Testing DuckDB’s Large Than Memory Processing Capabilities.
![]()
I am a glutton for punishment, a harbinger of tidings, a storm crow, a prophet of the data land, my sole purpose is to plumb the depths of the tools we use every day in Data Engineering. I find the good, the bad, the ugly, and splay them out before you, string ’em up and quarter them.
Today, for the third time, we put that ole’ Duck to the test. I want to test to see if DuckDB has fixed their OOM (Out Of Memory) errors on commodity hardware … that age old problem of “larger than memory data sets.”
DuckDB was unable to process larger than-memory datasets (OOM).
We’ve tested this very thing twice before, on commodity Linux Ubuntu server hardware. I mean, I’m all for playing games and piddling around on your laptop, but that’s for the NPCs. I want to test things in real life. What if I want to run DuckDB on medium-sized datasets in a Production environment (aka on a server) and not on a laptop? I need to be able to trust it can do simple things, things it claims it can do (like processing larger than memory than datasets).
I mean scalability is key when looking at new tools. All the Rust-based lazy tools like Daft, Datafusion, Polars, are able to process these larger-than-memory datasets. It’s a critical piece of functionality for real data tools.
This test, like before, is going to be incredibly simple.
We will get a small piece of commodity server in the form of a Linode. We will use a 2 or 4 GB RAM-sized server. We will then put a larger CSV file on s3, anything larger than the server memory size will do, and then run a simple aggregation query on top of that file.
DuckDB will either choke like it has done 2 times over the last year when we tested it, or it will finish. Of course, if you are skeptical, I can do that exact same thing with tools like Polars and Daft, and they can, and will, be successful.

We are going to use the wonderful datahobbit Rust based tool I built to generate a good-sized CSV file. I simply cloned this repo on the server and ran the following commands.
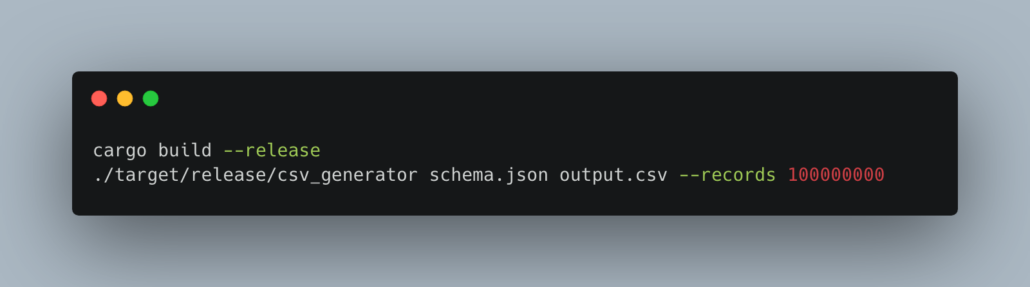 This gave us about an 11GB file.
This gave us about an 11GB file.
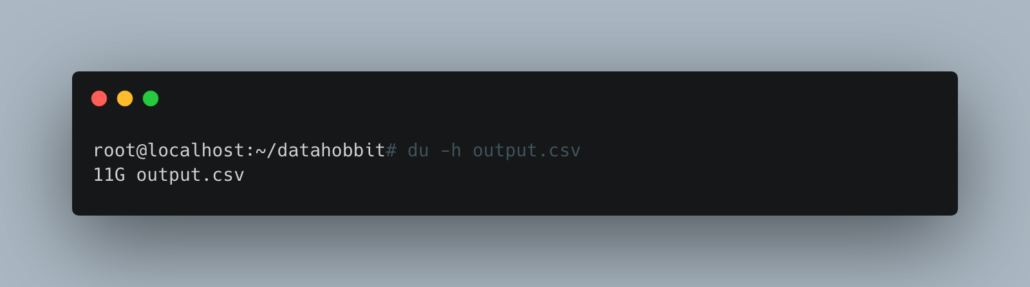
This is the perfect size to see if we can get DuckDB to process larger-than-memory (4GB) datasets.
Here is the simple DuckDB code.
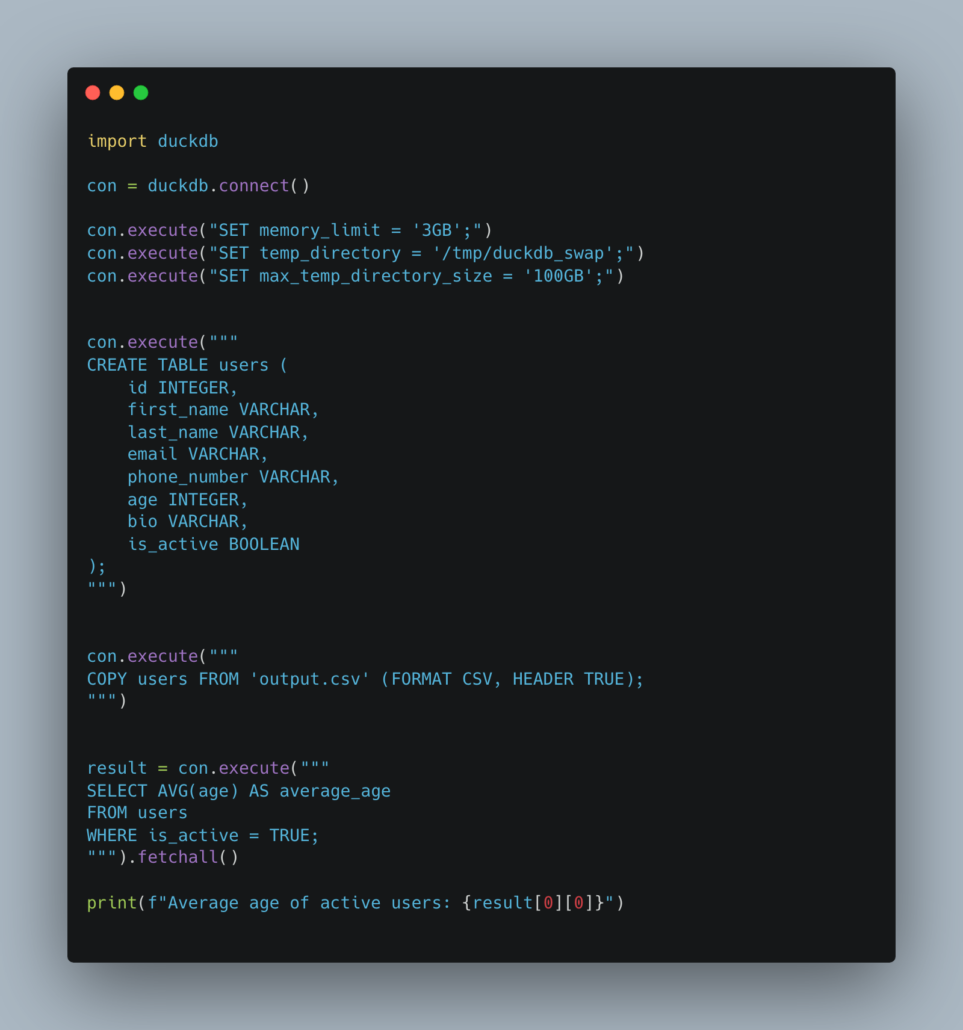
The results were good … in the sense that DuckDB was able to process that 11GB file on the 4GB machine.
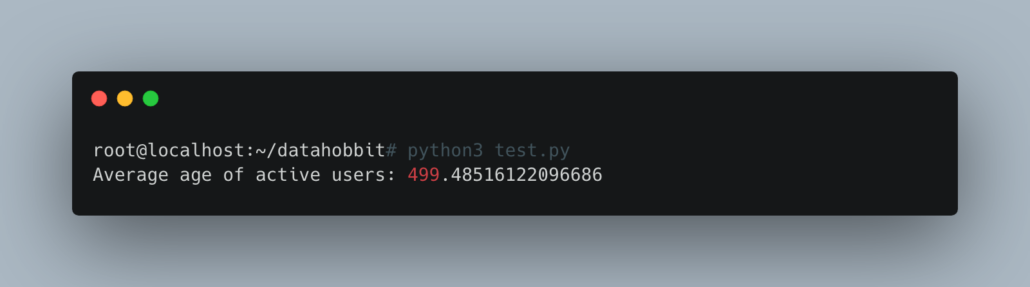
Nice to see this working well.