Testing and Development for Databricks Environment and Code.
Every once in a great while, the question comes up: “How do I test my Databricks codebase?” It’s a fair question, and if you’re new to testing your code, it can seem a little overwhelming on the surface. However, I assure you the opposite is the case.
Testing your Databricks codebase is no different than testing any other Spark codebase. In my opinion, the only difference is that you probably want to add the ability to test Delta Lake since most Databricks users combine Spark with Delta Lake as their storage layer.
I have written a few posts about unit testing with Spark; I suggest you read these posts if you have never unit-tested Spark code.
Introduction to Unit Testing with PySpark.
3 Tips for Unit Testing PySpark Pipelines
You will need a few things to be able to test your Databricks codebase.
- Dockerfile
- Docker Compose
- Know what Spark version and Delta Version you are using
- Modular Spark (PySpark) code that can be tested.
First you need a well put together Dockerfile, something like this probably. You will want to ensure you Spark version matches what your DBR version in Databricks is running, as well as figure out your Delta Lake version, although that is probably not that important for testing.
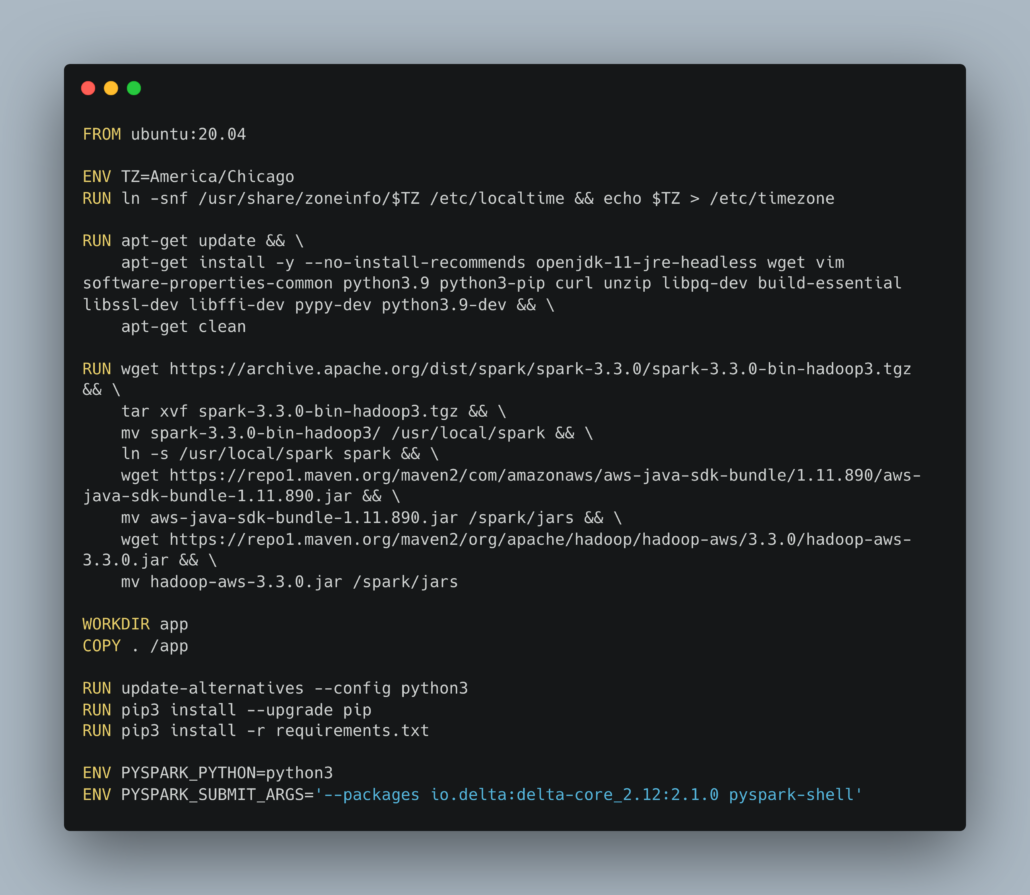
Also, some sort of Docker-compose that can help bind everything together and make it easy to run the test command would be helpful.
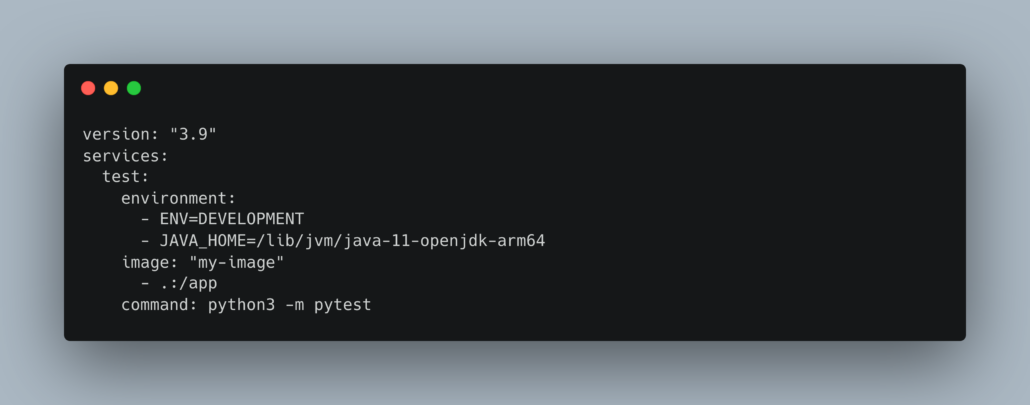
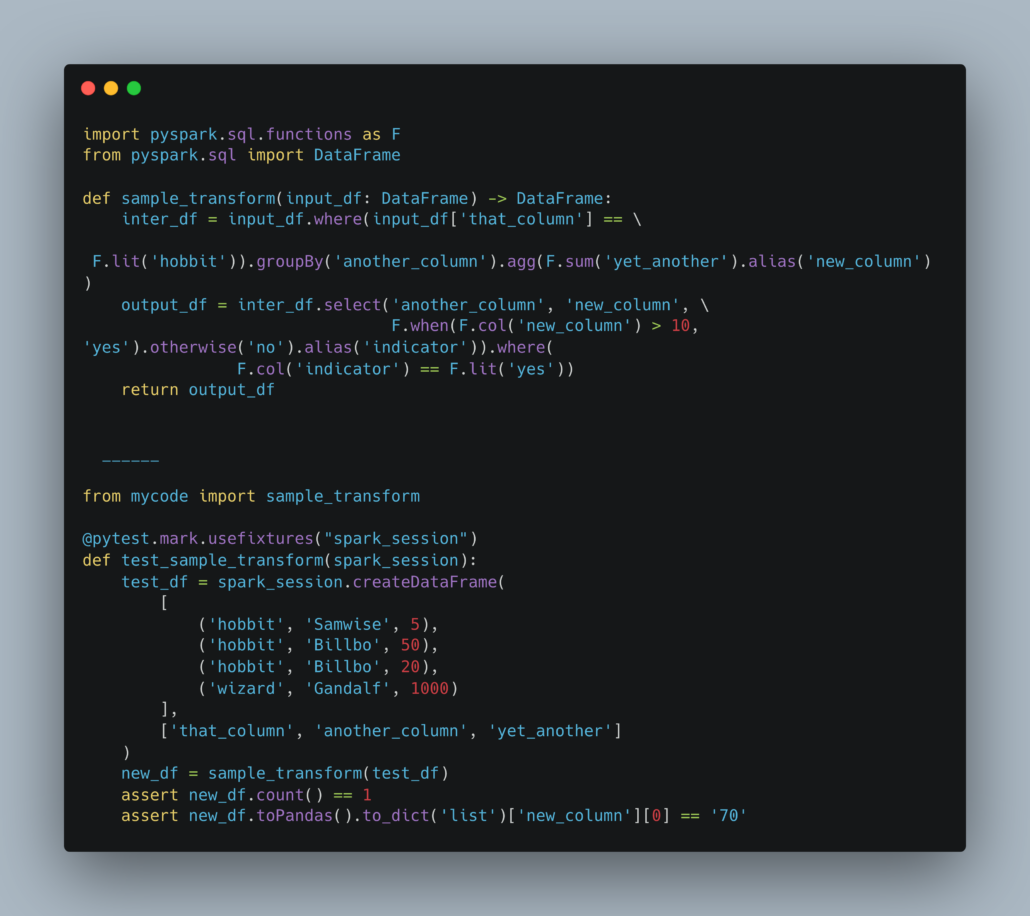
Of course at this point you would actually need PySpark code, or whatever, written in such a way is that it could be tested. This is one of the biggest downfalls of those people I see on Databricks. For some reason when people start using Databricks they start getting funny … thinking they need to write all the code in Notebooks, which is stupid because that typically means 99% of the time they can’t or don’t unit test.
Just modularize your PySpark code, INCLUDING SparkSQL and anything talking to Delta Lake tables.
Delta Lake tests aren’t much different.
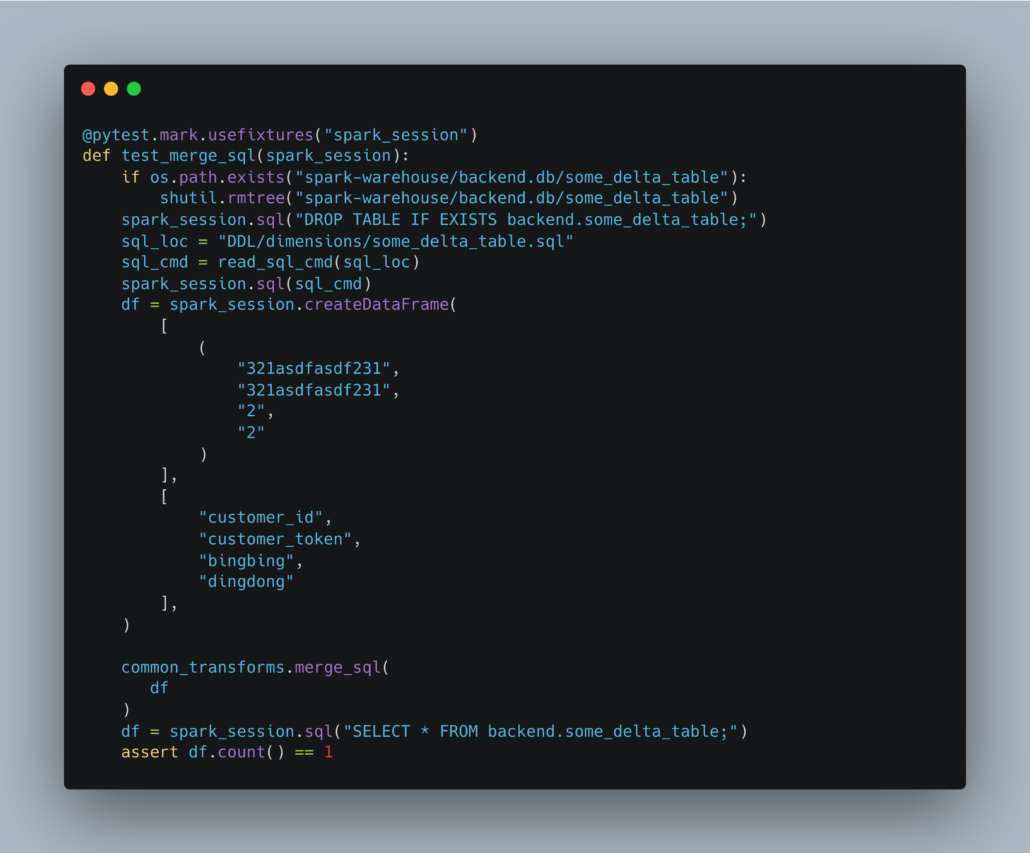
Well, you get the idea I think. It’s totally possible to unit test your Databricks codebase and automate those tests with some sort of CI/CD and DevOps when committing code to a repo.
What about integration tests?
Well, that’s a good question and the answer is just as easy, or not easy, depending your Databricks architecture.
Hopefully you setup your Unity Catalog and Databricks with …
- different Workspaces or Catalogs for Development vs Production
- different schemas between Dev and Prod
- some combination of above
If you have this sort of setup .. if not read my article I wrote for the Seattle Data Guy on this topic of setting up Unity Catalog that way.

Having this sort of Development vs Production will enable end-to-end or integration tests, this is not really a topic for this blog post and would require an in-depth dive into this sort of architecture and how one could set it up. It’s not rocket science though, you simply need …
- Separation of Development and Production through the entire stack
- A codebase that knows the difference between Dev and Production depending on where its running
If you have those two things it’s easy to have a Development Environment where you can deploy your Databricks codebase and run end-to-end tests of the entire system. Honestly, any Databricks setup that does not include these two things …
- the ability to run unit tests locally on the entire codebase
- the ability to deploy to Development Environment and run the entire set of pipelines …
… is a subpar setup that will only cause pain and suffering in the long term. You simply cannot have a bullet-proof and normal Development Life Cycle and Data Platform that isn’t breaking all the time without those two things, otherwise the only option to test something is to deploy to Production.
