A Few Wonderful PySpark Features.

Just when I think it cannot get more popular, it does. I have to admit, PySpark is probably the best thing that ever happened to Big Data. It made what was once a myth, approachable to the average person. No need for esoteric Java skills, no more MapReduce, just plain old Python. Another amazing thing about Spark in general, and by extension PySpark, is the sheer amount of out-of-the-box capabilities. I wanted to dedicate this post to a few amazing and wonderful features of PySpark that make Data Engineering fun and powerful.
PySpark Features You Need To Be Using.
Let’s dive into some of my favorite features of PySpark, and talk about how cool they are and game-changers for traditional Data Engineering tasks. I’m a firm believer in the importance of learning the depth and breadth of the tools you use in your daily Data Engineering. The common pitfall is to get comfortable, and not be familiar with everything that your particular tool, in this case, PySpark, can offer you.
This leads to a lot of poor decisions and code. Tasks turn complicated when you don’t know some feature can do a thing in one line, you might choose to use a totally different tool for something that could easily be done by what you’re using. This all leads to over-complication, frustration, and general problems.
My advice? Learn to read documentation, take time to skim release notes for your tools, and skill documentation, becoming familiar with what’s available to you.

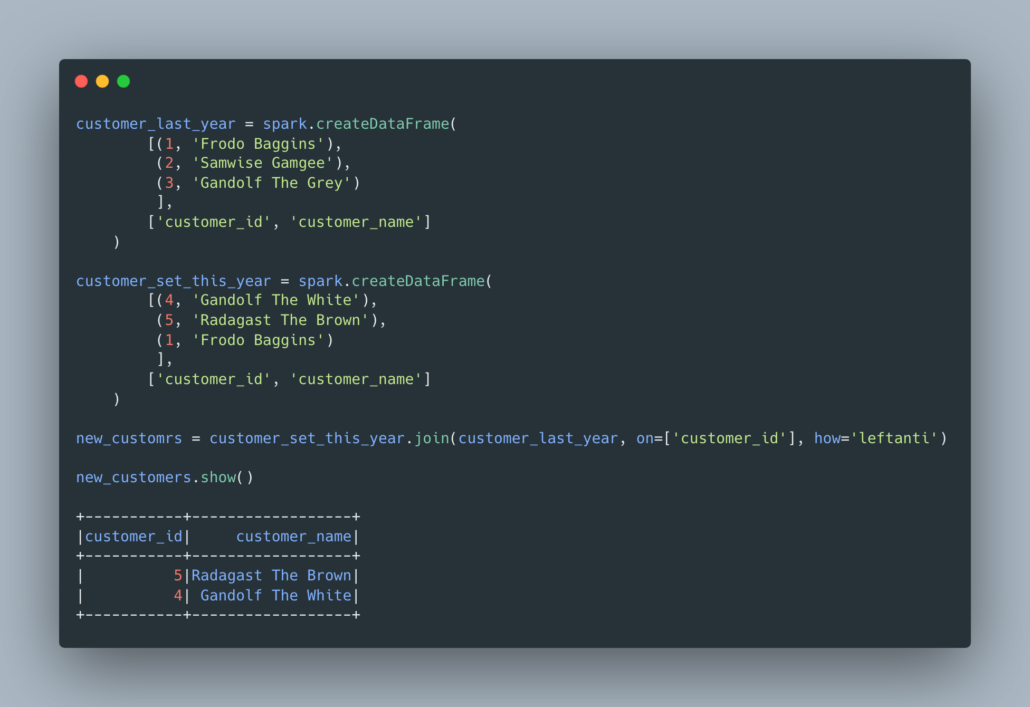
Here are some undervalued PySpark functions, and why.1. LEFT ANTI JOIN
This is one under-used by utterly useful feature.
“An anti join returns values from the left relation that has no match with the right. “
Such a common Data Engineering need. “I have two large datasets, how do I find the difference between them, or what’s in this one that is not in that one?” It can answer so many questions. I have customers from last year, and customers from this year, which are new customers? The best part, it’s just a simple one-liner, elegant.
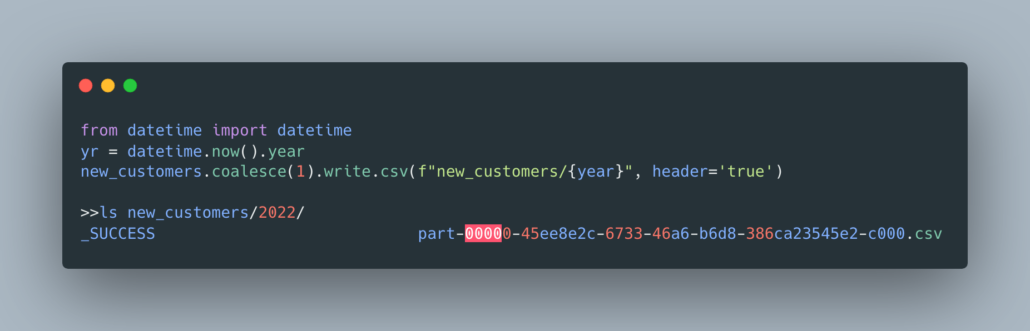
Another useful feature, not often used, but very important to the performance and with wide-ranging impact is the coalesce method of a DataFrame. Probably one of the most common issues beginners, or anyone, runs into when using Spark is the “many small files” issue. It’s incredibly common, especially when writing Spark datasets into cloud storage like s3 for folks to ignore the concept of partitions.
Simply put, coalesce will change the number of partitions in your dataset, depending on how many exist when you call the method.
“… if you go from 1000 partitions to 100 partitions, there will not be a shuffle, instead each of the 100 new partitions will claim 10 of the current partitions. If a larger number of partitions is requested, it will stay at the current number of partitions.”
How many times have I opened an s3 bucket to see some datasets written by Spark, only to find hundreds of thousands of tiny files? Too many to count. Added up over months and years, it turns into a real problem. Some simple math along with coalesce is the answer to this problem. Understand your data size, and partition accordingly. If you’re writing a few GB’s of data out, you don’t need 100 files.
For example, a common mistake I’ve seen is that some PySpark is used to crunch a dataset, the business asks for the results to be delivered at a CSV file, and someone converts the Spark DataFrame to Pandas and writes out a single CSV. Not realizing they can simply call coalesce(1) and receive a single CSV file.
I was reminded recently of the useful selectExpr function that for whatever reason, had fallen out of use for myself. Yet it is a wonderful way to consolidate logic and a concise and easy way. I’ve always found that reducing the amount of code written is the best solution usually, saying what you mean in the least lines possible, while still being readable, is always a win.
Let’s say I wanted to rename a column and cast it to a date. What would I normally do?
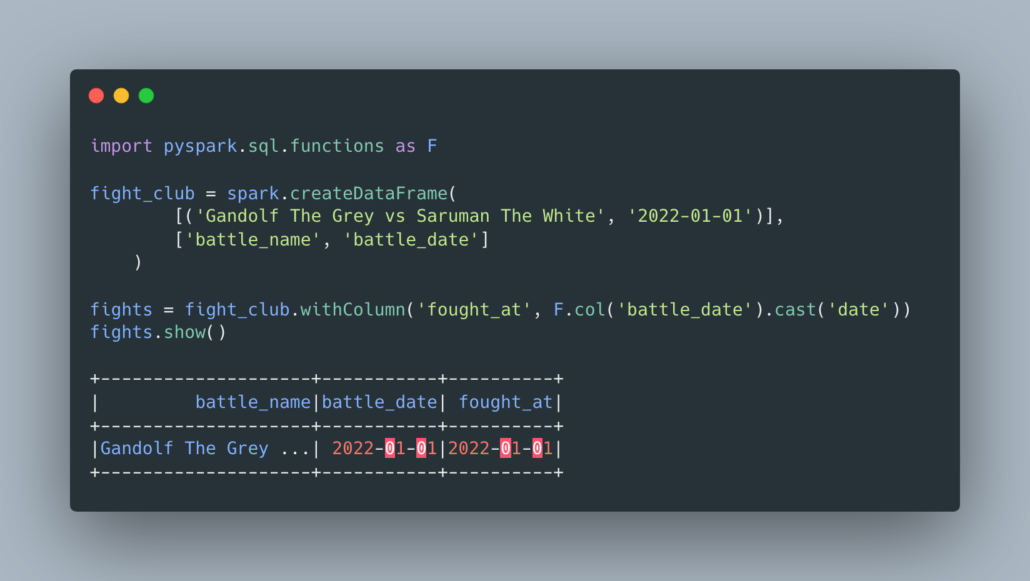
In the words of the Good Book, “there is a more excellent way”.
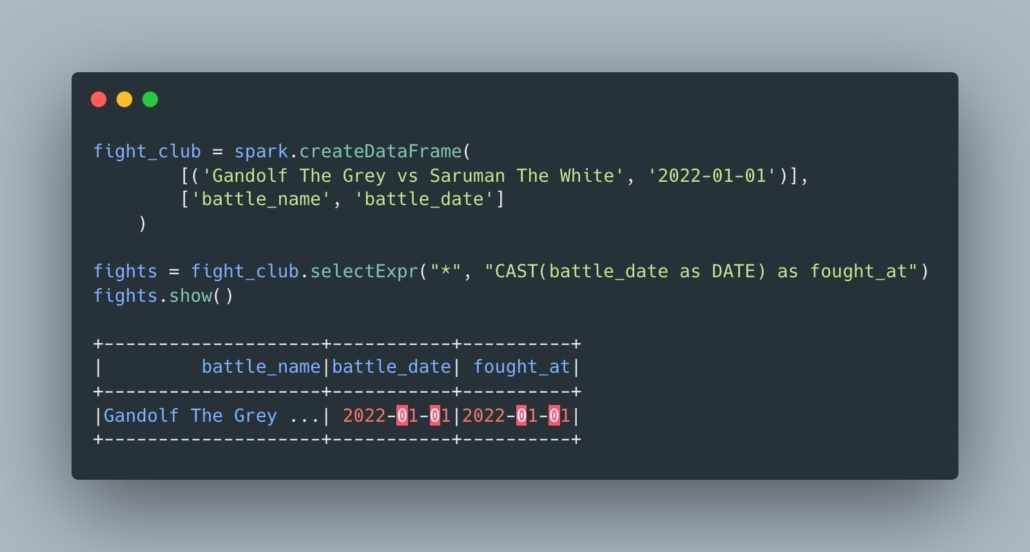
There is something oddly satisfying about being able to use SQL type expressions to do certain tasks. Maybe it’s the old Data Analyst in me reminding me from whence I came. Just imagine the possibilities with selectExpr though, the sky’s the limit.
Musings
I find it simply good practice and cathartic for my soul to try new things, and do something different than I normally would. It keeps one on the toes. Adding new tidbits of knowledge and features and functions to the memory bank is important, you never know when something is going to come in handy. “For such a time as this … ,” at some point that time is going to arrive, you will be ready.
Growth doesn’t have to be learning a new language. Sometimes growth and learning come from extending your knowledge and understanding of the tools you use every day.