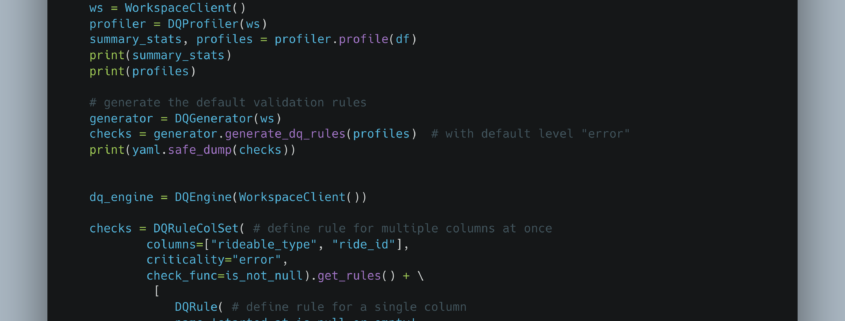
When it comes to building modern Lake House architecture, we often get stuck in the past, doing the same old things time after time. We are human; we are lemmings; it’s just the trap we fall into. Usually, that pit we fall into is called Spark. Now, don’t get me wrong; I love Spark. We couldn’t have what we have today in terms of Data Platforms if it wasn’t for Apache Spark.