
AWS Lambda + DuckDB + Polars + Daft + Rust
When it comes to building modern Lake House architecture, we often get stuck in the past, doing the same old things time after time. We are human; we are lemmings; it’s just the trap we fall into. Usually, that pit we fall into is called Spark. Now, don’t get me wrong; I love Spark. We couldn’t have what we have today in terms of Data Platforms if it wasn’t for Apache Spark.
The combination of Delta Lake as a storage layer and Spark as the processing layer is a match made in heaven that simply can’t be beaten. But, you will have to admit this is a very expensive way to run things.
We forget that it’s so easy to run a Databricks Job that we do it without thinking about the cost. We waste resources; we don’t take the time to consider our options and design the most efficient and cost-effective solution. We just reach and grab that same thing we’ve been grabbing for the last many years … Spark.
I’m hear to tell you not to be a data lemming.

There is a better way.
Rethinking data and how we ingest it into the Lake House.
What we need to do is be more creative, we need to take a pause and think about all the data that is …
- coming into our Lake House
- and leaving our Lake House
Many times this data is in bite sized chunks, it typically doesn’t come upon us all at once.

Instead of being people who can only reach for Spark, let’s reimagine the way we push data into our Lake House, like Delta Lake, and how we get data out. One great simple tool we can use that has very lost cost, overhead, and complexity is AWS Lambdas. The are the perfect tool for quickly and easily ingesting small-ish units of data in bite sized pieces.

If we combine AWS Lambda with Docker and AWS ECR (to store and package our lambda up into a single unit), we have the perfect development system. It’s never been easier to build a simple Docker image and push it up into AWS for use within an Lambda.

Easy peasy!
I have a number of GitHub repos for DuckDB, Polars, Daft, etc that show you all the code and have instructions included.
The code for interacting with something like Delta Lake using any tool like DuckDB, Polars, or Daft is super easy and straight forward. I even tested a 10 million record CSV file in s3, ingesting into a Delta Lake table. It only took 3 and half minutes!!!
As well, many of these tools, if you look through the code … are able to deal with both Unity Catalog Delta Tables, as well as the raw file URI to a unmanaged or standalone Delta Table.
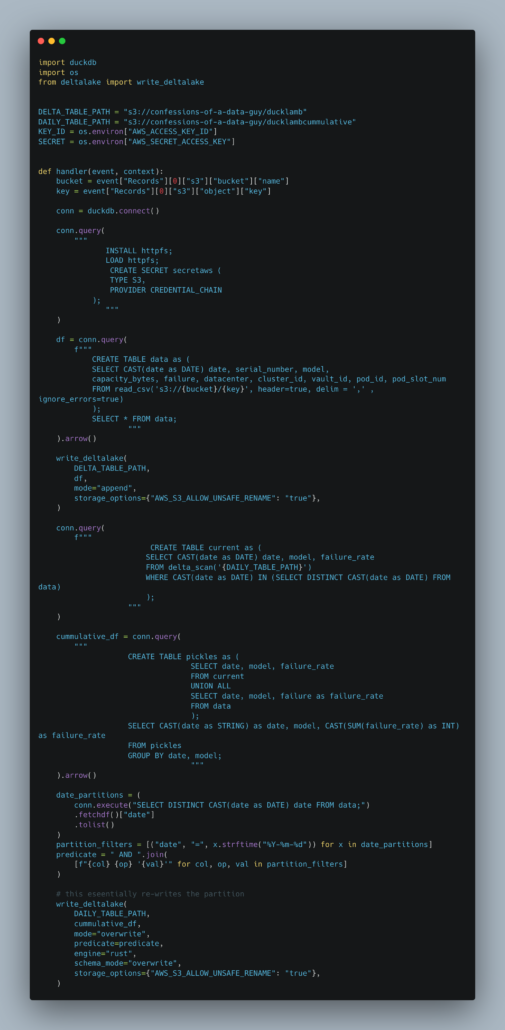
You can write complicated code if needed, like this DuckDB code.
Or simple like this Polars code.
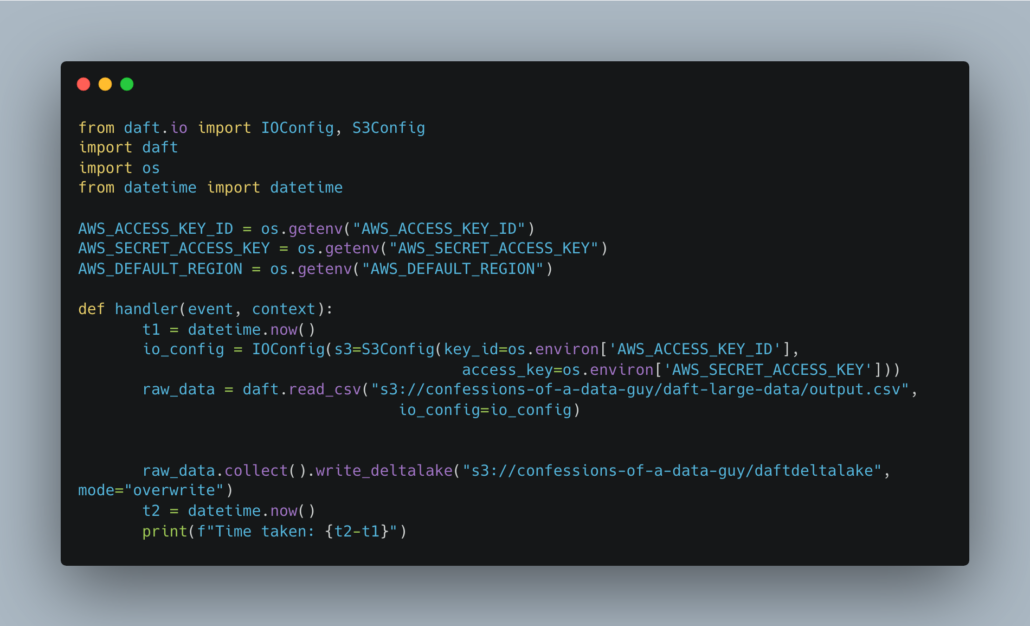
You simply don’t have to use Spark for EVERYTHING, use it where you need it, use something else where you DONT need it.
If you just think about working on your data in small chunks, with a lambda, you will save money and reduce complexity in your Data Stack. Sure, lambdas only run for 15 minutes and have a max memory limit of 10GBs , but how many times do you get files that are bigger than 10GB? Also, modern Rust based tools like Daft and Polars are super memory efficient and lazy in nature, with the ability to stream the data instead of pulling it all into memory at once.
