
Running dbt on Databricks has never been easier. The integration between dbtcore and Databricks could not be more simple to set up and run. Wondering how to approach running dbt models on Databricks with SparkSQL? Watch the tutorial below.
Running dbt on Databricks has never been easier. The integration between dbtcore and Databricks could not be more simple to set up and run. Wondering how to approach running dbt models on Databricks with SparkSQL? Watch the tutorial below.
There are things in life that are satisfying—like a clean DAG run, a freshly brewed cup of coffee, or finally deleting 400 lines of YAML. Then there are things that make you question your life choices. Enter: setting up Apache Polaris (incubating) as an Apache Iceberg REST catalog.
Let’s get one thing out of the way—I didn’t want to do this.
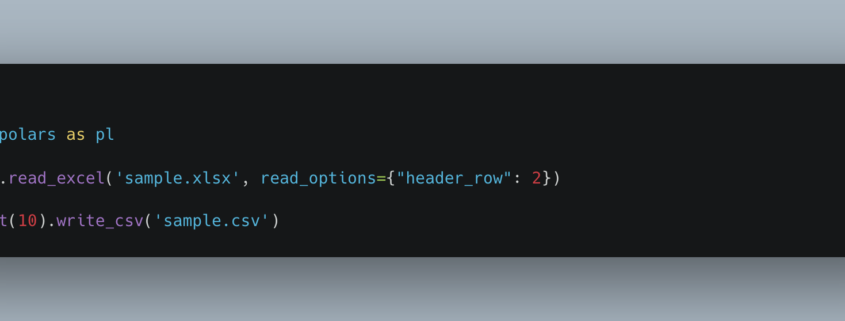
I make it my duty in life to never have to open an Excel file (xlsx); I feel like if I do, then I made a critical error in my career trajectory. But, I recently had no choice but to open an Excel on a Mac (or try) to look at some sample data from a client.

The post explores whether a Databricks environment—often used for Lakehouse architectures—benefits from dbt, especially if a team heavily uses SQL-based transformations.

The blog post reviews an Apache Incubating project called Apache XTable, which aims to provide cross-format interoperability among Delta Lake, Apache Hudi, and Apache Iceberg. Below is a concise breakdown from some time I spend playing around this this new tool and some technical observations: