Data Modeling – Relational Databases (SQL) vs Data Lake (File Based)

Data Modeling is a topic that never goes away. Sometimes I do reminisce about the good ol’ days of Kimball-style data models, it was so simple, straightforward, just the same thing for years. Then Big Data happened, Spark happened. Things just changed. There is a lot of new content coming out around Data Lakes and data modeling, but it still seems like a fluid topic, with nothing as concrete as the classic Data Warehouse toolkit.
Oh, what to do what to do. I do believe there are a few key ideas and points to being successful with file-based Data Lake modeling. I think it’s a mistake to fully embrace the classic Kimball-style Data Warehouse approach. It really comes down to Relational Database SQL vs File-Based data models are going to be different, for technical and practical reasons.
Data Models
Let’s talk about data models. Most data engineers have spent time designing data models, whether they are aware of it or not. Some don’t take it as seriously as they should, which is always a mistake as the downstream impact of poor data models will have a massive impact on data usability and accessibility.
What is data modeling generally?
“… the attempt to capture the data types, schemas, and inter-relationships between data points.”
– me
Data models are important because the tools that consume our big data … Spark, BigQuery, Athena, you name it, are going to be at the mercy of the data model in both a functional and performance manner.
Even a behemoth Apache Spark can be brought to its knees and rendered worthless before the throne of a bad data model.

Relational SQL Database vs File-Based – Data Model.
The differences between a classic relational database data model and the new Data Lake data model are somewhat obscure, but important and obvious once you observe them. I think understanding the differences between running a Data Warehouse on SQL Server and a Delta Lake on Databricks will be the golden key to the future that’s running us all down whether we like it or not.
First I’m going to show what the differences are, then I will explain them.
The Differences
- SQL Database models have myrid of dimensions, data normilization and de-duplication to the extreme.
- File-Based data models tend to have fewer dimensions and lookups, normilization in moderation.
- SQL Database models table size doesn’t matter much, small or big.
- File-Based data models table size AND file size matter in the extreme.
- SQL Database models are centered around indexing and indexes.
- File-Based data models are centered around partitions and partitoning.
Visually it might appear in such a form as follows. Simplistic but you get the point I assume.
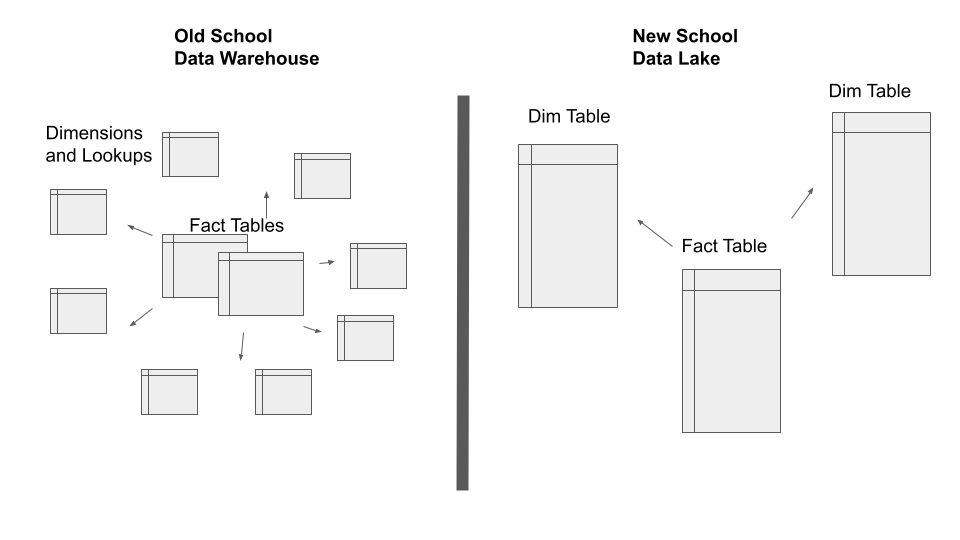
The number of Fact tables and Dimensions and normilzation.
This really just comes down to the technical implementation of say Postgres vs Apache Spark. The technology is just different, and of course, that is going to impact the data model in a large way, this isn’t really much you can do about it.
Relational SQL databases blazing fast and joining many small tables is no big deal. That’s typically why the classic Data Warehouse running on a SQL database had a look-up code and dimension for everything. Data deduplication and normalization were taken to the extreme in these data models … because they fit the technology.
The following queries are quite common in the classic data warehouse world.
SELECT fact.*, dim2.blah, dim3.blah, lookup1.blah, lookup2.blah
FROM fact
INNNER JOIN dim1 on fact.key = dim1.key
INNER JOIN dim2 on fact.key2 = dim2.key
INNER JOIN dim3 on fact.key3 = dim2.key
INNER JOIN lookup1 on fact.key4 = lookup1.key
INNER JOIN lookup2 on fact.key5 = lookup2.key
WHERE dim1.blah = x AND dim2.blah = y and lookup2.key = zWhile you COULD do the above in a Delta Lake environment, it’s not the way to get the best performance and usage of the new big data tools. There are a few reasons for this.
File size and table size matter in the new File-Based Data Lakes.
Most data engineering practitioners who’ve worked around Big Data and those tools like Hive, Spark, BigQuery, and the like will recognize that both small file sizes and small datasets can wreak havoc on those tools.
If you have 5 small-to-medium size datasets that have to be broadcast and joined with every single query in your Spark Delta or otherwise Data Lake … things probably are not going to work as you think. Technically most big data tools get slow when you start to include large numbers of small files or datasets that have to make their way across a distributed cluster network and disk that is behind those big data tools.
This wasn’t a big deal back in the SQL relational database days because very few systems required sharding and the data was sitting on a drive or two on a single machine. This is not the case in the big data Data Lake. Hundreds of terabytes of data can be scattered across many hundreds to thousands of nodes depending on workload size.
Partitions vs Indexes
Another major role in the data model differences between the new Data Lakes and the old Data Warehouses is partitioning vs indexes. The file-based Data Lakes are very much designed around the Partitions applied to the data, typically a minimum of some datetime series, and usually extending to other data attributes, like a customer, for example.
Because of the size of the data in the Data Lake file systems, it’s an absolute necessity that the data be “broken-up” aka partitioned according to one or more attributes in that data table. Otherwise, the data of that size cannot be queried and accessed in a reasonable timeframe. Think of entire scans running on every single file of a few hundred terabyte data sources, of course is not acceptable.
SQL relational databases on the other hand rely on primary and secondary keys to be able to seek, join, and filter the datasets quickly. The data models of classic relational databases are typically normalized, leading to many smaller tables with one or two large fact tables, typically designed around the primary key, or uniqueness value of a data set.
A typical Spark SQL query on a Data Lake might look as follows.
SELECT fact.*
FROM fact.{s3://location}
INNER JOIN dim1.{s3://location}
WHERE fact.date BETWEEN x AND Y AND fact.partition_key = x AND dim1.partition_key = yOf course, the above example is contrived but it’s obvious the difference in this query vs the relational database query. They will be different because the data models are different.
Walking the data model line bewteen old and new.
It’s a fine line. There are many attributes of the old school Data Warehouse that tried and true, tested for decades, that should be brought into the new Data Lake. What it comes down to is that it’s a fine line to walk. The differences in the technology stacks behind the scenes absolutely affect the data model.
We can all agree that modeling data as Facts and Dimensions is a tried and true way of organizing data for a Data Lake or Data Warehouse, the thought process around understanding what is a Fact table and what is a Dimension table enables high-value data models that can support a myriad of analytic use cases.
With file-based data models though, we cannot support a large number of small lookup and dimension tables, our big data tools will not respond well to such workloads. Whereas with a SQL relational data model, it would be foolish not to normalize the data to the extreme.
If file-based data models our data tables will be centered around and designed with Partition keys at the forefront. In file-based big data models, we don’t care about the size of large tables, the bigger the better. The tooling built around Data Lakes was MADE to work a the terabyte level and above. In our SQL relational models, we have to normalize the tables and break them up as much as possible in an effort to keep the data size from exploding.
Musings
In the end, understanding the data modeling differences between SQL relational databases and file-based data lakes starts with understanding the underlying technology. Postgres and Spark were made to do different things, the probability is that with JOINS and TABLES, and tooling like Delta Lake, we can be enticed to treat them the same way … which is a mistake. They might provide very similar functionality, but underneath is a very different set of principles.
Nice post! It will be nice to talk about Delta Lake with data skipping and bloom filters indexes versus SQL databases! For example with optimize and zorder we can reduce the small files problem, and with bloom filter indexes we can have a similar performance in some queries that works well in SQL databases and indexes. What do you think about replacing common datawarehouses as Redshift with a Lakehouse Delta Lake Databricks SQL?