure it’s cheaper to run because it’s faster … but it might not be cheaper to maintain over time! Here are some Rust docs for lambda.
What I did was just copy the example lambda given in most of the AWS docs and ripped out the code, replacing it with mine.
Here is my ever-so-sad Rust code. Here are some things of note, use cargo-lambda to create and build the binary bootstrap.zip that you will need to actually create our AWS Lambda. Something like cargo lambda build –release –output-format zip
I promise someday my Rust will get better.
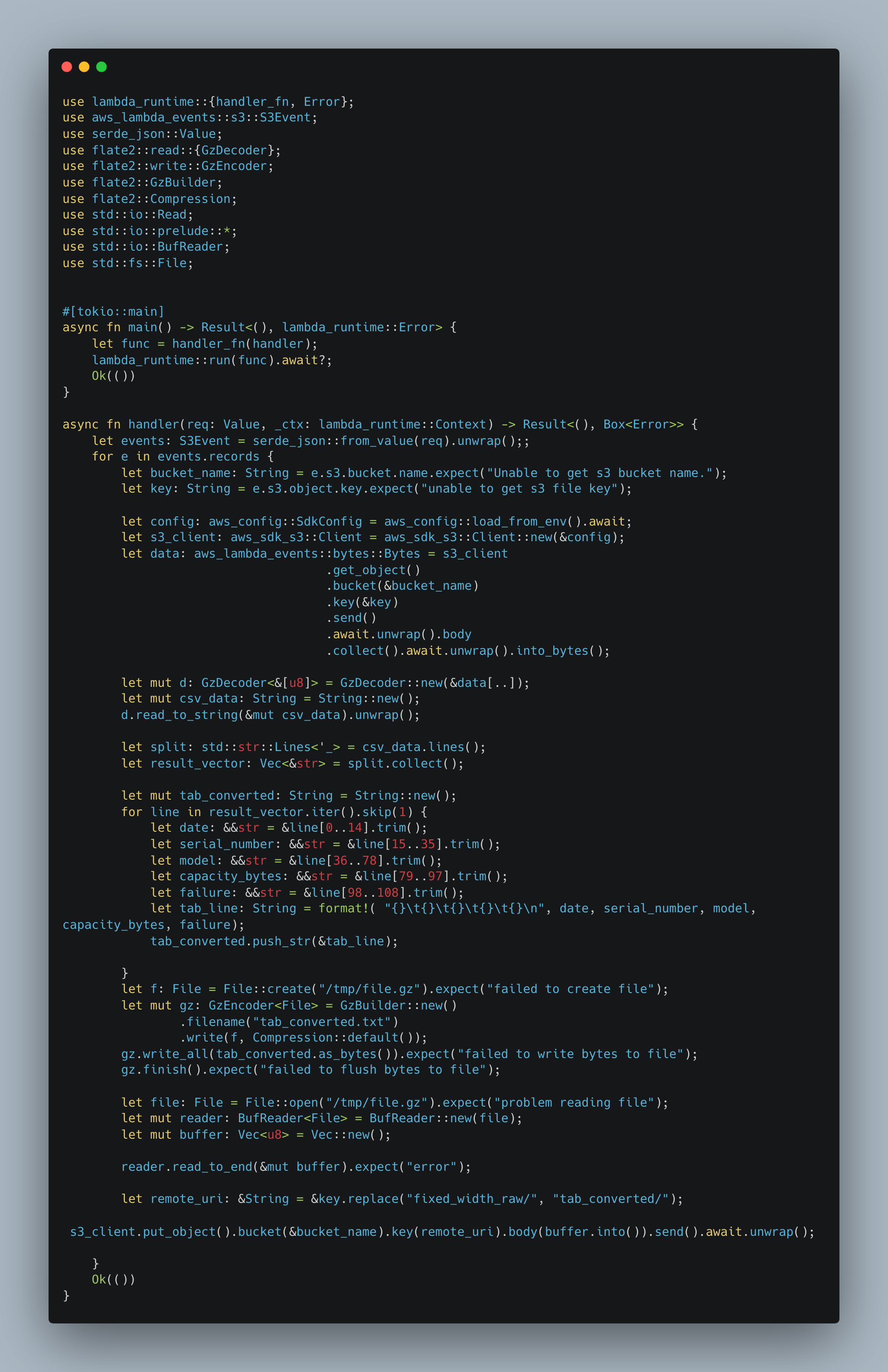
So of course my Rust is verbose and has more lines of code than Python, but that’s pretty much to be expected. Especially when I am writing it, only a few months into Rust. Honestly, though, the Rust isn’t really that much more complicated, it’s just the static typing that makes it look more complicated.
What about speed?
REPORT RequestId: ccf34808-00ae-47cb-81ef-3dc33d5a483e Duration: 6452.89 ms Billed Duration: 6491 ms Memory Size: 128 MB Max Memory Used: 85 MB Init Duration: 38.03 ms
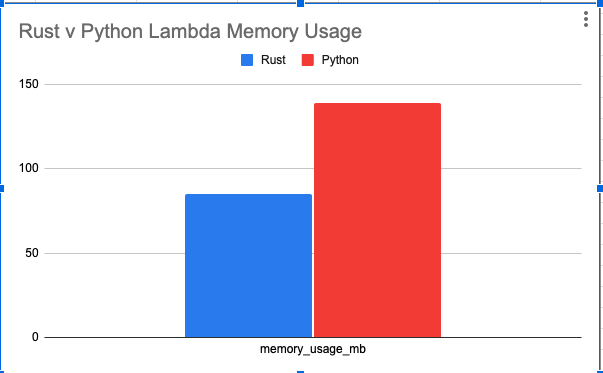
The Rust lambda is faster, clocking in around 6.452 seconds, vs Python’s 8.362 15.69, and uses less memory with 85MB vs Python’s 139MB. All of which adds up to cost savings. I do have to say, I thought the Rust lambda would run much faster. I mean, there is a high probability that my Rust is probably written not so well.
Rust is ONLY %60 percent faster on the runtime but uses %40 less memory as well. Let’s be honest, that is me a terrible Rust programmer simply migrating Python code to Rust, not even really trying. If you are running a large number of lambdas doing similar work in production, of course, you are going to save a noticeable amount of money.
AFAIK AWS scale cpu fraction linear with memory.
So when you allocate 350 MB memory for python, and 128 MB for rust, you allocate for rust not only 3 times less memory, but 3 times less cpu.
Jezz, nothing gets past you uh. I updated the code and the stats after re-running the test.
Since Lambda allocates CPU via its memory configuration parameter (which is surprising, but true), a more fair test would run both languages with the same Lambda memory configuration.
Good point, I did that and updated the specs. Rust is a lot faster now.
That last graph (performance bat graph) is terrible in terms of units. You used the same y-axis scale while both things have different units. The proper way would be to have two y-axis scales, one on the left and one on the right. The units should be on the y-axis, not in the name of the dataset. Because you used the same scale for both columns that have numerically no relation to each other, the performance bar is very small while there is no good reason to be that way. I really liked the rest of this post keep up the good work 👍
I updated the chart, now there are two. waala.
Is there any specific reason why you initialise the S3 client before the loop in python, and inside the loop for the rust version?
Looking at the code I would lean towards thinking that that is about 30-50% of the overall cost.
Also not sure why you hit the disk so many times if all of this could be done streaming?
Just because.
You seriously need to try this change though. My guess is it could give you another 5x to 10x Rust performance.
nice catch!
I would like to have seen this colored up a bit more. The article just kind of ends with the only conclusion being “If you are running a large number of lambdas doing similar work in production, of course, you are going to save a noticeable amount of money.” There is quite a bit of nuance that seems to be missing. For instance, the AWS Lambda free tier is 400,000 GB-seconds per month. At 200MB max memory, you’d get 2,000,000 free seconds. If each Lambda took 16 seconds, you could run it 125,000 times before you started having to pay for it. Since the test file was 25MiB expanded, that means over 3,000 GiB of data could be processed for free. For some applications, that volume of data in a month would be unrealistic.
I’d like to see a more concrete real-world example where the bottom line was something like “converting this Lambda from Python to Rust saved $X.”
Dude. Don’t rain on my parade.
The rust you’ve written has perf wins everywhere, for example, the events aren’t parallelized and you’re rebuilding the client in each iteration. It’s a multi-threaded language, make use of it.
Dude, it was for a blog, not real life. Besides it was like the 10th time I’ve written Rust in my life. Jeez.
How did the cold start times compare?
You can,see that fron the Init Duration. Rust already wins!
Hey, thanks for this! I’m new to both AWS and Rust, despite being in data-related positions for decades. Don’t mind the folks being curt with their feedback. I found the post helpful and informative, even if your Rust, like mine, is a little…rusty.
Hi Daniel, i really enjoyed your article. I wonder if you could optimize your Python using iterator instead of list.
Glancing over your GitHub code, I noticed that after unpacking your file you read it into into list. I would try yield instead.
Thank you for the interesting puzzle. I’ve been meaning to do rust-on-lambda for a while, and your code (provocatively I suspect, since the AWS rust docs you linked too had somewhat better setup) was just the bump I needed.
I note a few things: Python defaults to compression level 9. Rust’s GzEncoder defaults to 6. Thats 3 seconds on your dataset.
Secondly, the cargo-lambda lambda actual setup was rough. I spent way too long tracking down missing logging configurations after creating a new lambda by accident. Nothing to do with Rust per se of course.
With getting particularly exotic, I got the code down to 4.4 seconds (cold) with 35MB of RAM. It is on RAM usage that people tend to see significantly better behaviour from Rust in serialized algorithms.
REPORT RequestId: 318669fb-9427-49af-b843-ad9015f39c68 Duration: 46.59 ms Billed Duration: 47 ms Memory Size: 200 MB Max Memory Used: 35 MB
That said, here are my notes; the code is at https://github.com/rbtcollins/PythonVsRustAWSLambda/tree/tweaks
1) move main.rs to src/main.rs
allows rust analyzer in vscode to work without fiddling. If you haven’t used this, try it!
2) fix lints (cargo clippy will show, so will rust-analyzer)
warning: use of deprecated function `lambda_runtime::handler_fn`: Use `service_fn` and `LambdaEvent` instead
–> src/main.rs:1:22
right click on handler_fn; select ‘go to definition’, copy the content.
insert into main, look at it a little and then replace f with handler, and A with Value.
Cleanup the old code.
3) run cargo fmt. Rust has its own formatting tool, just go with it.
4) lift the s3 client outside the handler – it only depends on the env variables.
Move the config and client construction lines to main. Add a parameter to the
handler to accept the s3 client. Change the closure to pass in the client.
Because its a move closure, this takes ownership of the s3 client. To permit
lambda to call it many times, it must pass it into the handler; I chose to pass
a clone in as that is idiomatic with these API clients.
5) removed explicit types
Except at function boundaries and for functions like ‘collect’ that can return
many different types, Rust usually infers types very well.
6) Replaced the generic json Value with S3Event: I suspected the framework would
permit this as otherwise why would it permit a type parameter on the
LambdaEvent struct. This was the first risky thing, so I took the time after
this to build and test it in lambda.
made a new lambda, custom runtime, a2
wired up s3
cargo lambda build –release –arm64
cargo lambda deploy –iam-role …
which made a new lambda, then s3 configuration failed.
-> deleted the old lambda, retried
This then failed at
“`
START RequestId: 3781796c-9179-463a-951b-f2fe5389d93d Version: $LATEST
thread ‘main’ panicked at ‘byte index 78 is out of bounds of `2022-10-01 PL2331LAGLW5UJ HGST HMS5C4040BLE640 4000787030016 0`’, src/main.rs:57:26
END RequestId: 3781796c-9179-463a-951b-f2fe5389d93d
REPORT RequestId: 3781796c-9179-463a-951b-f2fe5389d93d Duration: 650.13 ms Billed Duration: 651 ms Memory Size: 128 MB Max Memory Used: 83 MB
“`
which shows it at least read the event and started processing, so we could move on.
7) converted expects to anyhow contexts; added anyhow as a dep and sorted imports
noticed that the code hardcodes the output folder, so added the folders to my test bucket.
At this point my lamdba started working properly.
Next up: give it speed.
8) stream the bucket into gz decoding. I hadn’t actually done that before, but the principle is pretty clear:
I want to read from the GZDecoder. So it needs to accept an impl Read that is backed by the bucket retrieval, and tokio has all the primitives to let us write this very simply.
This dropped time from ~7 to ~4.5 seconds (including startup).
9) move all the blocking computation logic up into the blocking section,
and remove temporary variables: process the iterator directly into the output string.
very little impact – but none was expected
10) gz compress to a vector in memory. Also change its compression level to match Python’s default of 9.
11) minor code golf
Forgot to mention: that time is on ARM
If it is 4.4s with 35mb of ram, how long it takes with 200mb? People are writing here that cpu allocation is proportional to ram.
Without detailed optimizations, would be nice to see how original code works with fixing two main issues – s3 client initialization in loop (hurts Rust) and different compression level (hurts Python).