How Hard Could It Be?

As someone who is self-taught when it comes to coding there are always topics that feel out of reach, or just plain magic. Also, as I’ve spent my career specializing in all things data, what I’ve needed to learn has always been very specific. Most of all, eventually the same old things become boring, time to try something new.
Enter concurrency and parallelism.
So, when I’ve run across these terms in the past my eyes and mind glaze over and I move onto something else. But, how hard could it be? Especially in Python.
So, apparently programs can be either CPU bound (try process pool) or IO bound (try thread), think of reading from disk or some difficult computation that makes the CPU spike.
That is where Threading and Process Pools come in. Since Python has a GIL, Process Pools can get around that by spinning up multiple Python processes that have their own memory space etc, but of course think of the overheard of doing that. Threading is supposed to be a more light weight option, especially in Python where only a single thread can run.
All this is still fuzzy in my head, and things didn’t go the way i expected, but here is what i tried.
I download 4 files csv files from Lending Club, just general lending data they provide for free. I wanted to read all four fairly large files and search every row to see if a person with “engineer” in their title was getting a loan. You would think engineers would be smart enough not to pay other people interest, but that’s another topic.
Now I figured this would be a perfect way to test the amazing speed of either threading and process pools. First I wrote a simple script to read the files one by one and print out every time it found someone with engineer in their title.
import glob import csv from datetime import datetime startTime = datetime.now() def find_title(column): if 'engineer' in column: print(column) def open_file(file): with open(file, 'r', encoding="utf8") as f: reader = csv.reader(f) for row in reader: if row[8]: find_title(row[8]) def iter_files(files): for f in files: open_file(f) def main(): files = glob.glob("*.csv") iter_files(files) print(datetime.now() - startTime) if __name__ == '__main__': main()
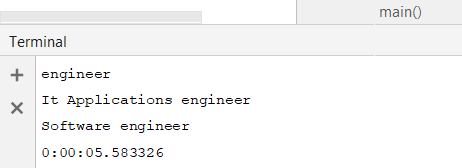
A little under 6 seconds. Seems pretty fast. I was very curious to see what would happen with a process pool. So spin up totally different python processes to run through each file. Seems like a good idea?
import concurrent.futures import glob import csv from datetime import datetime startTime = datetime.now() def find_title(column): if 'engineer' in column: print(column) def open_file(file): with open(file, 'r', encoding="utf8") as f: reader = csv.reader(f) for row in reader: if row[8]: find_title(row[8]) def main(): with concurrent.futures.ProcessPoolExecutor(max_workers=4) as executor: files = glob.glob("*.csv") for f in files: executor.map(open_file, files) print(datetime.now() - startTime) if __name__ == '__main__': main()
First off, I still don’t know what I’m doing, but that seemed super easy! Thank you import concurrent.futures ! ProcessPoolExecutor is the key, you can then map the executor your function and what you need processed.

Jezz. That was even faster than I expected. So fast I’m not even sure I was using it correctly. I changed the code to just print the file names, which it did, just to ensure everything was getting processed.
Ok, next onto threading. Super hard. All I did was swap out these lines.
with concurrent.futures.ProcessPoolExecutor(max_workers=4) as executor: with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
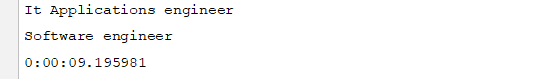
Ack. Well that was slow, even slower than the original file at a time script. This was pretty much the opposite of what I expected. I assumed the overhead of using Pools would be too much, and that the light weight threads would do better, especially for reading files. But, it must be that reading those csv files is easy, it was the parsing the rows looking for “engineer” that was the bottleneck for the app.
Get all the code here.