4 Ways To Setup Your Data Engineering Game.

One of my greatest pleasures in life is watching the r/dataengineering Reddit board, I find it very entertaining and enlightening on many levels. It gives a fairly unique view into the wide range of Data Engineering companies, jobs, projects people are working on, tech stacks, and problems that are being faced.
One thing I’ve come to realize over the years, working on many different Data Teams, and backed up by a casual observation of discussions on Reddit and other places, is that despite us living in the age of ChatGPT, Data Engineering teams generally seem to lag far behind in most areas of the Development Lifecycle.
So, to fix all the problems in the entire world and save humanity and Data Engineers from themselves, I give you the gift of telling you how to do your job. You’re welcome.
Stepping it up.
The longer I do Data Engineering, and life for that matter, I realize it’s the simple things that make a difference. I the beginning of my career I remember looking at those far above me, wondering how I could get such a giant brain and become a data and programming savant like them. Then I started to realize something, practice makes perfect, and it’s the little details that matter.
You can study DSA all day long, do LeetCode until you turn blue, and read every book and blog you can get your hands on, but all those things will leave you book-smart and real-life poor. I’ve met my share of CompSci Masters students unable to do basic tasks, I’ve met lifelong data practitioners who never grew and learned, stagnant, and I’ve met brand new programmers who seem to have the skill of someone with a decade more experience.
So what’s the deal?
Basic DE Skills to make you better.
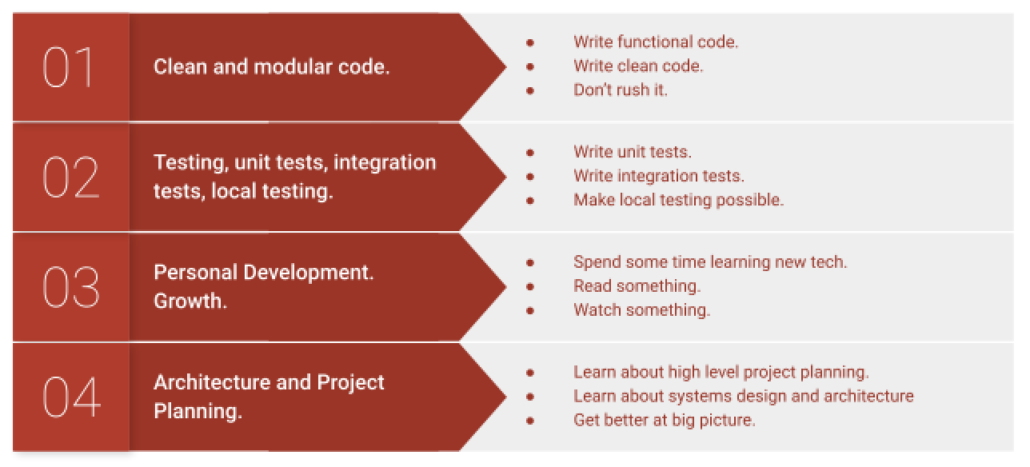
It can be hard, almost impossible, to come up with an all-inclusive list of skills that can “make you better” at Data Engineering. The list could be never-ending, and everyone will tell you which stuff you forgot to put on the list. But, this would be my list if I had to pick 4 pieces of advice to give a person coming into the Data Engineering world fresh as a daisy.
Why? Mostly because I think these things are doable for everyone, with no excuses, anyone can learn and practice these skills, and they are approachable.
Without further ado, I’m just going to go through them and then give you links to real techs, books, courses, whatever, to do them.
Clean and Modular Code

Photo by Samantha Gades on Unsplash
Writing clean, modular code is a fundamental aspect of any programming-related job, and data engineering is no exception. The best part about writing clean and modular code is that it makes the code easier to read, understand, test, and maintain. It also improves the quality of your output and allows you to work more efficiently.
This is massively underrated in Data Engineering, where it’s usually always high pressure and things are never “moving slow.” It’s easy to just bash out the code and move on with life, except that approach starts to accrue technical debt and ends up costing everyone more time and headache and re-writes down the road.
Clean code is simple, straightforward, and easy to understand. It contains meaningful names, and comments when necessary, and follows established coding standards and conventions.
Modular code is divided into smaller, manageable chunks or modules, each performing a distinct function. Modules are designed to be highly cohesive but loosely coupled, ensuring they can be reused and modified without affecting other parts of the codebase. Learning how to break down complex problems into simpler sub-problems will not only improve the modularity of your code but will also help in creating more efficient data pipelines.
Seriously, just take an extra 15 minutes to run your code through ChatGPT or CoPilot, take a second look, and do a quick refactor. This will make you a 10x engineer overnight and give you a solid reputation while building your skills. Here is some reading.
- https://medium.com/@fahdmekky/writing-clean-and-modular-code-eb1eb8bba87f
- https://levelup.gitconnected.com/12-top-tips-for-writing-clean-code-979255bd545a
Incorporate Testing into Your Development Workflow

Photo by Alvaro Reyes on Unsplash
Testing is vital in the software development life cycle and should be a core part of a data engineer’s skill set. By using different types of testing, you ensure your data processing workflows function as expected and are robust enough to handle unexpected scenarios. Testing will save you time, tears, fears, anger, and general mayhem later on down the road.
- Unit testing is the process of testing individual components of the code to validate each part works correctly. For data engineers, this might involve testing individual functions or modules within a data pipeline.
- Integration testing is the practice of testing how different parts of your system work together. For example, you might test whether your data processing script correctly interfaces with your database.
- Local testing refers to testing your code in your local development environment before pushing it to the production environment. It helps catch and fix bugs early and assures the quality of the code.
Embracing a culture of testing enhances the reliability of your data pipelines, reduces debugging time, and facilitates collaboration with other team members. Learn things like pytest, Docker, and Docker Compose. Ensure code is built in a way to handle multiple environments to enable testing in the cloud.
- https://www.confessionsofadataguy.com/3-tips-for-unit-testing-pyspark-pipelines/
- https://www.confessionsofadataguy.com/data-engineering-data-pipeline-repo-project-template-free/
- https://medium.com/interleap/intro-to-unit-tests-f2b7750c2d3c
The honest truth is, writing code that can be tested in the first place, unit or otherwise, will make your code better.
Commit to Continual Personal Growth

Photo by Jeremy Bishop on Unsplash
The tech world is in a state of constant evolution, with new tools and technologies emerging all the time. Data engineers must commit to lifelong learning to stay ahead of the curve.
One way to do this is by reading widely. Follow industry blogs, research papers, and relevant books. For more visual learners, video courses, webinars, and talks can be an excellent way to absorb new information. Websites like Coursera, Udemy, and LinkedIn Learning offer a range of relevant courses, many of them free.
Networking is also a crucial aspect of personal growth. Attend industry conferences, meetups, and workshops to learn from others and share your knowledge. Open-source projects provide opportunities to work on real-world problems and gain practical experience.
- https://newsletter.pragmaticengineer.com/
- https://pragprog.com/titles/tpp20/the-pragmatic-programmer-20th-anniversary-edition/
Learn about Architecture and Project Planning

Photo by Firmbee.com on Unsplash
A proficient data engineer understands the architectural principles underlying effective data management. This includes understanding how to design scalable, reliable, and efficient data processing systems.
Study the architecture of successful data platforms and systems. Familiarize yourself with concepts like data warehousing, data lakes, ETL (Extract, Transform, Load) processes, and real-time processing. Learn about different database management systems, both relational and NoSQL, and when to use each.
Project planning is equally important. Efficient planning helps set clear objectives, allocate resources wisely, and anticipate potential issues. Learn how to estimate timeframes, manage project risks
- https://www.confessionsofadataguy.com/my-journey-from-data-analyst-to-senior-data-engineer/
- https://dataengineeringcentral.substack.com/p/the-brittleness-problem-in-data-pipelines?utm_source=%2Fsearch%2Farchitecture&utm_medium=reader2
- https://dataengineeringcentral.substack.com/p/data-engineer-vs-senior-data-engineer?utm_source=%2Fsearch%2Farchitecture&utm_medium=reader2
The End
There you have it, all your life’s problems have been solved. Soon everyone will be bowing themselves before you in homage.