
Apache Spark’s Most Annoying Use Case
I still remember the good ole days when Apache Spark was fresh and hot, hardly anyone was using it, except a few poor AWS Glue and EMR users … Lord have mercy on their ragged souls. It’s funny how that GOAT of a tool went from being used by a few companies for extremely large datasets … to today’s world, with Databricks, where Pandas-sized data is crunched with Spark.
But, that one-size-fits-all approach to using Spark for everything … I number myself in those ranks … has its downsides. Namely, with the rise of PySpark and SparkSQL … we want to do Pythonic things with Spark.
I mean that is the story as old as time. Give me an inch and I will take a mile. This can be seen in one of the most annoying parts of using Apache Spark …
Writing to a single and named CSV file with Apache Spark.
Of course, we all know that Spark was made to write multiple files to support its distributed nature. Anyone familiar with Spark at a very basic level will know when you write datasets to disk, be it parquet, CSV, or whatever … you specify a directory location and get multiple files written to that spot.
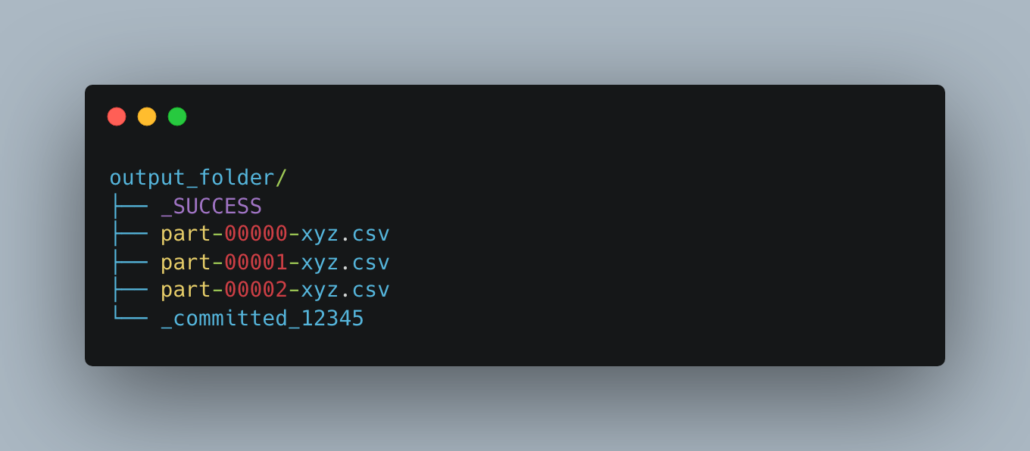
This creates a problem for PySpark users.
There is a way to be a wizard about it and use some HDFS black magic with Spark to obtain a single file with a specified name … but putting black magic aside, this distributed manner in which Spark writes files … and arguably is able to do what it does … is also one of the biggest pains for many data folk.
Writing to a single file in a specific location with PySpark.
This is the classic case of wanting to have your cake and eat it too. What can we say, humans are predictable creatures. Today, we are going to explore a few different options to get this done, writing a single CSV file with PySpark to a specified location … well, that’s sort of a lie, we won’t use Spark to do all the work.
First things first.
When you have a DataFrame in Spark and you want to eventually get those results into a single file on disk, say a CSV file, one would have to assume that dataset is small enough to fit into a reasonable amount of memory, otherwise, OOM will occur.
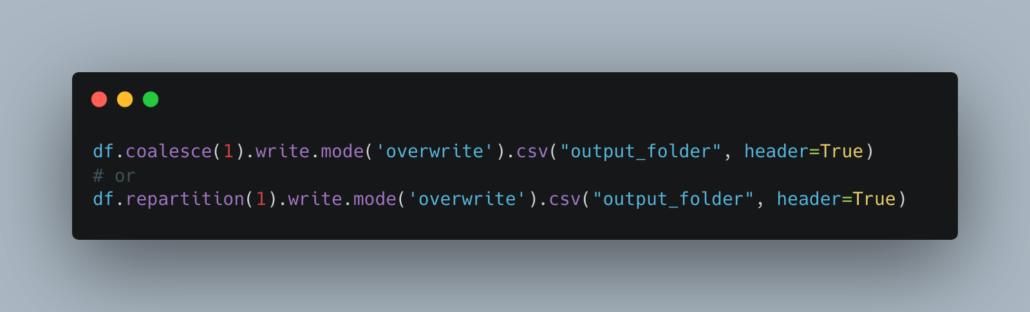
From this point forward you will have a single file to deal with, at the path you wanted, just without the name you wanted most likely. From here, there are myriad of ways to use Python or maybe a CLI to get what you really want. I file with a meaningless name, to one with something that makes sense.
Since there is really no one right way to do this, much depends on the use case. Say you want to get a single CSV file into s3 somewhere. Again, the fact that you want a single file assumes a small dataset, so maybe something simple like boto3 paired with pandas will do the trick …
like following …
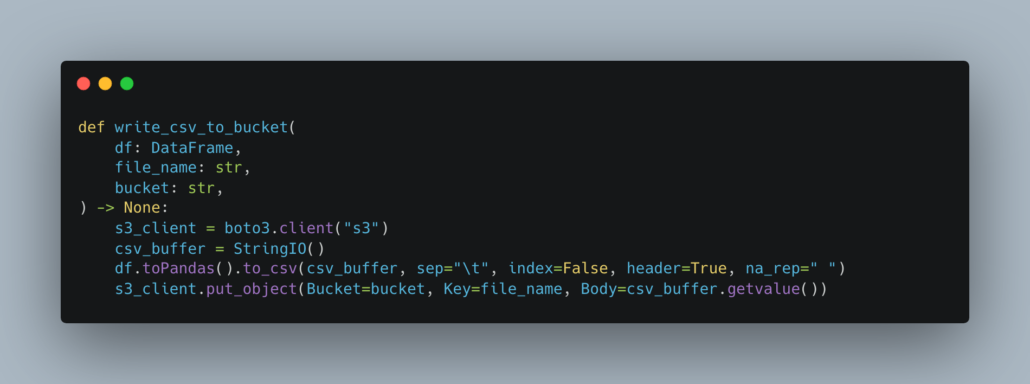
Easy enough eh? There is not much code, it is not overly complex, and it works like a charm.
What if you have some strange (probably warranted) hatred for Pandas and you want to let Spark do its thing writing out to a location and deal with the problem downstream? Of course, you could use boto3 in some process downstream if you know the relative location/path of that single CSV file.
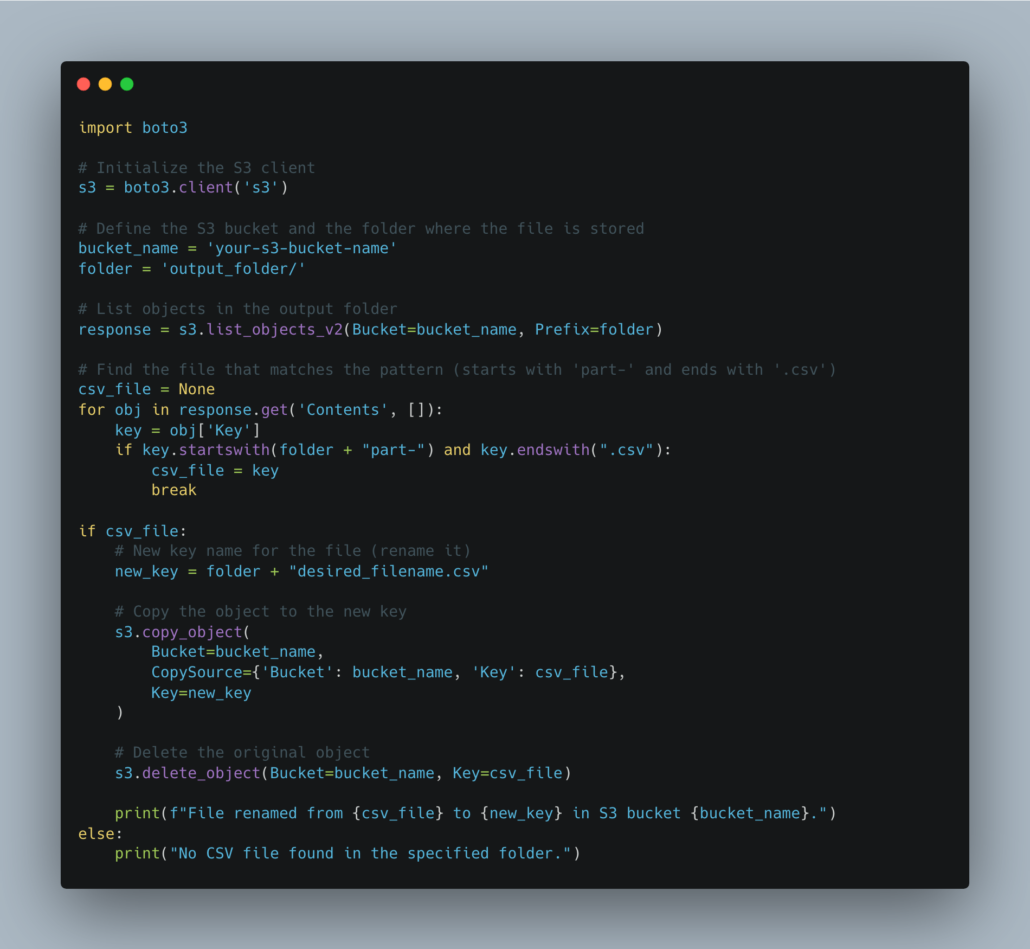
There is always the distinct possibility that you are an old-school Perl and Bash programmer and you insist on using Bash files and CLIs to do all your dirty work.
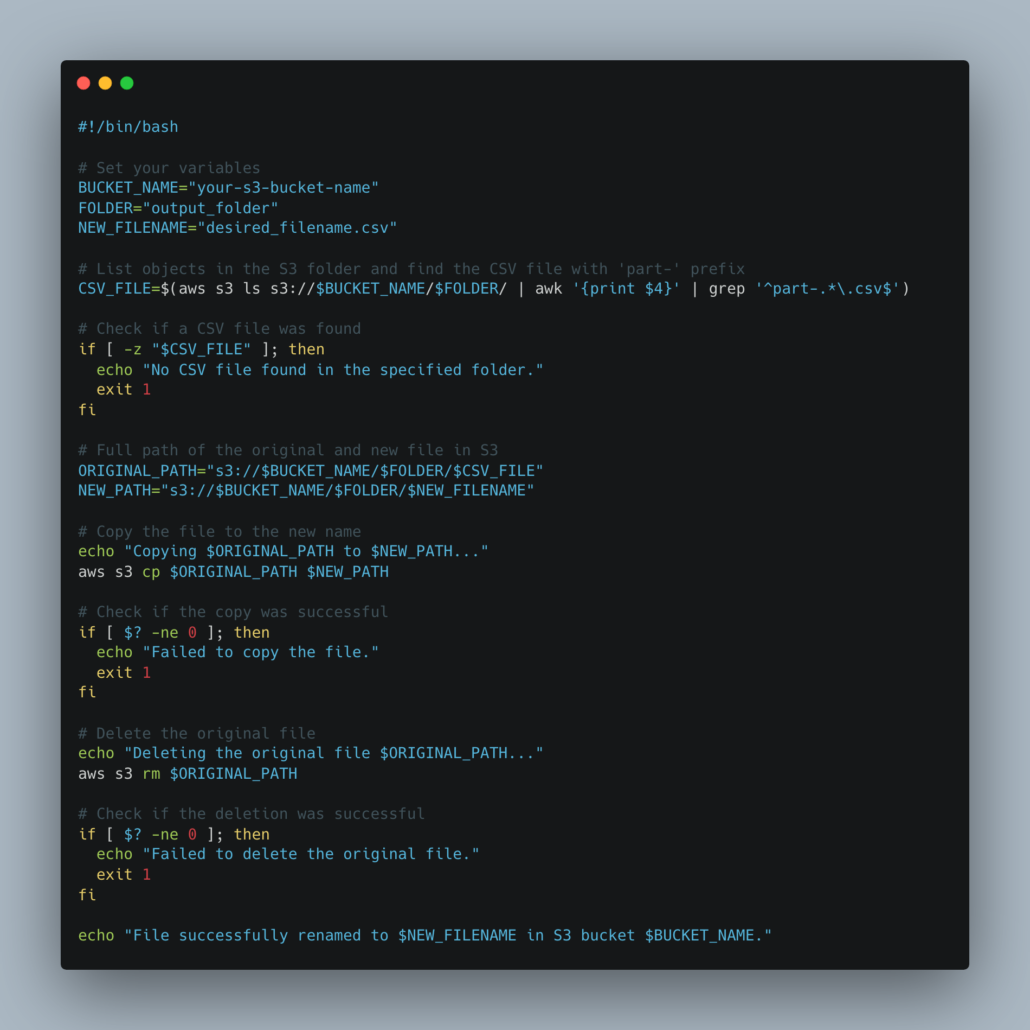
I mean there is a sort of beauty and rawness in using Bash with a CLI to string together something that someone later on will curse you dead bones for long after you’re gone.
And so, the story goes on. The age-old story. Here we are all these years later.
All us poor little PySpark uses want is just a built-in function to send a single file called what we want … where we want. Is that so much to ask for?
Maybe the Spark gods will bless this year but don’t hold your breath. Until then, just write some little Python method if you need something quick, if you’re feeling spicy make a Bash script to do it. A bad engineer never misses a chance to write more code, so have it!
